






GDPR Compliance Failures Lead to Surge in Fines

In recent years, the landscape of data privacy and protection has become increasingly stringent, with regulators around the world cracking down on companies that fail to comply with local and international standards.
The latest high-profile case involves TikTok, which was recently fined a staggering €530 million ($600 million) by the Irish Data Protection Commission (DPC) for violations related to the General Data Protection Regulation (GDPR). This is a wake up call for multinational companies.
What is GDPR?
The General Data Protection Regulation (GDPR) is a data protection law that came into effect in the EU in May 2018. Its goal is to give individuals more control over their personal data and unify data protection rules across the EU.
GDPR gives extra protection to special categories of sensitive data. Both 'controllers' (who decide how data is processed) and 'processors' (who act on their behalf) must comply. Joint controllers may share responsibility when multiple entities manage data.
Who Does the GDPR Apply To?
GDPR applies to both EU-based and non-EU organizations that handle the data of EU residents. The regulation requires organizations to obtain clear consent for data collection and processing, and it gives individuals rights to access, correct, and delete their data. Organizations must also ensure strong data security and report any data breaches promptly.
What Are Data Subject Access Requests (DSARs)?
One of the core rights granted to individuals under GDPR is the ability to understand and control how their personal data is used. This is made possible through Data Subject Access Requests (DSARs).
A DSAR allows any EU resident to request access to the personal data an organization holds about them. In response, the organization must provide a comprehensive overview, including:
- What personal data is being processed
- The purpose of processing
- Data sources and recipients
- Retention periods
- Information about automated decision-making
Organizations are required to respond to DSARs within one month, making them a time-sensitive and resource-intensive obligation, especially for companies with complex data environments.
What Are the Penalties for Non-Compliance with GDPR?
Non-compliance with the General Data Protection Regulation (GDPR) can result in substantial penalties.
Article 83 of the GDPR establishes the fine framework, which includes the following:
Maximum Fine: The maximum fine for GDPR non-compliance can reach up to 20 million euros, or 4% of the company’s total global turnover from the preceding fiscal year, whichever is higher.
Alternative Penalty: In certain cases, the fine may be set at 10 million euros or 2% of the annual global revenue, as outlined in Article 83(4).
Additionally, individual EU member states have the authority to impose their own penalties for breaches not specifically addressed by Article 83, as permitted by the GDPR’s flexibility clause.
So far, the maximum fine given under GDPR was to Meta in 2023, which was fined $1.3 billion for violating GDPR laws related to data transfers. We’ll delve into the details of that case shortly.
Can Individuals Be Fined for GDPR Breaches?
While fines are typically imposed on organizations, individuals can be fined under certain circumstances. For example, if a person is self-employed and processes personal data as part of their business activities, they could be held responsible for a GDPR breach. However, UK-GDPR and EU-GDPR do not apply to data processing carried out by individuals for personal or household activities.
According to GDPR Chapter 1, Article 4, “any natural or legal person, public authority, agency, or body” can be held accountable for non-compliance. This means that GDPR regulations do not distinguish significantly between individuals and corporations when it comes to breaches.
Specific scenarios where individuals within organizations may be fined include:
- Obstructing a GDPR compliance investigation.
- Providing false information to the ICO or DPA.
- Destroying or falsifying evidence or information.
- Obstructing official warrants related to GDPR or privacy laws.
- Unlawfully obtaining personal data without the data controller's permission.
The Top 3 GDPR Fines and Their Impact
1. Meta - €1.2 Billion ($1.3 Billion), 2023
In May 2023, Meta, the U.S. tech giant, was hit with a staggering $1.3 billion fine by an Irish court for violating GDPR regulations concerning data transfers between the E.U. and the U.S. This massive penalty came after the E.U.-U.S. Privacy Shield Framework, which previously provided legal cover for such transfers, was invalidated in 2020. The court found that the framework failed to offer sufficient protection for EU citizens against government surveillance. This fine now stands as the largest ever under GDPR, surpassing Amazon’s 2021 record.
2. Amazon - €746 million ($781 million), 2021
Which leads us to Amazon at number 2, not bad. In 2021, Amazon Europe received the second-largest GDPR fine to date from Luxembourg’s National Commission for Data Protection (CNPD). The fine was imposed after it was determined that the online retailer was storing advertisement cookies without obtaining proper consent from its users.
3. TikTok – €530 million ($600 million), 2025
The Irish Data Protection Commission (DPC) fined TikTok for failing to protect user data from unlawful access and for violating GDPR rules on international data transfers in May 2025. The investigation found that TikTok allowed EU users’ personal data to be accessed from China without ensuring adequate safeguards, breaching GDPR’s requirements for cross-border data protection and transparency. The DPC also cited shortcomings in how TikTok informed users about where their data was processed and who could access it. The case reinforced regulators’ focus on international data transfers and children’s privacy on social media platforms.
The Implications for Global Companies
The growing frequency of such fines sends a clear message to global companies: compliance with data protection regulations is non-negotiable. As European regulators continue to enforce GDPR rigorously, companies that fail to implement adequate data protection measures risk facing severe financial penalties and reputational harm.
In the case of Uber, the company’s failure to use appropriate mechanisms for data transfers, such as Standard Contractual Clauses, led to significant repercussions. This situation emphasizes the importance of staying current with regulatory changes, such as the introduction of the E.U.-U.S. Data Privacy Framework, and ensuring that all data transfer practices are fully compliant.
How Sentra Helps Organizations Stay Compliant with GDPR
Sentra helps organizations maintain GDPR compliance by effectively tagging data belonging to European citizens.
When EU citizens' Personally Identifiable Information (PII) is moved or stored outside of EU data centers, Sentra will detect and alert you in near real-time. Our continuous monitoring and scanning capabilities ensure that any data violations are identified and flagged promptly.

Unlike traditional methods where data replication can obscure visibility and lead to issues during audits, Sentra provides ongoing visibility into data storage. This proactive approach significantly reduces the risk by alerting you to potential compliance issues as they arise.
Sentra does automatic classification of localized data - specifically in this case, EU data. Below you can see an example of how we do this.

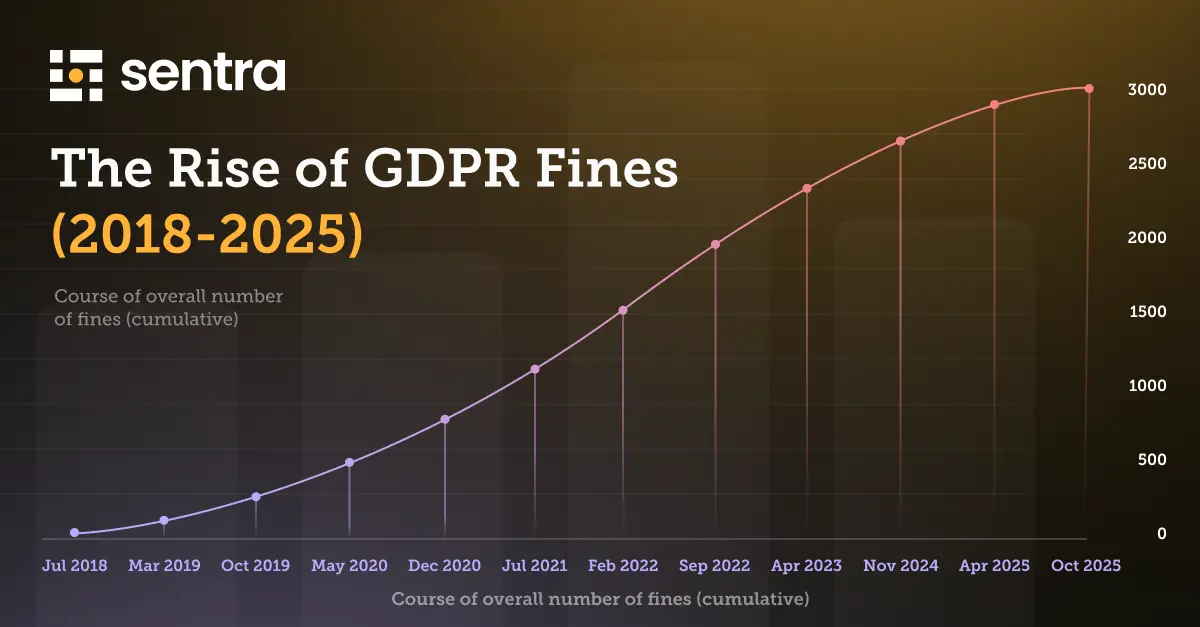
The Rise of Compliance Violations: A Wake-up Call
The increasing number of compliance violations and the related hefty fines should serve as a wake-up call for companies worldwide. As the regulatory environment becomes more complex, it is crucial for organizations to prioritize data protection and privacy. By doing so, they can avoid costly penalties and maintain the trust of their customers and stakeholders.
Solutions such as Sentra provide a cost-effective means to ensure sensitive data always has the right posture and security controls - no matter where the data travels - and can alert on exceptions that require rapid remediation. In this way, organizations can remain regulatory compliant, avoid the steep penalties for violations, and ensure the proper, secure use of data throughout their ecosystem.
To learn more about how Sentra's Data Security Platform can help you stay compliant, avoid GDPR penalties, and ensure the proper, secure use of data, request a demo today.
<blogcta-big>
Meni is an experienced product manager and the former founder of Pixibots (A mobile applications studio). In the past 15 years, he gained expertise in various industries such as: e-commerce, cloud management, dev-tools, mobile games, and more. He is passionate about delivering high quality technical products, that are intuitive and easy to use.


.webp)
