






Sentra Q2 2026 Product Updates: Data Security in the Age of AI

Every quarter I get asked some version of the same question: "What's the biggest shift you're seeing in enterprise data security right now?" My answer hasn't changed in the past year, but the urgency behind it keeps growing.
AI is no longer a side project. Copilots, agents, and LLM-powered apps are spinning up across Microsoft 365, AWS, Databricks, Azure, and beyond; often faster than security teams can track. At the same time, most large enterprises still have critical regulated data living on file shares and databases in their own data centers, largely invisible to cloud-first tools. And the DLP stacks organizations spent years building? They're only as smart as the labels and context they can see, which, for most companies, isn't very much.
These aren't new problems. But they've collided in a way that makes 2026 a genuinely pivotal year for data security. Read this post (or watch the on-demand webinar) for a walk through of what we shipped in Q2 and where we're taking Sentra for the rest of the year.
The Three Problems We Kept Hearing
Before I walk through our Q2 updates, it's worth naming the friction points that drove them. Across our customer conversations, three questions kept coming up without clean answers:
"What AI assets do we actually have, and what data do they touch?" Organizations know they're deploying copilots and agents. They often have no unified view of what those assets are connected to.
"We have critical data on-prem that never moved to the cloud. What do we do about it?" Almost every large enterprise we work with still has regulated data sitting in data centers. Historically, the choices were. 1) ignore it, 2) try to move it to the cloud just to scan it, which is usually a non-starter for compliance and operations.
"Our DLP stack isn't working the way it should. Is that a classification problem?" Almost always, yes. Enforcement agents, whether it's Microsoft Purview, Google DLP, SASE, CASB, or endpoint DLP, are only as good as the labels and context they see. If data isn't classified accurately and consistently, policies either never trigger or they trigger constantly and generate noise.
These three problems shaped our Q2 investments directly.
Q2 Update #1: AI Security - Turning AI Chaos Into a Governable Surface

The real risk with enterprise AI isn't the models themselves. It's that no one has a clean answer to three basic questions: What AI assets do we have? What data do they touch? And are they using that data in a way that would pass an audit?
In Q2, we took the first concrete step toward answering all three.
Unified AI Asset Inventory. We now give you a single view of your agents, models, and endpoints - with owners and environments - instead of having them scattered across different consoles. If you're running Copilot in M365, SageMaker models on AWS, and custom agents on Bedrock or Azure, they all show up in one place.
Data Lineage Into AI. For each agent, we map which knowledge bases and data stores it relies on and roll up the sensitive data classes and business context to the AI asset level. This is the part that matters most. Until now, people thought about data security in terms of how employees accessed files and permissions. With GenAI, data flows much faster through agents, so understanding the data at rest, and which AI assets touch it, is the critical control point.
Govern Data Use in AI. Once you have that lineage, you can start making real policy decisions. These are the data classes we're comfortable using for copilots and agents; these are the ones that must never be touched. We flag high-risk agents, those with access to regulated data or broad permissions, before they roll out, not after something leaks.
This is the first step toward our broader 2026 AI readiness vision: treating AI assets the same way we treat any other sensitive data store, with inventory, lineage, posture assessment, and policy enforcement. The goal is that when your organization wants to move faster with GenAI, Sentra gives you the map, the policies, and the evidence you need to say yes - safely.
Q2 Update #2: On-Prem & Hybrid Coverage - Securing the Data That Never Moved to the Cloud
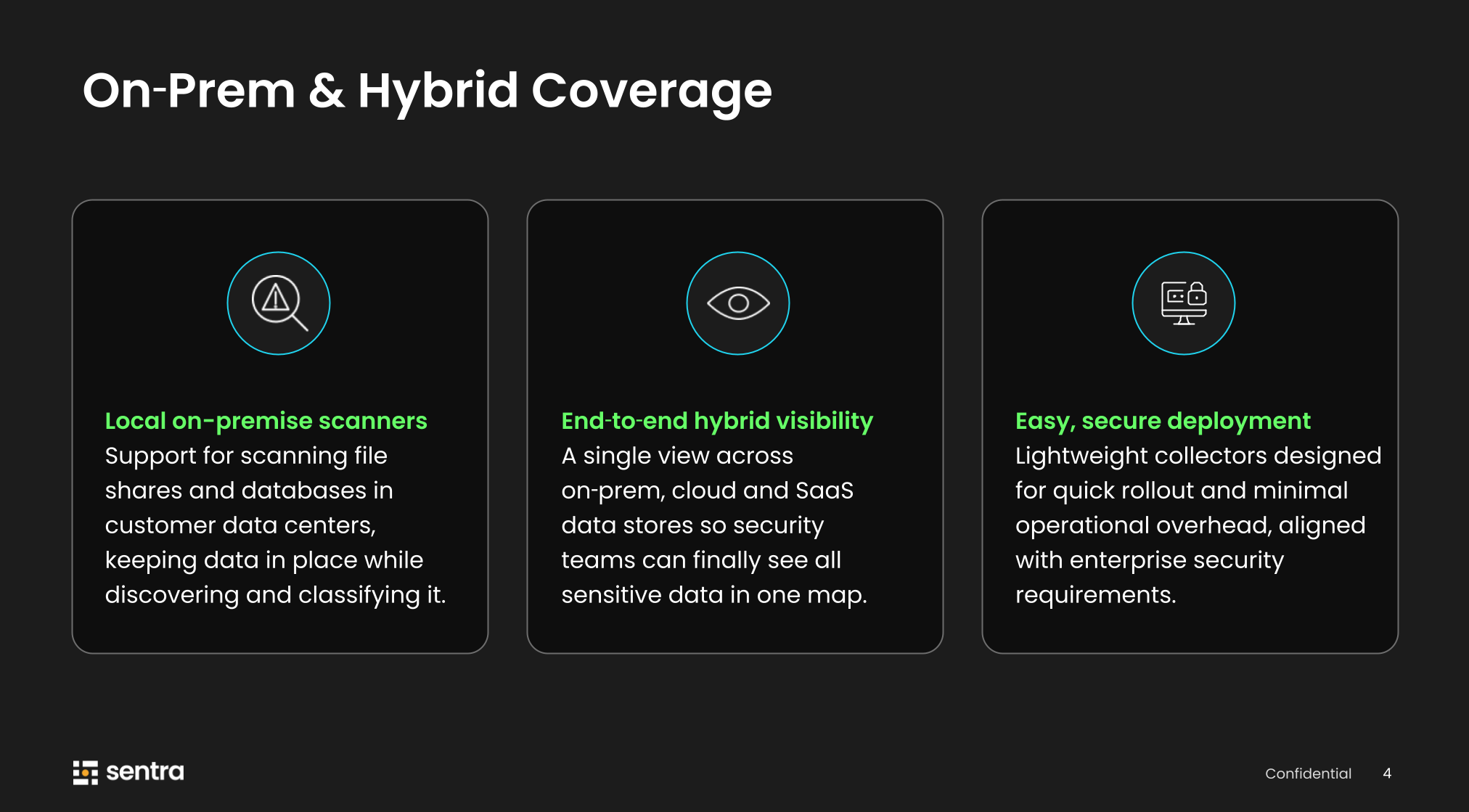
Almost every large enterprise we work with still has critical regulated data on file shares and databases in their own data centers. It's often the riskiest and least visible part of the estate.
In Q2, we introduced local on-premise scanners that run inside your environment, scan file shares and data stores where they live, and send us only the metadata and classifications, not the sensitive data itself. You get the same AI-powered discovery, classification, sensitivity mapping, and posture analytics you're used to in cloud and SaaS. Your data never leaves your data center.
"How realistic is full coverage?" - very realistic. We essentially took the technology we built for our cloud scanners and packaged it for any private data center or on-premise environment. We ship lightweight local scanners, support all types of SMB and NFS file shares, and cover databases including MySQL, Oracle, Postgres, and more. Sentra also connects to your Active Directory to map access levels across identities, file shares, and databases.
All of that feeds into a single map across on-prem, cloud, and SaaS, so security teams can finally reason about all their sensitive data everywhere, instead of managing separate point solutions for each island. And critically, this isn't a POC exercise. We focused on easy, secure deployment; lightweight collectors, quick rollout, and alignment with enterprise network and security requirements. This is something you can actually put into production.
Q2 Update #3: Automatic Labeling & Tagging - Making Your Existing DLP Stack Actually Smart

Most organizations aren't looking to rip and replace their DLP stack. The real pain is that enforcement is flying blind. DLP, SSE, CASB, and endpoint tools are like muscles without a brain. They can be powerful, but only if the underlying classification is accurate and consistent.
Sentra's role is to be the data security and classification brain that makes those existing tools actually smart.
In Q2, we doubled down on cross-platform auto-labeling. Automatically applying Microsoft Purview Information Protection (MPIP) labels in M365 and Google sensitivity labels in Google Drive, based on our high-accuracy discovery and classification. Those labels then become the control plane for everything downstream; email DLP, endpoint and web proxies, SaaS DLP, and even AI and Copilot controls that decide which data can be surfaced in responses.
Instead of authoring hundreds of brittle regex rules, you're keying policies off rich business context; HR compensation documents, customer financial statements, high-sensitivity intellectual property. The result is fewer false positives, better enforcement, and a classification foundation that scales.
Strategically, this is how we move from DSPM-plus-alerts to cloud-native DLP and automated remediation at scale. Sentra discovers and understands the data, stamps it with the right labels, and your existing enforcement stack, plus our own remediation, ensures data is only used, shared, and accessed in ways that match its true sensitivity.
Classification Is Still the Core of Everything
One thing I want to leave you with, because I don't think it gets said enough: classification is the foundation that makes all of this work. It's still where we invest the most at Sentra, and with advances in AI, we're making our capabilities more ambitious and more automatic.
We're building classifiers that are specific to each organization's proprietary data. Sentra learns your specific environment, and for every piece of data found, whether it's a file, a column, or a table, we know what it is and what its business context means. Beyond that, we're evolving our sensitivity scoring engine so security teams can bring their own definitions of what's sensitive, and our engine automatically translates that using AI into rules that ensure every piece of data gets the right label.
The goal is to make the effort of classifying and labeling data as easy as describing it to another human being. And to remove the manual research and validation work that doesn't scale in the AI era.
The Bottom Line
The challenge of enterprise data security in 2026 isn't a lack of tools. It's that the tools organizations have - DLP, CASB, SSE, endpoint controls - are only as effective as the data intelligence feeding them. At the same time, AI is creating an entirely new attack surface that most security teams can't see clearly yet. And on-premise data, the part of the estate that never moved to the cloud, remains the riskiest and least visible.
Sentra is building toward a single platform that addresses all three: a data-first security platform that discovers your critical data, understands its context, and drives the controls in your existing tools and in ours, so data stays safe, compliant, and usable for the business.
We'll see you next quarter with more updates. In the meantime, reach out if you have questions or schedule a demo if you want to go deeper on any of this.
Yair brings a wealth of experience in cybersecurity and data product management. In his previous role, Yair led product management at Microsoft and Datadog. With a background as a member of the IDF's Unit 8200 for five years, he possesses over 18 years of expertise in enterprise software, security, data, and cloud computing. Yair has held senior product management positions at Datadog, Digital Asset, and Microsoft Azure Protection.



