's Data Security Posts

What Does AI Data Readiness Actually Look Like at Scale? Lyft, SoFi, and Expedia Will Demonstrate at Gartner SRM 2026
What Does AI Data Readiness Actually Look Like at Scale? Lyft, SoFi, and Expedia Will Demonstrate at Gartner SRM 2026
Most organizations I talk to have the same answer when I ask what their AI sees: "We're not entirely sure."
That's not a technology problem. It's a data governance problem - and it's the most consequential unsolved problem in enterprise security right now.
AI doesn't discriminate. Copilot, cloud-based agents, internal LLMs, can access everything their users can access, and synthesize it in seconds. Years of overpermissioned, unclassified data that security teams have been meaning to clean up is now directly in the path of AI systems that move faster than any previous tool your organization has deployed.
The good news is some organizations have actually solved this. At the Gartner Security & Risk Management Summit this June, three of them are sharing exactly how.
The AI Data Readiness Problem Is Bigger Than Most Teams Realize
Here's what I see repeatedly across security programs. Organizations are deploying AI faster than they're governing the data underneath it.
The data estate didn't get cleaned up before Copilot rolled out. Shadow data stores weren't fully catalogued before the internal agent went live. Classification policies that worked fine for DLP weren't built to handle the access patterns that AI introduces.
When AI systems traverse a knowledge base, they don't stay in their lane - they surface whatever they can reach. If sensitive customer records, financial data, or PII are accessible to a user, they're accessible to that user's AI tools. And AI doesn't just retrieve; it synthesizes and presents, which means the exposure risk compounds.
Governing AI data readiness means knowing three things with accuracy and continuity:
What sensitive data exists and where it lives. Not from a six-month-old scan. From a continuously maintained inventory that reflects the environment as it actually is today.
Who and what can access it. Not just humans; AI agents, service accounts, automated pipelines. The access surface for AI is substantially wider than traditional access models account for.
Whether it's classified correctly before AI touches it. Classification is the foundation. It's what DLP runs on. It's what Copilot safety controls enforce against. If the labels are wrong or missing, every downstream control fails.
Expedia operates 450 petabytes of cloud data. Lyft and SoFi each manage 70+ petabytes. These aren't edge cases — they're the environments where AI data readiness problems are biggest, and where solving them produces the most visible results.
What You'll Hear at Gartner SRM 2026
Sentra is at Gartner SRM all week — June 1 through 3 at National Harbor — and we've built the week around the practitioners who've done this work, not around slides about why it matters.
Here's what's on the calendar.
Wednesday, June 3: Gartner Solution Provider Session
From Data Risk to AI Ready: The Lyft & Expedia Playbook 11:15–11:45 AM | Gartner Solution Provider Stage | Maryland C Ballroom
Hear from the Lyft CISO and Expedia on how they tackled the AI data readiness challenge in 100+ petabyte environments - classifying, governing, and securing the data sprawl already in the path of their AI initiatives. As AI proliferates across the enterprise, the data underneath it becomes the greatest unmanaged risk. In this session, experts share the decisions, tradeoffs, and tools that built their foundation - and what it made possible at scale. Walk away knowing the data readiness essentials so your AI initiative succeeds.
If you're at Gartner SRM this is the one solution provider session you won’t want to miss on Wednesday.
Use the Garter Agenda App to register for:
From Data Risk to AI Ready: The Lyft & Expedia Playbook
11:15–11:45 AM, Wednesday June 11,2026
Monday–Wednesday Morning Roundtables
Invite-Only Breakfast Sessions | Sentra Meeting Suite
These small-group sessions are the intimate version of the stage conversation — tailored to the specific attendee group, with real back-and-forth on what's working and what isn't.
Monday, June 1 | 8:00–8:45 AM (Breakfast) Lyft CISO Chaim Sanders on how Lyft built continuous data readiness and governance in a 70+ petabyte environment. How they classified at scale, where they found the unexpected exposure, and what they'd do differently.
Tuesday, June 2 | 8:00–8:45 AM (Breakfast) Expedia Distinguished Architect Payam Chychi on governing a 450-petabyte environment — the sprawl problem, the AI data access challenge, and the architecture decisions that made classification actionable.
Wednesday, June 3 | 8:00–8:45 AM (Breakfast) SoFi Sr. Manager of Product Security Engineering Zach Schulze on making 70+ PB of cloud data AI-ready — including how they combined Sentra DSPM with Wiz CSPM to reduce noise and govern safely.
Seats are limited and these sessions fill fast. Register at the Gartner SRM 2026 event page →
Tuesday, June 2: CISO Executive Dinner
7:30–9:30 PM | Grace's Mandarin | National Harbor
An invitation-only dinner with a small group of security leaders, including the Lyft CISO and security teams from Expedia and SoFi. Small tables. No presentations. The kind of conversation that only happens when the right people are in the right room.
If you'd like to be considered for an invitation, reach out directly via the event page or connect with your Sentra contact.
Monday–Wednesday: Executive 1:1 Briefings
8:00 AM–5:00 PM | Sentra Private Meeting Suite
For security leaders who want to apply the Lyft, SoFi, and Expedia learnings to their own environment — what AI readiness actually means given your data estate, your AI initiatives, and where your exposure lives. Sessions are led by Sentra's head of product or customer implementations. No slides. Just the right conversation.
All Week: Live Demos at Booth #222
See how Sentra discovers, classifies, and secures the data already in the path of your AI. The demo is built around your questions — bring the hard ones. The team onsite has worked with some of the largest data environments in the world.
Why This Matters Right Now
Gartner SRM is the right venue for this conversation, and 2026 is the right year to have it.
AI deployment accelerated faster than most security teams anticipated. The governance frameworks, classification foundations, and access controls that data-driven AI requires were, in many cases, not in place when the rollout happened. Now those teams are working backward — trying to understand what their AI can actually reach, and whether the data feeding it is classified accurately enough to trust.
The organizations presenting at our events this week tackled this problem at a scale that most enterprises haven't reached yet. What they learned applies regardless of environment size: classification has to happen before AI touches the data, not after. The inventory has to reflect reality continuously, not periodically. And governing AI access requires a fundamentally different approach than governing human access.
If you're at Gartner SRM and this is the problem your organization is working on, the sessions above are worth your time.
See the full schedule and register at sentra.io/gartner-srm-2026 →
DLP False Positives Are Drowning Your Security Team: How to Cut Noise with DSPM
DLP False Positives Are Drowning Your Security Team: How to Cut Noise with DSPM
Ask any security engineer how they feel about DLP alerts and you’ll usually get the same reaction. They are drowning in them. Over the last decade, DLP has built a reputation for noisy alerts, rigid rules, and confusing dashboards that bury real risk under a mountain of “maybe” events.
Teams roll out endpoint, email, and network DLP, wire in SaaS connectors, and import standard PCI/PII templates. Within weeks, analysts are triaging hundreds of alerts a day, most of which turn out to be benign. Business users complain that normal work is blocked, so policies get carved up with exceptions or quietly disabled. Meanwhile, the most sensitive data quietly spreads into collaboration tools, cloud storage, and AI workflows that DLP never sees.
The problem is that DLP is being asked to do too much on its own: discover sensitive data, understand its business context, and enforce policies in motion, all from a narrow view of each channel. To fix false positives in a durable way, you have to stop treating DLP as the brain of your data security program and give it an actual data-intelligence layer to work with.
That’s the role of modern Data Security Posture Management (DSPM).
Why Traditional DLP Can Be So Noisy
Most DLP engines still lean heavily on pattern matching and static rules. They look for strings that resemble card numbers, social security numbers, or keywords, and they try to infer “sensitive vs. not” from whatever they can see in a single email, file, or HTTP transaction. That approach might have been tolerable when most sensitive data sat in a few on‑prem systems, but it doesn’t scale to multi‑cloud, SaaS, and AI‑driven environments.
In practice, three things tend to go wrong:
First, DLP rarely has full visibility. Sensitive data now lives in cloud data lakes, SaaS apps, shared drives, ticketing systems, and AI training sets. Many of those locations are either out of reach for traditional DLP or only partially covered.
Second, the rules themselves are crude. A nine‑digit number might be a government ID, or it might be an internal ticket number. A CSV export might be an innocuous test file or a real production dump. Without a shared understanding of what the data actually represents, rules fire on look‑alikes and miss real exposures.
Third, each DLP product, the endpoint agent, the email gateway, the CASB, tries to solve classification locally. You end up with inconsistent detections and competing definitions of “sensitive” that don’t match what the business actually cares about. When you add those up, it’s no surprise that false positives consume so much analyst time and so much political capital with the business.
How DSPM Changes the Equation
DSPM was designed to separate what DLP has been trying to do into dedicated layers. Instead of asking DLP to discover, classify, and enforce all at once, DSPM owns discovery and classification, and DLP focuses on enforcement.
A DSPM platform like Sentra connects directly, via APIs and in‑environment scanning, to your cloud, SaaS, and on‑prem data stores. It builds a unified inventory of data, then uses AI‑driven models and domain‑specific logic to decide:
- What is this object?
- How sensitive is it?
- Which regulations or policies apply?
- Who or what can currently access it?
From there, DSPM applies consistent labels to that data, often using frameworks like Microsoft Purview Information Protection (MPIP) so labels are understood by other tools. Those labels are then pushed into your DLP stack, SSE/CASB, and email and endpoint controls, so every enforcement point is working from the same definition of sensitivity, instead of guessing on the fly.
Once DLP is enforcing on clear labels and context, rather than raw patterns, you no longer need dozens of almost‑duplicate rules per channel. Policies become simpler and more precise, which is what allows teams to realistically drive false positives down by up to half or more.
A Practical Approach to Cutting DLP Noise
If your security team is exhausted by DLP alerts today, you don’t need another round of regex tuning. You need a change in operating model. A pragmatic sequence looks like this.
Start by measuring the problem instead of just reacting to it. Capture how many DLP alerts you see per week, how many of those are ultimately dismissed, and how much analyst time they consume. Pay special attention to the policies and channels that generate the most noise, because that’s where you’ll see the biggest benefit from a DSPM‑driven approach.
Next, work with DSPM to turn your noisiest rules into label‑driven policies. Instead of “block any message that looks like it contains a card number,” express the rule as “block files labeled PCI sent to personal domains” or “quarantine emails carrying PHI labels to unapproved partners.” Once Sentra or another DSPM platform is reliably applying those labels, DLP simply has to enforce on them.
Then, add business context. The same file can be benign in one context and dangerous in another. Combine labels with identity, role, channel, and basic behavior signals like, time of day, destination, volume, etc., so that only genuinely suspicious events result in hard blocks or escalations. A finance export labeled ‘Confidential’ going to an approved auditor should not be treated the same as that export leaving for an unknown Gmail account at midnight.
Finally, create a feedback loop. Allow analysts to flag alerts as false positives or misconfigurations, and give users controlled ways to override with justification in edge cases. Feed that information back into DSPM tuning and DLP policies at a regular cadence, so your classification and rules get closer to how the business actually operates.
Over time, you’ll find that you write fewer DLP rules, not more. The rules you do have are easier to explain to stakeholders. And most importantly, your analysts spend their time on true positives and meaningful insider‑risk investigations, not on the hundredth low‑value alert of the week.
At that point, you haven’t just made DLP tolerable. You’ve turned it into a quiet, reliable enforcement layer sitting on top of a data‑intelligence foundation.
<blogcta-big>

How to Protect Sensitive Data in Azure
How to Protect Sensitive Data in Azure
As organizations migrate critical workloads to the cloud in 2026, understanding how to protect sensitive data in Azure has become a foundational security requirement. Azure offers a deeply layered security architecture spanning encryption, key management, data loss prevention, and compliance enforcement. This article breaks down each layer with technical precision, so security teams and architects can make informed decisions about safeguarding their most valuable data assets.
Azure Data Protection: A Layered Security Model
Azure's approach to data protection relies on multiple overlapping controls that work together to prevent unauthorized access, accidental modification, and data loss.
Storage-Level Encryption and Access Controls
Azure Storage Service Encryption (SSE) and Azure disk encryption options automatically protect data using AES-256, meeting FIPS 140-2 compliance standards across core services such as Azure Storage, Azure SQL Database, and Azure Data Lake.
All managed disks, snapshots, and images are encrypted by default using SSE with service-managed keys, and organizations can switch to customer-managed keys (CMKs) in Azure Key Vault when they need tighter control.
Azure Resource Manager locks, available in CanNotDelete and ReadOnly modes, prevent accidental deletion or configuration changes to critical storage accounts and other resources.
Immutability, Recovery, and Redundancy
- Immutability policies on Azure Blob Storage ensure data cannot be overwritten or deleted once written, which is valuable for regulatory compliance scenarios like financial records or audit logs.
- Soft delete retains deleted containers, blobs, or file shares in a recoverable state for a configurable period.
- Blob versioning and point-in-time restore allow rollback to earlier states to recover from logical corruption or accidental changes.
- Redundancy options, including LRS, ZRS, and cross-region options like GRS/GZRS—protect against hardware failures and regional outages.
Microsoft Defender for Storage further strengthens this model by detecting suspicious access patterns, malicious file uploads, and potential data exfiltration attempts across storage accounts.
Azure Encryption at Rest and in Transit
Encryption at Rest
Azure uses an envelope encryption model where a Data Encryption Key (DEK) encrypts the actual data, while a Key Encryption Key (KEK) wraps the DEK. For customer-managed scenarios, KEKs are stored and managed in Azure Key Vault or Managed HSM, while platform-managed keys are handled by Microsoft.
AES-256 is the default encryption algorithm across Azure Storage, Azure SQL Database, and Azure Data Lake for server-side encryption.
Transparent Data Encryption (TDE) applies this protection automatically for Azure SQL Database and Azure Synapse Analytics data files, encrypting data and log files in real time using a DEK protected by a key hierarchy that can include customer-managed keys.
For compute, encryption at host provides end-to-end encryption of VM data—including temporary disks, ephemeral OS disks, and disk caches - before it’s written to the underlying storage, and is Microsoft’s recommended option going forward as Azure Disk Encryption is phased out over time.
Encryption in Transit
Azure enforces modern transport-level encryption across its services:
- TLS 1.2 or later is required for encrypted connections to Azure services, with many services already enforcing TLS 1.2+ by default.
- HTTPS is mandatory for Azure portal interactions and can be enforced for storage REST APIs through the “secure transfer required” setting on storage accounts.
- Azure Files uses SMB 3.0 with built-in encryption for file shares.
- At the network layer, MACsec (IEEE 802.1AE) encrypts traffic between Azure datacenters, providing link-layer protection for traffic that leaves a physical boundary controlled by Microsoft.
- Azure VPN Gateways support IPsec/IKE (site-to-site) and SSTP (point-to-site) tunnels for hybrid connectivity, encrypting traffic between on-premises and Azure virtual networks.
- For sensitive columns in Azure SQL Database, Always Encrypted ensures data is encrypted within the client application before it ever reaches the database server.
A simplified view:
Azure Key Vault and Advanced Key Management
Encryption is only as strong as the key management strategy behind it. Azure Key Vault, Managed HSM, and related HSM offerings are the central services for storing and managing cryptographic keys, secrets, and certificates.
Key options include:
- Service-managed keys (SMK): Microsoft handles key generation, rotation, and backup transparently. This is the default for many services and minimizes operational overhead.
- Customer-managed keys (CMK): Organizations manage key lifecycles, rotation schedules, access policies, and revocation in Key Vault or Managed HSM, and can bring their own keys (BYOK).
- Hardware Security Modules (HSMs): Tamper-resistant hardware key storage for workloads that require FIPS 140-2 Level 3-style assurance, common in financial services and healthcare.
Azure supports automatic key rotation policies in Key Vault, reducing the operational burden of manual rotation. When using CMKs with TDE for Azure SQL Database, a Key Vault key (commonly RSA-2048) serves as the KEK that protects the DEK, adding a layer of customer-controlled governance to database encryption.
Azure Encryption at Host for Virtual Machines
Encryption at host extends Azure’s encryption coverage down to the VM host layer, ensuring that:
- Temporary disks, ephemeral OS disks, and disk caches are encrypted before they’re written to physical storage.
- Encryption is applied at the Azure infrastructure level, with no changes to the guest OS or application stack required.
- It supports both platform-managed keys and customer-managed keys via Key Vault, including automatic rotation.
This model is particularly important for regulated workloads (e.g., EHR systems, payment processing, or financial transaction logs) where even transient data on caches or temporary disks must be protected. It also reduces the risk of configuration drift that can occur when encryption is managed individually at the OS or application layer. As Azure Disk Encryption is gradually retired, encryption at host is the recommended default for new VM-based workloads.
Data Loss Prevention in and Around Azure
Encryption protects data at rest and in transit, but it does not prevent authorized users from mishandling or leaking sensitive information. That’s the role of data loss prevention (DLP).
In Microsoft’s ecosystem, DLP is primarily delivered through Microsoft Purview Data Loss Prevention, which applies policies across:
- Microsoft 365 services such as Exchange Online, SharePoint Online, OneDrive, and Teams
- Endpoints via endpoint DLP
- On-premises repositories and certain third-party cloud apps through connectors and integration with Microsoft Defender and Purview capabilities
How DLP Policies Work
DLP policies use automated content analysis - keyword matching, regular expressions, and machine learning-based classifiers - to detect sensitive information such as financial records, health data, and PII. When a violation is detected, policies can:
- Warn users with policy tips
- Require justification
- Block sharing, copying, or uploading actions
- Trigger alerts and incident workflows for security and compliance teams
Policies can initially run in simulation/audit mode so teams can understand impact before switching to full enforcement.
DLP and AI / Azure Workloads
For AI workloads and Azure services, DLP is part of a broader control set:
- Purview DLP governs content flowing through Microsoft 365 and integrated services that may feed AI assistants and copilots.
- On Azure resources such as Azure OpenAI, you use a combination of:
- Network restrictions (restrictOutboundNetworkAccess, private endpoints, NSGs, and firewalls) to prevent services from calling unauthorized external endpoints.
- Microsoft Defender for Cloud policies and recommendations for monitoring misconfigurations, exposed endpoints, and suspicious activity.
- Audit logging to verify that sensitive data is not being transmitted where it shouldn’t be.
Together, these capabilities give you both content-centric controls (DLP) and infrastructure-level controls (network and posture management) for AI workloads.
Compliance, Monitoring, and Ongoing Governance
Meeting regulatory requirements in Azure demands continuous visibility into where sensitive data lives, how it moves, and who can access it.
- Azure Policy enforces configuration baselines at scale: ensuring encryption is enabled, secure transfer is required, TLS versions are restricted, and storage locations meet regional requirements.
- For GDPR, you can use policy to restrict data storage to approved EU regions; for HIPAA, you enforce audit logging, encryption, and access controls on systems that handle PHI.
- Periodic audits should verify:
- Encryption is enabled across all storage accounts and databases.
- Key rotation schedules for CMKs are in place and adhered to.
- DLP policies cover intended data types and locations.
- Role-based access control (RBAC) and Privileged Identity Management (PIM) are used to maintain least-privilege access.
Azure Monitor and Microsoft Defender for Cloud provide real-time visibility into encryption status, access anomalies, misconfigurations, and policy violations across your subscriptions.
How Sentra Complements Azure's Native Controls
Sentra is a cloud-native data security platform that discovers and governs sensitive data at petabyte scale directly inside your Azure environment - data never leaves your control. It provides complete visibility into:
- Where sensitive data actually resides across Azure Storage, databases, SaaS integrations, and hybrid environments
- How that data moves between services, regions, and environments, including into AI training pipelines and copilots
- Who and what has access, and where excessive permissions or toxic combinations put regulated data at risk
Sentra’s AI-powered discovery and classification engine integrates with Microsoft’s ecosystem to:
- Feed high-accuracy labels and data classes into tools like Microsoft Purview DLP, improving policy effectiveness
- Enforce data-driven guardrails that prevent unauthorized AI access to sensitive data
- Identify and help eliminate shadow, redundant, obsolete, or trivial (ROT) data, typically reducing cloud storage costs by around 20% while shrinking the overall attack surface.
Knowing how to protect sensitive data in Azure is not a one-time configuration exercise; it is an ongoing discipline that combines strong encryption, disciplined key management, proactive data loss prevention, and continuous compliance monitoring. Organizations that treat these controls as interconnected layers rather than isolated features will be best positioned to meet current regulatory demands and the emerging security challenges of widespread AI adoption.
<blogcta-big>

Best Cloud Data Security Solutions for 2026
Best Cloud Data Security Solutions for 2026
As enterprises scale cloud workloads and AI initiatives in 2026, cloud data security has become a board‑level priority. Regulatory frameworks are tightening, AI assistants are touching more systems, and sensitive data now spans IaaS, PaaS, SaaS, data lakes, and on‑prem.
This guide compares four of the leading cloud data security solutions - Sentra, Wiz, Prisma Cloud, and Cyera - across:
- Architecture and deployment
- Data movement and “toxic combination” detection
- AI risk coverage and Copilot/LLM governance
- Compliance automation and real‑world user sentiment
What Users Are Saying
Review platforms and field conversations surface patterns that go beyond feature matrices.
Sentra
Pros
- Strong shadow data discovery, including legacy exports, backups, and unstructured sources like chat logs and call transcripts that other tools often miss
- Built‑in compliance facilitation that reduces audit prep time for healthcare, financial services, and other regulated industries
- In‑environment architecture that consistently appeals to privacy, risk, and data protection teams concerned about data residency and vendor data handling
Cons
- Dashboards and reporting are powerful but can feel dense for first‑time users who aren’t familiar with DSPM concepts
- Third‑party integrations are broad, but some connectors can lag when synchronizing very large environments
Wiz
Pros
- Excellent multi‑cloud visibility and security graph that correlate misconfigurations, identities, and data assets for fast remediation
- Well‑regarded customer success and responsive support teams
Cons
- High alert volume if policies aren’t carefully tuned, which can overwhelm small teams
- Configuration complexity grows with environment size and number of integrations
Prisma Cloud
Pros
- Strong real‑time threat detection tightly coupled with major cloud providers, well suited to security operations teams
- Proven scalability across large, hybrid environments combining containers, VMs, and serverless workloads
Cons
- Cost is frequently cited as a concern in large‑scale deployments
- Steeper learning curve that often requires dedicated training and ownership
Cyera
Pros
- Smooth, agentless deployment with quick time‑to‑value for data discovery in cloud stores
- Highly responsive support and strong focus on classification quality
Cons
- Integration and operationalization complexity in larger enterprises, especially when folding into wider security workflows
- Some backend customization and tuning require direct vendor involvement
Cloud Data Security Platforms: Architecture and Deployment
How a platform scans your data is as important as what it finds. Sending production data to a third‑party cloud for analysis can introduce its own risk, and regulators increasingly expect clear answers on where data is processed.
Sentra: In‑Environment DSPM for Regulated and AI‑Ready Data
Sentra takes a data‑first, in‑environment approach:
- Agentless connectors to cloud provider APIs and SaaS platforms mean sensitive content is scanned inside your accounts; it is never copied to Sentra’s cloud.
- Lightweight on‑prem scanners extend coverage to file shares and databases, creating a unified view across IaaS, PaaS, SaaS, and on‑prem systems.
This design makes Sentra particularly attractive to organizations with strict data residency requirements and privacy‑driven governance models, especially in finance, healthcare, and other regulated sectors.
Wiz: Agentless CNAPP with Optional Runtime Sensors
Wiz is fundamentally agentless, connecting to cloud environments via APIs and leveraging temporary snapshots for inspection.
- An optional eBPF‑based sensor adds runtime visibility for workloads without introducing inline latency.
- The same security graph model underpins both infrastructure risk and emerging data/AI lineage features.
Prisma Cloud: Hybrid Agentless + Agent Model
Prisma Cloud combines:
- Agentless scanning for vulnerabilities, misconfigurations, and compliance posture.
- Optional agents or sidecars when deep runtime protection or granular workload telemetry is required.
This hybrid approach offers powerful coverage, but introduces more operational overhead than purely agentless DSPM platforms like Sentra and Cyera.
Cyera: In‑Place Cloud Data Inspection
Cyera focuses on in‑place data inspection, using local snapshots or direct connections to datastore APIs.
- Sensitive data is analyzed within your environment rather than being shipped to a vendor cloud.
- This aligns well with privacy‑first architectures that treat any external data processing as a risk to be minimized.
Identifying Toxic Combinations and Tracking Data Movement
Static discovery like, “here are your S3 buckets” is a basic capability. Real security value comes from correlating data sensitivity, effective access, and how data moves over time across clouds, regions, and environments.
Sentra: Data‑Aware Risk and End‑to‑End Data Flow Visibility
Sentra continuously maps your entire data estate, correlating classification results with IAM, ACLs, and sharing links to surface “toxic combinations” - high‑sensitivity data behind overly broad permissions.
- Tracks data movement across ETLs, database migrations, backups, and AI pipelines so you can see when production data drifts into dev, test, or unapproved regions.
- Extends beyond primary databases to cover data lakes, analytics platforms, and modern big‑data formats in object storage, which are increasingly used as AI training inputs.
This gives security and data teams a living map of where sensitive data actually lives and how it moves, not just a static list of storage locations.
Wiz: Security Graph and CIEM
Wiz’s Security Graph maps identities, resources, configurations, and data stores in one model.
- Its CIEM capabilities aggregate effective permissions (including inherited policies and group memberships) to highlight over‑exposed data resources.
- Wiz tracks data lineage into AI pipelines as part of its broader cloud risk view, helping teams understand where sensitive data intersects with ML workloads.
Prisma Cloud: Graph‑Based Attack Paths
Prisma Cloud uses a graph‑based risk engine to continuously simulate attack paths:
- Seemingly low‑risk misconfigurations and broad permissions are combined to identify chains that could expose regulated data.
- The platform generates near real‑time alerts when data crosses geofencing boundaries or flows into unapproved analytics or AI environments.
Cyera: AI‑Native Classification and LLM Validation
Cyera pairs AI‑native classification with access analysis:
- It continuously scans structured and unstructured data for sensitive content, mapping who and what can reach each dataset.
- An LLM‑based validation layer distinguishes real sensitive data from mock or synthetic data in dev/test, which can reduce false positives and cleanup noise.
AI Risk Detection: Shadow AI and Copilot Governance
Enterprise AI tools introduce a new class of risk: employees connecting business data to unauthorized models, or AI agents and copilots inheriting excessive access to legacy data.
Sentra: AI‑Ready Data Security and Copilot Guardrails
Sentra treats AI risk as a data problem:
- Tracks data flows between sources and destinations and compares them against an inventory of approved AI tools, flagging when sensitive data is routed to unauthorized LLMs or agents.
- For Microsoft 365 Copilot, Sentra builds a catalog of data across SharePoint, OneDrive, and Teams, mapping which users and groups can access each set of documents and providing guardrails before Copilot is widely rolled out.
This gives security teams a practical definition of AI data readiness: knowing exactly which data AI can see, and shrinking that blast radius before something goes wrong.
Cyera: AISPM and AI Runtime Protection
Cyera takes a dual‑layer approach to AI risk:
- AI Security Posture Management (AISPM) inventories sanctioned and unsanctioned AI tools and maps which sensitive datasets each can access.
- AI Runtime Protection monitors prompts, responses, and agent actions in real time, blocking suspicious activity such as data leakage or prompt‑injection attempts.
For M365 Copilot Studio, Cyera integrates with Microsoft Entra’s agent registry to track AI agents and their data scopes.
Wiz and Prisma Cloud: AI as Part of Data Lineage
Wiz and Prisma Cloud both treat AI as an extension of their data lineage and attack‑path capabilities:
- They track when sensitive data enters AI pipelines or training environments and how that intersects with misconfigurations and identity risk.
- However, they do not yet offer the same depth of AI‑specific governance controls and runtime protections as dedicated AI‑aware platforms like Sentra and Cyera.
Compliance Automation and Framework Mapping
For teams preparing for GDPR, HIPAA, PCI, SOC 2, or EU AI Act reviews, manually mapping findings to control sets and assembling evidence is slow and error‑prone.
Platform Approaches to Compliance
Sentra is especially compelling when audits hinge on where regulated data actually lives and how it is governed, rather than just infrastructure posture.
Choosing Among the Best Cloud Data Security Solutions
All four platforms address real, pressing needs—but they are not interchangeable.
- Choose Sentra if you need strict in‑environment data governance, high‑precision discovery across cloud, SaaS, and on‑prem, and AI‑aware guardrails that make Copilot and other AI deployments provably safer—without moving sensitive data out of your own infrastructure.
- Choose Wiz if your top priority is broad cloud security coverage and a unified graph for vulnerabilities, misconfigurations, identities, and data across multi‑cloud at scale.
- Choose Prisma Cloud if you want a code‑to‑cloud platform that ties data exposure to DevSecOps pipelines and workload runtime protection, and you have the resources to operationalize its breadth.
- Choose Cyera if you’re focused on AI‑native classification and a converged DLP + DSPM motion for large volumes of cloud data, and you’re prepared for a more involved integration phase.
For most mature security programs, the question isn’t whether to adopt these tools but how to layer them:
- A CNAPP for cloud infrastructure risk
- A DSPM platform like Sentra for data‑first visibility and AI readiness
- DLP/SSE for enforcement at egress and user edges
- Compliance automation to translate all of that into evidence your auditors, regulators, and board can trust
Taken together, this stack lets you move faster in the cloud and with AI, without losing control of the data that actually matters.

<blogcta-big>
How to Protect Sensitive Data in AWS
How to Protect Sensitive Data in AWS
Storing and processing sensitive data in the cloud introduces real risks, misconfigured buckets, over-permissive IAM roles, unencrypted databases, and logs that inadvertently capture PII. As cloud environments grow more complex in 2026, knowing how to protect sensitive data in AWS is a foundational requirement for any organization operating at scale. This guide breaks down the key AWS services, encryption strategies, and operational controls you need to build a layered defense around your most critical data assets.
How to Protect Sensitive Data in AWS (With Practical Examples)
Effective protection requires a layered, lifecycle-aware strategy. Here are the core controls to implement:
Field-Level and End-to-End Encryption
Rather than encrypting all data uniformly, use field-level encryption to target only sensitive fields, Social Security numbers, credit card details, while leaving non-sensitive data in plaintext. A practical approach: deploy Amazon CloudFront with a Lambda@Edge function that intercepts origin requests and encrypts designated JSON fields using RSA. AWS KMS manages the underlying keys, ensuring private keys stay secure and decryption is restricted to authorized services.
Encryption at Rest and in Transit
Enable default encryption on all storage assets, S3 buckets, EBS volumes, RDS databases. Use customer-managed keys (CMKs) in AWS KMS for granular control over key rotation and access policies. Enforce TLS across all service endpoints. Place databases in private subnets and restrict access through security groups, network ACLs, and VPC endpoints.
Strict IAM and Access Controls
Apply least privilege across all IAM roles. Use AWS IAM Access Analyzer to audit permissions and identify overly broad access. Where appropriate, integrate the AWS Encryption SDK with KMS for client-side encryption before data reaches any storage service.
Automated Compliance Enforcement
Use CloudFormation or Systems Manager to enforce encryption and access policies consistently. Centralize logging through CloudTrail and route findings to AWS Security Hub. This reduces the risk of shadow data and configuration drift that often leads to exposure.
What Is AWS Macie and How Does It Help Protect Sensitive Data?
AWS Macie is a managed security service that uses machine learning and pattern matching to discover, classify, and monitor sensitive data in Amazon S3. It continuously evaluates objects across your S3 inventory, detecting PII, financial data, PHI, and other regulated content without manual configuration per bucket.
Key capabilities:
- Generates findings with sensitivity scores and contextual labels for risk-based prioritization
- Integrates with AWS Security Hub and Amazon EventBridge for automated response workflows
- Can trigger Lambda functions to restrict public access the moment sensitive data is detected
- Provides continuous, auditable evidence of data discovery for GDPR, HIPAA, and PCI-DSS compliance
Understanding what sensitive data exposure looks like is the first step toward preventing it. Classifying data by sensitivity level lets you apply proportionate controls and limit blast radius if a breach occurs.
AWS Macie Pricing Breakdown
Macie offers a 30-day free trial covering up to 150 GB of automated discovery and bucket inventory. After that:
For large environments, scope automated discovery to your highest-risk buckets first and use targeted jobs for periodic deep scans of lower-priority storage. This balances coverage with cost efficiency.
What Is AWS GuardDuty and How Does It Enhance Data Protection?
AWS GuardDuty is a managed threat detection service that continuously monitors CloudTrail events, VPC flow logs, and DNS logs. It uses machine learning, anomaly detection, and integrated threat intelligence to surface indicators of compromise.
What GuardDuty detects:
- Unusual API calls and atypical S3 access patterns
- Abnormal data exfiltration attempts
- Compromised credentials
- Multi-stage attack sequences correlated from isolated events
Findings and underlying log data are encrypted at rest using KMS and in transit via HTTPS. GuardDuty findings route to Security Hub or EventBridge for automated remediation, making it a key component of real-time data protection.
Using CloudWatch Data Protection Policies to Safeguard Sensitive Information
Applications frequently log more than intended, request payloads, error messages, and debug output can all contain sensitive data. CloudWatch Logs data protection policies automatically detect and mask sensitive information as log events are ingested, before storage.
How to Configure a Policy
- Create a JSON-formatted data protection policy for a specific log group or at the account level
- Specify data types to protect using over 100 managed data identifiers (SSNs, credit cards, emails, PHI)
- The policy applies pattern matching and ML in real time to audit or mask detected data
Important Operational Considerations
- Only users with the logs:Unmask IAM permission can view unmasked data
- Encrypt log groups containing sensitive data using AWS KMS for an additional layer
- Masking only applies to data ingested after a policy is active, existing log data remains unmasked
- Set up alarms on the LogEventsWithFindings metric and route findings to S3 or Kinesis Data Firehose for audit trails
Implement data protection policies at the point of log group creation rather than retroactively, this is the single most common mistake teams make with CloudWatch masking.
How Sentra Extends AWS Data Protection with Full Visibility
Native AWS tools like Macie, GuardDuty, and CloudWatch provide strong point-in-time controls, but they don't give you a unified view of how sensitive data moves across accounts, services, and regions. This is where minimizing your data attack surface requires a purpose-built platform.
What Sentra adds:
- Discovers and governs sensitive data at petabyte scale inside your own environment, data never leaves your control
- Maps how sensitive data moves across AWS services and identifies shadow and redundant/obsolete/trivial (ROT) data
- Enforces data-driven guardrails to prevent unauthorized AI access
- Typically reduces cloud storage costs by ~20% by eliminating data sprawl
Knowing how to protect sensitive data in AWS means combining the right services, KMS for key management, Macie for S3 discovery, GuardDuty for threat detection, CloudWatch policies for log masking, with consistent access controls, encryption at every layer, and continuous monitoring. No single tool is sufficient. The organizations that get this right treat data protection as an ongoing operational discipline: audit IAM policies regularly, enforce encryption by default, classify data before it proliferates, and ensure your logging pipeline never exposes what it was meant to record.
<blogcta-big>
How to Protect Sensitive Data in GCP
How to Protect Sensitive Data in GCP
Protecting sensitive data in Google Cloud Platform has become a critical priority for organizations navigating cloud security complexities in 2026. As enterprises migrate workloads and adopt AI-driven technologies, understanding how to protect sensitive data in GCP is essential for maintaining compliance, preventing breaches, and ensuring business continuity. Google Cloud offers a comprehensive suite of native security tools designed to discover, classify, and safeguard critical information assets.
Key GCP Data Protection Services You Should Use
Google Cloud Platform provides several core services specifically designed to protect sensitive data across your cloud environment:
- Cloud Key Management Service (Cloud KMS) enables you to create, manage, and control cryptographic keys for both software-based and hardware-backed encryption. Customer-Managed Encryption Keys (CMEK) give you enhanced control over the encryption lifecycle, ensuring data at rest and in transit remains secured under your direct oversight.
- Cloud Data Loss Prevention (DLP) API automatically scans data repositories to detect personally identifiable information (PII) and other regulated data types, then applies masking, redaction, or tokenization to minimize exposure risks.
- Secret Manager provides a centralized, auditable solution for managing API keys, passwords, and certificates, keeping secrets separate from application code while enforcing strict access controls.
- VPC Service Controls creates security perimeters around cloud resources, limiting data exfiltration even when accounts are compromised by containing sensitive data within defined trust boundaries.
Getting Started with Sensitive Data Protection in GCP
Implementing effective data protection begins with a clear strategy. Start by identifying and classifying your sensitive data using GCP's discovery and profiling tools available through the Cloud DLP API. These tools scan your resources and generate detailed profiles showing what types of sensitive information you're storing and where it resides.
Define the scope of protection needed based on your specific data types and regulatory requirements, whether handling healthcare records subject to HIPAA, financial data governed by PCI DSS, or personal information covered by GDPR. Configure your processing approach based on operational needs: use synchronous content inspection for immediate, in-memory processing, or asynchronous methods when scanning data in BigQuery or Cloud Storage.
Implement robust Identity and Access Management (IAM) practices with role-based access controls to ensure only authorized users can access sensitive data. Configure inspection jobs by selecting the infoTypes to scan for, setting up schedules, choosing appropriate processing methods, and determining where findings are stored.
Using Google DLP API to Discover and Classify Sensitive Data
The Google DLP API provides comprehensive capabilities for discovering, classifying, and protecting sensitive data across your GCP projects. Enable the DLP API in your Google Cloud project and configure it to scan data stored in Cloud Storage, BigQuery, and Datastore.
Inspection and Classification
Initiate inspection jobs either on demand using methods like InspectContent or CreateDlpJob, or schedule continuous monitoring using job triggers via CreateJobTrigger. The API automatically classifies detected content by matching data against predefined "info types" or custom criteria, assigning confidence scores to help you prioritize protection efforts. Reusable inspection templates enhance classification accuracy and consistency across multiple scans.
De-identification Techniques
Once sensitive data is identified, apply de-identification techniques to protect it:
- Masking (obscuring parts of the data)
- Redaction (completely removing sensitive segments)
- Tokenization
- Format-preserving encryption
These transformation techniques ensure that even if sensitive data is inadvertently exposed, it remains protected according to your organization's privacy and compliance requirements.
Preventing Data Loss in Google Cloud Environments
Preventing data loss requires a multi-layered approach combining discovery, inspection, transformation, and continuous monitoring. Begin with comprehensive data discovery using the DLP API to scan your data repositories. Define scan configurations specifying which resources and infoTypes to inspect and how frequently to perform scans. Leverage both synchronous and asynchronous inspection approaches. Synchronous methods provide immediate results using content.inspect requests, while asynchronous approaches using DlpJobs suit large-scale scanning operations. Apply transformation methods, including masking, redaction, tokenization, bucketing, and date shifting, to obfuscate sensitive details while maintaining data utility for legitimate business purposes.
Combine de-identification efforts with encryption for both data at rest and in transit. Embed DLP measures into your overall security framework by integrating with role-based access controls, audit logging, and continuous monitoring. Automate these practices using the Cloud DLP API to connect inspection results with other services for streamlined policy enforcement.
Applying Data Loss Prevention in Google Workspace for GCP Workloads
Organizations using both Google Workspace and GCP can create a unified security framework by extending DLP policies across both environments. In the Google Workspace Admin console, create custom rules that detect sensitive patterns in emails, documents, and other content. These policies trigger actions like blocking sharing, issuing warnings, or notifying administrators when sensitive content is detected.
Google Workspace DLP automatically inspects content within Gmail, Drive, and Docs for data patterns matching your DLP rules. Extend this protection to your GCP workloads by integrating with Cloud DLP, feeding findings from Google Workspace into Cloud Logging, Pub/Sub, or other GCP services. This creates a consistent detection and remediation framework across your entire cloud environment, ensuring data is safeguarded both at its source and as it flows into or is processed within your Google Cloud Platform workloads.
Enhancing GCP Data Protection with Advanced Security Platforms
While GCP's native security services provide robust foundational protection, many organizations require additional capabilities to address the complexities of modern cloud and AI environments. Sentra is a cloud-native data security platform that discovers and governs sensitive data at petabyte scale inside your own environment, ensuring data never leaves your control. The platform provides complete visibility into where sensitive data lives, how it moves, and who can access it, while enforcing strict data-driven guardrails.
Sentra's in-environment architecture maps how data moves and prevents unauthorized AI access, helping enterprises securely adopt AI technologies. The platform eliminates shadow and ROT (redundant, obsolete, trivial) data, which not only secures your organization for the AI era but typically reduces cloud storage costs by approximately 20 percent. Learn more about securing sensitive data in Google Cloud with advanced data security approaches.
Understanding GCP Sensitive Data Protection Pricing
GCP Sensitive Data Protection operates on a consumption-based, pay-as-you-go pricing model. Your costs reflect the actual amount of data you scan and process, as well as the number of operations performed. When estimating your budget, consider several key factors:
To better manage spending, estimate your expected data volume and scan frequency upfront. Apply selective scanning or filtering techniques, such as scanning only changed data or using file filters to focus on high-risk repositories. Utilize Google's pricing calculator along with cost monitoring dashboards and budget alerts to track actual usage against projections. For organizations concerned about how sensitive cloud data gets exposed, investing in proper DLP configuration can prevent costly breaches that far exceed the operational costs of protection services.
Successfully protecting sensitive data in GCP requires a comprehensive approach combining native Google Cloud services with strategic implementation and ongoing governance. By leveraging Cloud KMS for encryption management, the Cloud DLP API for discovery and classification, Secret Manager for credential protection, and VPC Service Controls for network segmentation, organizations can build robust defenses against data exposure and loss.
The key to effective implementation lies in developing a clear data protection strategy, automating inspection and remediation workflows, and continuously monitoring your environment as it evolves. For organizations handling sensitive data at scale or preparing for AI adoption, exploring additional GCP security tools and advanced platforms can provide the comprehensive visibility and control needed to meet both security and compliance objectives. As cloud environments grow more complex in 2026 and beyond, understanding how to protect sensitive data in GCP remains an essential capability for maintaining trust, meeting regulatory requirements, and enabling secure innovation.
<blogcta-big>
7 Data Loss Prevention Best Practices to Cut False Positives and Blind Spots
7 Data Loss Prevention Best Practices to Cut False Positives and Blind Spots
Most security leaders aren’t asking for “more DLP.” They’re asking why the DLP they already own is noisy, brittle, and still misses real risk. You turn on endpoint, email, and network DLP. You import PCI and PII templates. Within weeks, users complain that normal work is blocked, so policies get relaxed or disabled. Analysts drown in meaningless alerts. Meanwhile, you know there are blind spots in SaaS, cloud data stores, and AI tools that DLP never sees.
The problem usually isn’t that you bought the “wrong” DLP. It’s that DLP is doing too much on its own: trying to discover sensitive data, understand business context, and enforce policies in one step. To improve the functioning of your DLP, you have to separate those responsibilities and give DLP the data intelligence it has always been missing.
This guide walks through seven data loss prevention best practices that:
- Cut DLP false positives and alert fatigue
- Close blind spots across SaaS, cloud, and AI
- Show how to use Data Security Posture Management (DSPM) alongside DLP instead of treating them as competitors
1. Start with a specific DLP problem, not a vague mandate
Many DLP programs are born from a broad requirement like “prevent data loss” or “achieve compliance.” That sounds reasonable, but it’s too fuzzy to drive design decisions. If everything is “data loss,” every event looks important and tuning turns into guesswork. Instead, define one or two sharp, testable problems to solve in the next 90 days.
For example:
- Reduce DLP false positives by 50% while maintaining coverage across email and collaboration tools.
- Eliminate unknown PHI exposures in Microsoft 365 and Google Workspace before the next HIPAA audit.
- Stop real customer data from leaking into lower environments and AI training pipelines.
Once you frame the goal concretely, a few things fall into place. You know what to measure (false-positive rate, blind-spot coverage, number of mis‑labeled data stores). You can see which parts are posture problems (where data lives, how it’s labeled, who can touch it) and which are pure enforcement. And you have a clear way to tell whether the program is actually improving, rather than just “having DLP turned on.” In short, give your DLP initiative a narrow, measurable purpose before you touch any rules.
2. Fix classification before you tune DLP rules
Almost every struggling DLP deployment eventually discovers the same truth: it doesn’t really have a DLP problem, it has a classification problem. Traditional DLP leans heavily on pattern matching and static dictionaries. In modern environments, that leads to constant mistakes:
- Internal IDs or ticket numbers mistaken for card data or SSNs
- Highly sensitive business documents missed because they don’t match canned patterns
- Each product (endpoint DLP, email DLP, CASB) trying to re‑implement classification in its own silo
This is exactly the gap DSPM is designed to fill. A platform like Sentra DSPM continuously:
- Discovers sensitive data at scale across cloud, SaaS, data warehouses, on‑prem stores, and AI pipelines, without copying it out of your environment
- Classifies that data using multi‑signal, AI‑driven models that combine entity‑level signals (PII, PCI, PHI fields, secrets) with file‑level semantics (document type, business function, domain)
- Labels assets consistently, for example, by auto‑applying Microsoft Purview Information Protection (MPIP) labels that downstream tools, including DLP, can consume
Once you trust the labels, DLP can stop trying to “guess” sensitivity from raw content and location. Policies get simpler and more stable because they key off well‑defined labels instead of brittle regular expressions.
Best practice: before you tweak another DLP rule, invest in getting classification right with DSPM, then let DLP enforce on the resulting labels.
3. Reduce DLP false positives with labels and context
“Reduce DLP false positives” is one of the most common reasons security teams revisit their DLP strategy. Most false positives come from two root causes:
- Over‑broad content rules that match anything vaguely sensitive
- Lack of business context like; who the user is, which system they’re in, where the data is going, and whether that’s normal behavior
The first step is to move to label‑driven policies wherever possible. Instead of “block anything that looks like a credit card number,” write rules like “block sending files labeled PCI to personal email domains” or “quarantine emails with PHI labels sent outside approved partners.” DSPM plus accurate labeling makes that possible at scale.
The second step is to bring in more context. A file labeled Confidential going to a known external auditor is very different from that same file going to a new personal Dropbox account at 2 a.m.
When you combine labels with:
- Identity and role
- Channel (email, web, SaaS, AI)
- Destination and geography
- Simple behavior analytics (volume, unusual time, unusual location)
You can reserve hard blocks and escalations for situations that actually look risky.
Finally, you need a real feedback loop. Let users override certain DLP prompts with a required justification and log “reported false positives.” Review those regularly with business owners. That feedback is invaluable for tightening rules where they truly matter and relaxing them where they are just creating friction. In practice, enforce on labels first, then refine with business context and user feedback, instead of trying to make regexes infinitely smarter.
4. Treat DSPM and DLP as a single system, not a “DSPM vs DLP” choice
If you search for “DSPM vs DLP,” you’ll find plenty of comparison articles and vendor takes. From the customer’s side, though, the most useful framing is not “which one?” but “what does each do, and how do they work together?”
At a high level:
- DSPM focuses on data-at-rest intelligence: it shows what sensitive data you have, where it resides, who and what can access it, how it’s configured, and whether that posture is acceptable for your risk and compliance requirements.
- DLP focuses on data-in-motion enforcement: it monitors data leaving (or moving within) the organization via email, endpoints, web, SaaS, and APIs, and decides what to block, encrypt, or just log based on policies.
When you connect them, you get a closed loop:
- DSPM discovers, classifies, and labels sensitive data consistently across cloud, SaaS, on‑prem, and AI.
- Data access governance uses that context to right‑size permissions and remediate over‑exposure.
- DLP and related controls enforce label‑driven policies at the edges, with far fewer false positives and blind spots.
DSPM doesn’t replace DLP; it makes DLP accurate, scalable, and cloud/AI‑ready. Takeaway, stop framing it as DSPM versus DLP. Your DLP will only be as good as the DSPM feeding it.
5. Bring SaaS, cloud, and AI into scope for DLP
Most older DLP programs were built around email and endpoints. But in cloud‑first organizations, the riskiest data flows now run through:
- Cloud and object storage (S3, GCS, Azure Blob)
- Data warehouses and lakes (Snowflake, BigQuery, Databricks)
- SaaS platforms (M365, Google Workspace, Box, Salesforce, Slack, Teams)
- AI systems (M365 Copilot, Gemini for GWS, Bedrock, custom RAG apps)
Trying to bolt classic inline DLP controls onto all of those surfaces is expensive and incomplete. You’ll still miss shadow data, lower environments that contain real customer data, and AI pipelines that consume sensitive content by design.
DSPM gives you a more scalable pattern:
- Inventory and classify sensitive data where it sits across cloud, SaaS, and AI.
- Use that intelligence to drive native controls: MPIP labels and Microsoft Purview DLP, CASB/SSE policies, Snowflake dynamic masking, IAM/CIEM, and AI guardrails.
For example, a healthcare organization might combine:
- Sentra’s DSPM to discover PHI in Google Drive, M365, Salesforce, and Snowflake
- Auto‑labeling of that PHI so Purview and DLP can enforce correctly
- AI‑aware classification to govern which labeled data copilots and agents are allowed to see
See How Valenz Health Uses DSPM to Protect PHI Across AWS, Azure, and Modern Data Platforms
Similarly, the DLP for Google Workspace story shows how cloud‑native, DSPM‑powered classification is essential to make platform DLP effective for unstructured content in OneDrive, SharePoint, and Teams. Best practice, treat SaaS, cloud, and AI as first‑class DLP surfaces, and use DSPM to make them visible and governable before you try to enforce.
6. Design DLP policies for real workflows, then harden them
Many DLP programs fail not because the tools are weak, but because the policies were designed for whiteboards, not for real users.
Very often:
- The ruleset is too broad, with dozens of overlapping controls per channel
- Business stakeholders had little input, so workflows break in production
- There’s no staged rollout path; policies jump straight from “off” to “block”
A better pattern is to treat DLP policies as something you product‑manage. Start by expressing a very small set of core policies in business terms, independent of channel.
For example:
- “Regulated data (PII, PCI, PHI) must not leave specific regions or approved partners.”
- “Files labeled Highly Confidential must never be shared to personal email or cloud domains.”
- “AI assistants and copilots may only access data labeled Internal or below.”
Then map those policies onto channels with graduated responses:
- Log only (for simulation and tuning)
- User prompts (“This file is labeled Confidential; are you sure?”)
- Override with justification (captured for review)
- Hard block + ticket for the riskiest conditions
Throughout, involve legal, compliance, HR, and business owners. If DLP events could lead to performance conversations or disciplinary action, you don’t want those stakeholders to be surprised by how the system behaves.
Ready to get started? Read: How to Build a Modern DLP Strategy That Actually Works: DSPM + Endpoint + Cloud DLP
Key idea, roll out label‑driven policies gently, let reality teach you where controls can be strict, and only then lock them down.
7. Measure DLP like a product, not a checkbox
If your goal is to “supercharge DLP so it performs better,” you need to know how it’s performing now, and how changes affect it. That means treating DLP like a product with KPIs, not a compliance box you either have or don’t.
High‑performing teams tend to track four categories:
- Coverage: percentage of data stores under DSPM visibility; proportion of sensitive assets correctly labeled; number of major SaaS and cloud platforms within scope.
- Quality: false positive and false negative rates by policy and channel; serious incidents discovered outside DLP that should have triggered it.
- Operational impact: mean time to detect and respond to data‑loss incidents; analyst hours spent per week on DLP triage; number of issues auto‑remediated via workflows (auto‑labeling, auto‑revoking access, auto‑quarantining content).
- Business alignment: frequency of stakeholder requests to disable or bypass policies; time to prepare for audits compared to prior years.
A platform like Sentra’s data security platform gives you much of this telemetry out of the box through its unified inventory, access graph, and integration hooks into SIEM/SOAR, IAM, DLP, SSE/CASB, and ITSM. Bottom line, you can’t fix what you can’t measure. Decide which DLP metrics matter to your organization and revisit them as you evolve your DSPM + DLP architecture.
What “Supercharge Your DLP” means in practice
When teams say “we need to fix our DLP,” they usually don’t mean “rip everything out.” They mean:
- “We don’t trust the alerts we get.”
- “We know there are blind spots in cloud, SaaS, and AI.”
- “We’re tired of fighting with brittle rules that don’t reflect how the business actually works.”
Supercharging DLP in the cloud and AI era starts with data intelligence. That means:
- Using DSPM to discover and classify sensitive data everywhere
- Applying consistent labels that encode business meaning
- Wiring those labels into the DLP and access controls you already own
From there, DLP can finally do what it was always meant to do: prevent real data loss, at scale, without paralyzing your organization or your AI initiatives. That’s the real promise behind “Supercharge Your DLP.” You don’t start over, you make the DLP you already have smarter, quieter where it should be, and louder where it counts.
<blogcta-big>
SOC 2 Without the Spreadsheet Chaos: Automating Evidence for Regulated Data Controls
SOC 2 Without the Spreadsheet Chaos: Automating Evidence for Regulated Data Controls
SOC 2 has become table stakes for cloud‑native and SaaS organizations. But for many security and GRC teams, each SOC 2 cycle still feels like starting from scratch; hunting for the latest access reviews, exporting encryption settings from multiple consoles, proving backups and logs exist - per data set, per environment. If your SOC 2 evidence process is still a patchwork of spreadsheets and screenshots, you’re not alone. The missing piece is a data‑centric view of your controls, especially around regulated data.
Why SOC 2 Evidence Is So Hard in Cloud and SaaS Environments
Under SOC 2, trust service criteria like Security, Availability, and Confidentiality translate into specific expectations around data:
Is sensitive or regulated data discovered and classified consistently?
Are core controls (encryption, backup, access, logging) actually in place where that data lives?
Can you show continuous monitoring instead of point‑in‑time screenshots?
In a typical multi‑cloud/SaaS environment:
- Sensitive data is scattered across S3, databases, Snowflake, M365/Google Workspace, Salesforce, and more.
- Different teams own pieces of the puzzle (infra, security, data, app owners).
- Legacy tools are siloed by layer (CSPM for infra, DLP for traffic, privacy catalog for RoPA).
So when SOC 2 comes around, you spend weeks assembling a story instead of being able to show a trusted, provable compliance posture at the data layer.
The Data‑First Approach to SOC 2 Evidence
Instead of treating SOC 2 as a separate project, leading teams are aligning it with their data security posture management (DSPM) strategy:
- Start from the data, not from the infrastructure
- Build a unified inventory of sensitive and regulated data across IaaS, PaaS, SaaS, and on‑prem.
- Enrich each store with sensitivity, residency, and business context.
- Attach control posture to each data store
- For each regulated data store, track encryption status, backup configuration, access model, and logging/monitoring coverage as posture attributes.
- Generate SOC‑aligned evidence from the same system
- Use the regulated‑data inventory plus posture engine to produce SOC 2‑friendly reports and CSVs, rather than collecting evidence manually for each audit cycle.
This is exactly the pattern that modern data security platforms like Sentra are implementing.
How Sentra Helps Security and GRC Teams Automate SOC 2 Evidence
Sentra sits across your data estate and focuses on regulated data, with capabilities that map directly onto SOC 2 evidence needs:
Comprehensive data‑store discovery and classification
Agentless discovery of data stores (managed and unmanaged) across multi‑cloud and on‑prem, combined with high‑accuracy classification for regulated and business‑critical data.
Data‑centric security posture
For each store, Sentra tracks security properties—including encryption, backup, logging, and access configuration, and surfaces gaps where sensitive data is insufficiently protected.
Framework‑aligned reporting
SOC 2 and other frameworks can be represented as report templates that pull directly from Sentra’s inventory and posture attributes, giving GRC teams “audit‑ready” exports without rebuilding evidence from scratch.
The result is you can prove control over regulated data, for SOC 2 and beyond, with far less manual overhead.
Mapping SOC 2 Criteria to Data‑Level Evidence
Here’s how a data‑first posture shows up in SOC 2:
CC6.x (Logical and Physical Access Controls)
Evidence: Identity‑to‑data mapping showing which users/roles can access which sensitive datasets across cloud and SaaS.
CC7.x (Change Management / Monitoring)
Evidence: Data Detection & Response (DDR) signals and anomaly analytics around access to crown‑jewel data; logs that tie back to sensitive data stores.
CC8.x (Risk Mitigation)
Evidence: Risk‑prioritized view of data stores based on sensitivity and missing controls, plus remediation workflows or automatic labeling/tagging to tighten upstream policies.
When this data‑level view is in place, SOC 2 becomes evidence selection rather than evidence construction.
A Repeatable SOC 2 Playbook for Security, GRC, and Privacy
To operationalize this approach, many teams follow a recurring pattern:
- Define a “regulated data perimeter” for SOC 2: Identify which clouds, SaaS platforms, and on‑prem stores contain in‑scope data (PII, PHI, PCI, financial records).
- Instrument with DSPM: Deploy a data security platform like Sentra to discover, classify, and map access to that data perimeter.
- Connect GRC to the same source of truth: Have GRC and privacy teams pull their SOC 2 evidence from the same inventory and posture views Security uses for day‑to‑day risk management.
- Continuously refine controls: Use posture and DDR insights to reduce exposure, close misconfigurations, and improve your next SOC 2 cycle before it starts.
The more you lean on a shared, data‑centric foundation, the easier it becomes to maintain a trusted, provable compliance posture across frameworks, not just SOC 2.
Turning SOC 2 From a Project Into a Capability
Ultimately, the goal is to stop treating SOC 2 as a once-a-year project and start treating it as an ongoing capability embedded into how your organization operates. Security, GRC, and privacy teams should work from a single, unified view of regulated data and controls. Evidence should always be a few clicks away - not the result of a month-long scramble. And every audit should strengthen your data security posture, not distract from it. If you’re still managing compliance in spreadsheets, it’s worth asking what it would take to make your SOC 2 posture something you can prove on demand.
Ready to end the fire drills and move to continuous compliance? Book a Demo
<blogcta-big>
DSPM Dirty Little Secrets: What Vendors Don’t Want You to Test
DSPM Dirty Little Secrets: What Vendors Don’t Want You to Test
Discover What DSPM Vendors Try to Hide
Your goal in running a data security/DSPM POV is to evaluate all important performance and cost parameters so you can make the best decision and avoid unpleasant surprises. Vendors, on the other hand, are looking for a ‘quick win’ and will often suggest shortcuts like using a limited test data set and copying your data to their environment.
On the surface this might sound like a reasonable approach, but if you don’t test real data types and volumes in your own environment, the POV process may hide costly failures or compliance violations that will quickly become apparent in production. A recent evaluation of Sentra versus another top emerging DSPM exposed how the other solution’s performance dropped and costs skyrocketed when deployed at petabyte scale. Worse, the emerging DSPM removed data from the customer environment - a clear controls violation.
If you want to run a successful POV and avoid DSPM buyers' remorse you need to look out for these "dirty little secrets".
Dirty Little Secret #1:
‘Start small’ can mean ‘fails at scale’
The biggest 'dirty secret' is that scalability limits are hidden behind the 'start small' suggestion. Many DSPM platforms cannot scale to modern petabyte-sized data environments. Vendors try to conceal this architectural weakness by encouraging small, tightly scoped POVs that never stress the system and create false confidence. Upon broad deployment, this weakness is quickly exposed as scans slow and refresh cycles stretch, forcing teams to drastically reduce scope or frequency. This failure is fundamentally architectural, lacking parallel orchestration and elastic execution, proving that the 'start small' advice was a deliberate tactic to avoid exposing the platform’s inevitable bottleneck.In a recent POV, Sentra successfully scanned 10x more data in approximately the same time than the alternative:
Dirty Little Secret #2:
High cloud cost breaks continuous security
Another reason some vendors try to limit the scale of POVs is to hide the real cloud cost of running them in production. They often use brute-force scanning that reads excessive data, consumes massive compute resources, and is architecturally inefficient. This is easy to mask during short, limited POVs, but quickly drives up cloud bills in production. The resulting cost pressure forces organizations to reduce scan frequency and scope, quietly shifting the platform from continuous security control to periodic inventory. Ultimately, tools that cannot scale scanners efficiently on-demand or scan infrequently trade essential security for cost, proving they are only affordable when they are not fully utilized. In a recent POV run on 100 petabytes of data, Sentra proved to be 10x more operationally cost effective to run:
Dirty Little Secret #3:
‘Good enough’ accuracy degrades security
Accuracy is fundamental to Data Security Posture Management (DSPM) and should not be compromised. While a few points difference may not seem like a deal breaker, every percentage point of classification accuracy can dramatically affect all downstream security controls. Costs increase as manual intervention is required to address FPs. When organizations automate controls based on these inaccuracies, the DSPM platform becomes a source of risk. Confidence is lost. The secret is kept safe because the POV never validates the platform's accuracy against known sensitive data.
In a recent POV Sentra was able to prove less than one percent rate of false positives and false negatives:
DSPM POV Red Flags
- Copy data to the vendor environment for a “quick win”
- Limit features or capabilities to simplify testing
- Artificially reduce the size of scanned data
- Restrict integrations to avoid “complications”
- Limit or avoid API usage
These shortcuts don’t make a POV easier - they make it misleading.
Four DSPM POV Requirements That Expose the Truth
If you want a DSPM POV that reflects production reality, insist on these requirements:
1. Scalability
Run discovery and classification on at least 1 petabyte of real data, including unstructured object storage. Completion time must be measured in hours or days - not weeks.
2. Cost Efficiency
Operate scans continuously at scale and measure actual cloud resource consumption. If cost forces reduced frequency or scope, the model is unsustainable.
3. Accuracy
Validate results against known sensitive data. Measure false positives and false negatives explicitly. Accuracy must be quantified and repeatable.
4. Unstructured Data Depth
Test long-form, heterogeneous, real-world unstructured data including audio, video, etc. Classification must demonstrate contextual understanding, not just keyword matches.
A DSPM solution that only performs well in a limited POV will lead to painful, costly buyer’s regret. Once in production, the failures in scalability, cost efficiency, accuracy, and unstructured data depth quickly become apparent.
Getting ready to run a DSPM POV? Schedule a demo.
<blogcta-big>
How to Choose a Data Access Governance Tool
How to Choose a Data Access Governance Tool
Introduction: Why Data Access Governance Is Harder Than It Should Be
Data access governance should be simple: know where your sensitive data lives, understand who has access to it, and reduce risk without breaking business workflows. In practice, it’s rarely that straightforward. Modern organizations operate across cloud data stores, SaaS applications, AI pipelines, and hybrid environments. Data moves constantly, permissions accumulate over time, and visibility quickly degrades. Many teams turn to data access governance tools expecting clarity, only to find legacy platforms that are difficult to deploy, noisy, or poorly suited for dynamic, fast-proliferating cloud environments.
A modern data access governance tool should provide continuous visibility into who and what can access sensitive data across cloud and SaaS environments, and help teams reduce overexposure safely and incrementally.
What Organizations Actually Need from Data Access Governance
Before evaluating vendors, it’s important to align on outcomes, just not features. Most teams are trying to solve the same core problems:
- Unified visibility across cloud data stores, SaaS platforms, and hybrid environments
- Clear answers to “which identities have access to what, and why?”
- Risk-based prioritization instead of long, unmanageable lists of permissions
- Safe remediation that tightens access without disrupting workflows
Tools that focus only on periodic access reviews or static policies often fall short in dynamic environments where data and permissions change constantly.
Why Legacy and Over-Engineered Tools Fall Short
Many traditional data governance and IGA tools were designed for on-prem environments and slower change cycles. In cloud and SaaS environments, these tools often struggle with:
- Long deployment timelines and heavy professional services requirements
- Excessive alert noise without clear guidance on what to fix first
- Manual access certifications that don’t scale
- Limited visibility into modern SaaS and cloud-native data stores
Overly complex platforms can leave teams spending more time managing the tool than reducing actual data risk.
Key Capabilities to Look for in a Modern Data Access Governance Tool
1. Continuous Data Discovery and Classification
A strong foundation starts with knowing where sensitive data lives. Modern tools should continuously discover and classify data across cloud, SaaS, and hybrid environments using automated techniques, not one-time scans.
2. Access Mapping and Exposure Analysis
Understanding data sensitivity alone isn’t enough. Tools should map access across users, roles, applications, and service accounts to show how sensitive data is actually exposed.
3. Risk-Based Prioritization
Not all exposure is equal. Effective platforms correlate data sensitivity with access scope and usage patterns to surface the highest-risk scenarios first, helping teams focus remediation where it matters most.
4. Low-Friction Deployment
Look for platforms that minimize operational overhead:
- Agentless or lightweight deployment models
- Fast time-to-value
- Minimal disruption to existing workflows
5. Actionable Remediation Workflows
Visibility without action creates frustration. The right tool should support guided remediation, tightening access incrementally and safely rather than enforcing broad, disruptive changes.
How Teams Are Solving This Today
Security teams that succeed tend to adopt platforms that combine data discovery, access analysis, and real-time risk detection in a single workflow rather than stitching together multiple legacy tools. For example, platforms like Sentra focus on correlating data sensitivity with who or what can actually access it, making it easier to identify over-permissioned data, toxic access combinations, and risky data flows, without breaking existing workflows or requiring intrusive agents.
The common thread isn’t the tool itself, but the ability to answer one question continuously:
“Who can access our most sensitive data right now, and should they?”
Teams using these approaches often see faster time-to-value and more actionable insights compared to legacy systems.
Common Gotchas to Watch Out For
When evaluating tools, buyers often overlook a few critical issues:
- Hidden costs for deployment, tuning, or ongoing services
- Tools that surface risk but don’t help remediate it
- Point-in-time scans that miss rapidly changing environments
- Weak integration with identity systems, cloud platforms, and SaaS apps
Asking vendors how they handle these scenarios during a pilot can prevent surprises later.
Download The Dirt on DSPM POVs: What Vendors Don’t Want You to Know
How to Run a Successful Pilot
A focused pilot is the best way to evaluate real-world effectiveness:
- Start with one or two high-risk data stores
- Measure signal-to-noise, not alert volume
- Validate that remediation steps work with real teams and workflows
- Assess how quickly the tool delivers actionable insights
The goal is to prove reduced risk, not just improved reporting.
Final Takeaway: Visibility First, Enforcement Second
Effective data access governance starts with visibility. Organizations that succeed focus first on understanding where sensitive data lives and how it’s exposed, then apply controls gradually and intelligently. Combining DAG with DSPM is an effective way to achieve this.
In 2026, the most effective data access governance tools are continuous, risk-driven, and cloud-native, helping security teams reduce exposure without slowing the business down.
Frequently Asked Questions (FAQs)
What is data access governance?
Data access governance is the practice of managing and monitoring who can access sensitive data, ensuring access aligns with business needs and security requirements.
How is data access governance different from IAM?
IAM focuses on identities and permissions. Data access governance connects those permissions to actual data sensitivity and exposure, and alerts when violations occur.
How do organizations reduce over-permissioned access safely?
By using risk-based prioritization and incremental remediation instead of broad access revocations.
What should teams look for in a modern data access governance tool?
This question comes up frequently in real-world evaluations, including Reddit discussions where teams share what’s worked and what hasn’t. Teams should prioritize tools that give fast visibility into who can access sensitive data, provide context-aware insights, and allow incremental, safe remediation - all without breaking workflows or adding heavy operational overhead. Cloud- and SaaS-aware platforms tend to outperform legacy or overly complex solutions.
<blogcta-big>

One Platform to Secure All Data: Moving from Data Discovery to Full Data Access Governance
One Platform to Secure All Data: Moving from Data Discovery to Full Data Access Governance
The cloud has changed how organizations approach data security and compliance. Security leaders have mostly figured out where their sensitive data is, thanks to data security posture management (DSPM) tools. But that's just the beginning. Who can access your data? What are they doing with it?
Workloads and sensitive assets now move across multi-cloud, hybrid, and SaaS environments, increasing the need for control over access and use. Regulators, boards, and customers expect more than just awareness. They want real proof that you are governing access, lowering risk, and keeping cloud data secure. The next priority is here: shifting from just knowing what data you have to actually governing access to it. Sentra provides a unified platform designed for this shift.
Why Discovery Alone Falls Short in the Cloud Era
DSPM solutions make it possible to locate, classify, and monitor sensitive data almost anywhere, from databases to SaaS apps. This visibility is valuable, particularly as organizations manage more data than ever. Over half of enterprises have trouble mapping their full data environment, and 85% experienced a data loss event in the past year.
But simply seeing your data won’t do the job. DSPM can point out risks, like unencrypted data or exposed repositories, but it usually can’t control access or enforce policies in real time. Cloud environments change too quickly for static snapshots and scheduled reviews. Effective security means not only seeing your data but actively controlling who can reach it and what they can do.
Data Access Governance: The New Frontier for Cloud Data Security
Data Access Governance (DAG) covers processes and tools that constantly monitor, control, and audit who can access your data, how, and when, wherever it lives in the cloud.
Why does DAG matter so much now? Consider some urgent needs:
- Compliance and Auditability: 82% of organizations rank compliance as their top cloud concern. Data access controls and real-time audit logs make it possible to demonstrate compliance with GDPR, HIPAA, and other data laws.
- Risk Reduction: Cloud environments change constantly, so outdated access policies quickly become a problem. DAG enforces least-privilege access, supports just-in-time permissions, and lets teams quickly respond to risky activity.
- AI and New Threats: As generative AI becomes more common, concerns about misuse and unsupervised data access are growing. Forty percent of organizations now see AI as a data leak risk.
DAG gives organizations a current view of “who has access to my data right now?” for both employees and AI agents, and allows immediate changes if permissions or risks shift.
The Power of a Unified, Agentless Platform for DSPM and DAG
Why should security teams look for a unified platform instead of another narrow tool? Most large companies use several clouds, with 83% managing more than one, but only 34% have unified compliance. Legacy tools focused on discovery or single clouds aren’t enough.
Sentra’s agentless, multi-cloud solution meets these needs directly. With nothing extra to install or maintain, Sentra provides:
- Automated discovery and classification of data in AWS, Azure, GCP, and SaaS
- Real-time mapping and management of every access, from users to services and APIs
- Policy-as-code for dynamic enforcement of least-privilege access
- Built-in detection and response that moves beyond basic rules
This approach combines data discovery with ongoing access management, helping organizations save time and money. It bridges the gaps between security, compliance, and DevOps teams. GlobalNewswire projects the global market for unified data governance will exceed $15B by 2032. Companies are looking for platforms that can keep things simple and scale with growth.
Strategic Benefits: From Reduced Risk to Business Enablement
What do organizations actually achieve with cloud-native, end-to-end data access governance?
- Operational Efficiency: Replace slow, manual reviews and separate tools. Automate access reviews, policy enforcement, and compliance, all in one platform.
- Faster Remediation and Lower TCO: Real-time alerts pinpoint threats faster, and automation speeds up response and reduces resource needs.
- Future-Proof Security: Designed to handle multi-cloud and AI demands, with just-in-time access, zero standing privilege, and fast threat response.
- Business Enablement and Audit Readiness: Central visibility and governance help teams prepare for audits faster, gain customer trust, and safely launch digital products.
In short, a unified platform for DSPM and DAG is more than a tech upgrade, it gives security teams the ability to directly support business growth and agility.
Why Sentra: The Converged Platform for Modern Data Security
Sentra covers every angle: agentless discovery, continuous access control, ongoing threat detection, and compliance, all within one platform. Sentra unites DSPM, DAG, and Data Detection & Response (DDR) in a single solution.
With Sentra, you can:
- Stop relying on periodic reviews and move to real-time governance
- See and manage data across all cloud and SaaS services
- Make compliance easier while improving security and saving money
Conclusion
Data discovery is just the first step to securing cloud data. For compliance, resilience, and agility, organizations need to go beyond simply finding data and actually managing who can use it. DSPM isn’t enough anymore, full Data Access Governance is now a must.
Sentra’s agentless platform gives security and compliance teams a way to find, control, and protect sensitive cloud data, with full oversight along the way. Make the switch now and turn cloud data security into an asset for your business.
Looking to bring all your cloud data security and access control together? Request a Sentra demo to see how it works, or watch a 5-minute product demo for more on how Sentra helps organizations move from discovery to full data governance.
<blogcta-big>
Sentra Is One of the Hottest Cybersecurity Startups
Sentra Is One of the Hottest Cybersecurity Startups
We knew we were on a hot streak, and now it’s official.
Sentra has been named one of CRN’s 10 Hottest Cybersecurity Startups of 2025. This recognition is a direct reflection of our commitment to redefining data security for the cloud and AI era, and of the growing trust forward-thinking enterprises are placing in our unique approach.
This milestone is more than just an award. It shows our relentless drive to protect modern data systems and gives us a chance to thank our customers, partners, and the Sentra team whose creativity and determination keep pushing us ahead.
The Market Forces Fueling Sentra’s Momentum
Cybersecurity is undergoing major changes. With 94% of organizations worldwide now relying on cloud technologies, the rapid growth of cloud-based data and the rise of AI agents have made security both more urgent and more complicated. These shifts are creating demands for platforms that combine unified data security posture management (DSPM) with fast data detection and response (DDR).
Industry data highlights this trend: over 73% of enterprise security operations centers are now using AI for real-time threat detection, leading to a 41% drop in breach containment time. The global cybersecurity market is growing rapidly, estimated to reach $227.6 billion in 2025, fueled by the need to break down barriers between data discovery, classification, and incident response 2025 cybersecurity market insights. In 2025, organizations will spend about 10% more on cyber defenses, which will only increase the demand for new solutions.
Why Recognition by CRN Matters and What It Means
Landing a place on CRN’s 10 Hottest Cybersecurity Startups of 2025 is more than publicity for Sentra. It signals we truly meet the moment. Our rise isn’t just about new features; it’s about helping security teams tackle the growing risks posed by AI and cloud data head-on. This recognition follows our mention as a CRN 2024 Stellar Startup, a sign of steady innovation and mounting interest from analysts and enterprises alike.
Being on CRN’s list means customers, partners, and investors value Sentra’s straightforward, agentless data protection that helps organizations work faster and with more certainty.
Innovation Where It Matters: Sentra’s Edge in Data and AI Security
Sentra stands out for its practical approach to solving urgent security problems, including:
- Agentless, multi-cloud coverage: Sentra identifies and classifies sensitive data and AI agents across cloud, SaaS, and on-premises environments without any agents or hidden gaps.
- Integrated DSPM + DDR: We go further than monitoring posture by automatically investigating incidents and responding, so security teams can act quickly on why DSPM+DDR matters.
- AI-driven advancements: Features like domain-specific AI Classifiers for Unstructure advanced AI classification leveraging SLMs, Data Security for AI Agents and Microsoft M365 Copilot help customers stay in control as they adopt new technologies Sentra’s AI-powered innovation.
With new attack surfaces popping up all the time, from prompt injection to autonomous agent drift, Sentra’s architecture is built to handle the world of AI.
A Platform Approach That Outpaces the Competition
There are plenty of startups aiming to tackle AI, cloud, and data security challenges. Companies like 7AI, Reco, Exaforce, and Noma Security have been in the news for their funding rounds and targeted solutions. Still, very few offer the kind of unified coverage that sets Sentra apart.
Most competitors stick to either monitoring SaaS agents or reducing SOC alerts. Sentra does more by providing both agentless multi-cloud DSPM and built-in DDR. This gives organizations visibility, context, and the power to act in one platform. With features like Data Security for AI Agents, Sentra helps enterprises go beyond managing alerts by automating meaningful steps to defend sensitive data everywhere.
Thanks to Our Community and What’s Next
This honor belongs first and foremost to our community: customers breaking new ground in data security, partners building solutions alongside us, and a team with a clear goal to lead the industry.
If you haven’t tried Sentra yet, now’s a great time to see what we can do for your cloud and AI data security program. Find out why we’re at the forefront: schedule a personalized demo or read CRN’s full 2025 list for more insight.
Conclusion
Being named one of CRN’s hottest cybersecurity startups isn’t just a milestone. It pushes us forward toward our vision - data security that truly enables innovation. The market is changing fast, but Sentra’s focus on meaningful security results hasn't wavered.
Thank you to our customers, partners, investors, and team for your ongoing trust and teamwork. As AI and cloud technology shape the future, Sentra is ready to help organizations move confidently, securely, and quickly.
<blogcta-big>
Third-Party OAuth Apps Are the New Shadow Data Risk: Lessons from the Gainsight/Salesforce Incident
Third-Party OAuth Apps Are the New Shadow Data Risk: Lessons from the Gainsight/Salesforce Incident
The recent exposure of customer data through a compromised Gainsight integration within Salesforce environments is more than an isolated event - it’s a sign of a rapidly evolving class of SaaS supply-chain threats. Even trusted AppExchange partners can inadvertently create access pathways that attackers exploit, especially when OAuth tokens and machine-to-machine connections are involved. This post explores what happened, why today’s security tooling cannot fully address this scenario, and how data-centric visibility and identity governance can meaningfully reduce the blast radius of similar breaches.
A Recap of the Incident
In this case, attackers obtained sensitive credentials tied to a Gainsight integration used by multiple enterprises. Those credentials allowed adversaries to generate valid OAuth tokens and access customer Salesforce orgs, in some cases with extensive read capabilities. Neither Salesforce nor Gainsight intentionally misconfigured their systems. This was not a product flaw in either platform. Instead, the incident illustrates how deeply interconnected SaaS environments have become and how the security of one integration can impact many downstream customers.
Understanding the Kill Chain: From Stolen Secrets to Salesforce Lateral Movement
The attackers’ pathway followed a pattern increasingly common in SaaS-based attacks. It began with the theft of secrets; likely API keys, OAuth client secrets, or other credentials that often end up buried in repositories, CI/CD logs, or overlooked storage locations. Once in hand, these secrets enabled the attackers to generate long-lived OAuth tokens, which are designed for application-level access and operate outside MFA or user-based access controls.
What makes OAuth tokens particularly powerful is that they inherit whatever permissions the connected app holds. If an integration has broad read access, which many do for convenience or legacy reasons, an attacker who compromises its token suddenly gains the same level of visibility. Inside Salesforce, this enabled lateral movement across objects, records, and reporting surfaces far beyond the intended scope of the original integration. The entire kill chain was essentially a progression from a single weakly-protected secret to high-value data access across multiple Salesforce tenants.
Why Traditional SaaS Security Tools Missed This
Incident response teams quickly learned what many organizations are now realizing: traditional CASBs and CSPMs don’t provide the level of identity-to-data context necessary to detect or prevent OAuth-driven supply-chain attacks.
CASBs primarily analyze user behavior and endpoint connections, but OAuth apps are “non-human identities” - they don’t log in through browsers or trigger interactive events. CSPMs, in contrast, focus on cloud misconfigurations and posture, but they don’t understand the fine-grained data models of SaaS platforms like Salesforce. What was missing in this incident was visibility into how much sensitive data the Gainsight connector could access and whether the privileges it held were appropriate or excessive. Without that context, organizations had no meaningful way to spot the risk until the compromise became public.
Sentra Helps Prevent and Contain This Attack Pattern
Sentra’s approach is fundamentally different because it starts with data: what exists, where it resides, who or what can access it, and whether that access is appropriate. Rather than treating Salesforce or other SaaS platforms as black boxes, Sentra maps the data structures inside them, identifies sensitive records, and correlates that information with identity permissions including third-party apps, machine identities, and OAuth sessions.
One key pillar of Sentra’s value lies in its DSPM capabilities. The platform identifies sensitive data across all repositories, including cloud storage, SaaS environments, data warehouses, code repositories, collaboration platforms, and even on-prem file systems. Because Sentra also detects secrets such as API keys, OAuth credentials, private keys, and authentication tokens across these environments, it becomes possible to catch compromised or improperly stored secrets before an attacker ever uses them to access a SaaS platform.
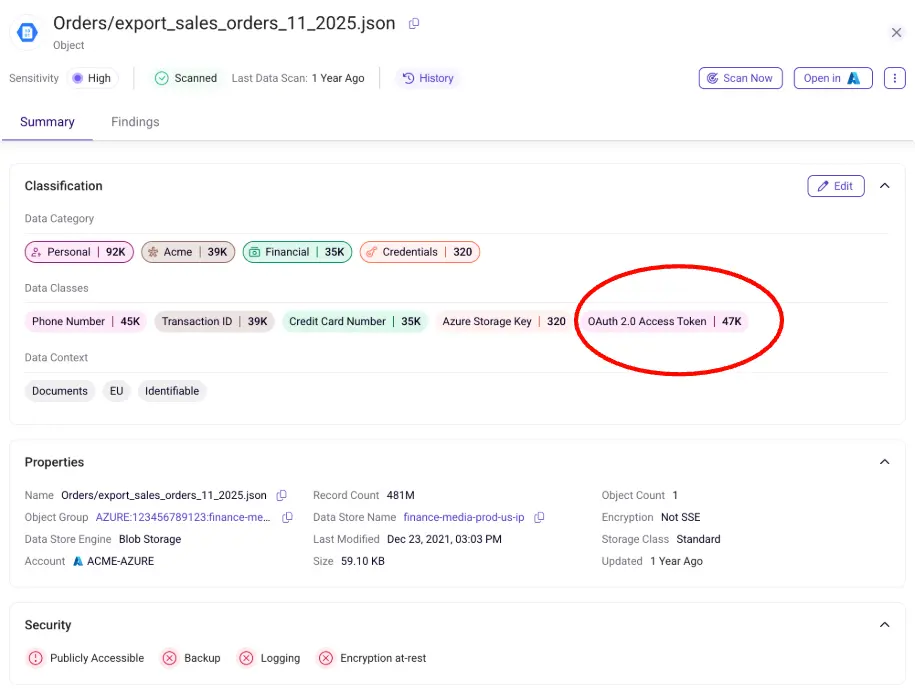
Another area where this becomes critical is the detection of over-privileged connected apps. Sentra continuously evaluates the scopes and permissions granted to integrations like Gainsight, identifying when either an app or an identity holds more access than its business purpose requires. This type of analysis would have revealed that a compromised integrated app could see far more data than necessary, providing early signals of elevated risk long before an attacker exploited it.
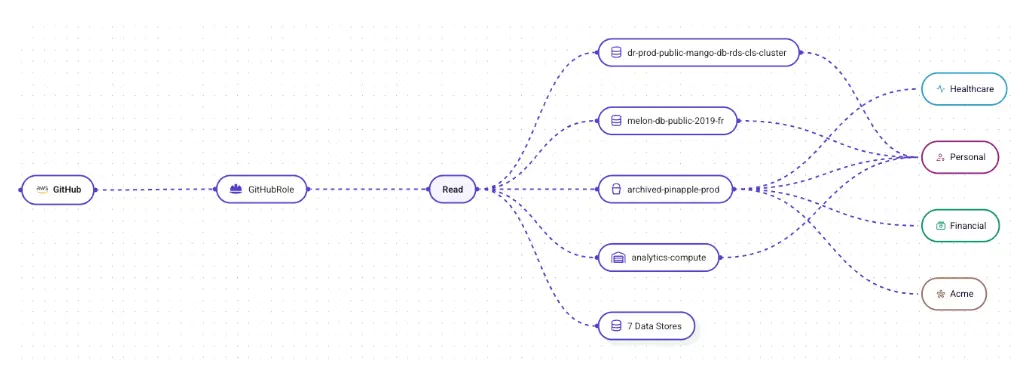
Sentra further tracks the health and behavior of non-human identities. Service accounts and connectors often rely on long-lived credentials that are rarely rotated and may remain active long after the responsible team has changed. Sentra identifies these stale or overly permissive identities and highlights when their behavior deviates from historical norms. In the context of this incident type, that means detecting when a connector suddenly begins accessing objects it never touched before or when large volumes of data begin flowing to unexpected locations or IP ranges.
Finally, Sentra’s behavior analytics (part of DDR) help surface early signs of misuse. Even if an attacker obtains valid OAuth tokens, their data access patterns, query behavior, or geography often diverge from the legitimate integration. By correlating anomalous activity with the sensitivity of the data being accessed, Sentra can detect exfiltration patterns in real time—something traditional tools simply aren’t designed to do.
The 2026 Outlook: More Incidents Are Coming
The Gainsight/Salesforce incident is unlikely to be the last of its kind. The speed at which enterprises adopt SaaS integrations far exceeds the rate at which they assess the data exposure those integrations create. OAuth-based supply-chain attacks are growing quickly because they allow adversaries to compromise one provider and gain access to dozens or hundreds of downstream environments. Given the proliferation of partner ecosystems, machine identities, and unmonitored secrets, this attack vector will continue to scale.
Prediction:
Unless enterprises add data-centric SaaS visibility and identity-aware DSPM, we should expect three to five more incidents of similar magnitude before summer 2026.
Conclusion
The real lesson from the Gainsight/Salesforce breach is not to reduce reliance on third-party SaaS providers as modern business would grind to a halt without them. The lesson is that enterprises must know where their sensitive data lives, understand exactly which identities and integrations can access it, and ensure those privileges are continuously validated. Sentra provides that visibility and contextual intelligence, making it possible to identify the risks that made this breach possible and help to prevent the next one.
<blogcta-big>
Securing the Cloud: Advanced Strategies for Continuous Data Monitoring
Securing the Cloud: Advanced Strategies for Continuous Data Monitoring
In today's digital world, data security in the cloud is essential. You rely on popular observability tools to track availability, performance, and usage—tools that keep your systems running smoothly. However, as your data flows continuously between systems and regions, you need a layer of security that delivers granular insights without disrupting performance.
Cloud service platforms provide the agility and efficiency you expect; however, they often lack the ability to monitor real-time data movement, access, and risk across diverse environments.
This blog post explains how cloud data monitoring strategies protect your data while addressing issues like data sprawl, data proliferation, and unstructured data challenges. Along the way, we will share practical information to help you deepen your understanding and strengthen your overall security posture.
Why Real-Time Cloud Monitoring Matters
In the cloud, data does not remain static. It shifts between environments, services, and geographical locations. As you manage these flows, a critical question arises: "Where is my sensitive cloud data stored?"
Knowing the exact location of your data in real-time is crucial for mitigating unauthorized access, preventing compliance issues, and effectively addressing data sprawl and proliferation.
Risk of Data Misplacement: When Data Is Stored Outside Approved Environments
Misplaced data refers to information stored outside its approved environment. This can occur when data is in unauthorized or unverified cloud instances or shadow IT systems. Such misplacement heightens security risks and complicates compliance efforts.
A simple table can clarify the differences in risk levels and possible mitigation strategies for various data storage environments:
Risk of Insufficient Monitoring: Gaps in Real-Time Visibility of Rapid Data Movements
The high velocity of data flows in vast cloud environments makes tracking data challenging, and traditional monitoring methods may fall short.
The rapid data movement means that data proliferation often outstrips traditional monitoring efforts. Meanwhile, the sheer volume, variety, and velocity of data require risk analysis tools that are built for scale.
Legacy systems typically struggle with these issues, making it difficult for you to maintain up-to-date oversight and achieve a comprehensive security posture. Explore Sentra's blog on data movement risks for additional details.
Limitations of Legacy Data Security Solutions
When evaluating how to manage and monitor cloud data, it’s clear that traditional security tools fall short in today’s complex, cloud-native environments.
Older security solutions (built for the on-prem era!) were designed for static environments, while today's dynamic cloud demands modern, more scalable approaches. Legacy data classification methods, as discussed in this Sentra analysis, also fail to manage unstructured data effectively.
Let’s take a deeper look at their limitations:
- Inadequate data classification: Traditional data classification often relies on manual processes that fail to keep pace with real-time cloud operations. Manual classification is inefficient and prone to error, making it challenging to quickly identify and secure sensitive information.
- Such outdated methods particularly struggle with unstructured data management, leaving gaps in visibility.
- Scalability issues: As your enterprise grows and embraces the cloud, the volume of data you must handle also grows exponentially. When this happens, legacy systems cannot keep up. They lag behind and are slow to respond to potential risks, exposing your company to possible security breaches.
- Modern requirements for cloud data management and monitoring call for solutions that scale with your business.
- High operational costs: Maintaining outdated security tools can be expensive. Legacy systems often incur high operational costs due to manual oversight, taxing cloud compute consumption, and inefficient processes.
- These costs can escalate quickly, especially compared to cloud-native solutions offering automation, efficiency, and streamlined management.
To address these risks, it's essential to have a strategy that shows you how to monitor data as it moves, ensuring that sensitive files never end up in unapproved environments.
Best Practices for Cloud Data Monitoring and Protection
In an era of rapidly evolving cloud environments, implementing a cohesive cloud data monitoring strategy that integrates actionable recommendations is essential. This approach combines automated data discovery, real-time monitoring, robust access governance, and continuous compliance validation to secure sensitive cloud data and address emerging threats effectively.
Automated Data Discovery and Classification
Implementing an agentless, cloud-native solution enables you to continuously discover and classify sensitive data without any performance drawbacks. Automation significantly reduces manual errors and delivers real-time insights for robust and efficient data monitoring.
Benefits include:
- Continuous data discovery and classification
- Fewer manual interventions
- Real-time risk assessment
- Lower operational costs through automation
- Simplified deployment and ongoing maintenance
- Rapid response to emerging risks with minimal disruption
By adopting a cloud-native data security platform, you gain deeper visibility into your sensitive data without adding system overhead.
Real-Time Data Movement Monitoring
To prevent breaches, real-time cloud monitoring is critical. Receiving real-time alerts will empower you to take action quickly and mitigate threats in the event of unauthorized transfers or suspicious activities.
A well-designed monitoring dashboard can visually display data flows, alert statuses, and remediation actions—all of which provide clear, actionable insights. Alerts can also flow directly to remediation platforms such as ITSM or SOAR systems.
In addition to real-time dashboards, implement automated alerting workflows that integrate with your existing incident response tools. This ensures immediate visibility when anomalies occur for a swift and coordinated response. Continuous monitoring highlights any unusual data movement, helping security teams stay ahead of threats in an environment where data volumes and velocities are constantly expanding.
Robust Access Governance
Only authorized parties should be able to access and utilize sensitive data. Maintain strict oversight by enforcing least privilege access and performing regular reviews. This not only safeguards data but also helps you adhere to the compliance requirements of any relevant regulatory standards.
A checklist for robust governance might include:
- Implementation of role-based and attribute-based access control
- Periodic access audits
- Integration with identity management systems
Ensuring Compliance and Data Privacy
Adhering to data privacy regulations that apply to your sector or location is a must. Continuous monitoring and proactive validation will help you identify and address compliance gaps before your organization is hit with a security breach or legal violation. Sentra offers actionable steps related to various regulations to solidify your compliance posture.
Integrating automated compliance checks into your security processes helps you meet regulatory requirements. To learn more about scaling your security infrastructure, refer to Sentra’s guide to achieving exabyte-scale enterprise data security.
Beyond tools and processes, cultivating a security-minded culture is critical. Conduct regular training sessions and simulated breach exercises so that everyone understands how to handle sensitive data responsibly. Encouraging active participation and accountability across the organization solidifies your security posture, bridging the gap between technical controls and human vigilance.
Sentra Addresses Cloud Data Monitoring Challenges
Sentra's platform complements your current observability tools, enhancing them with robust data security capabilities. Let’s explore how Sentra addresses common challenges in cloud data monitoring.
Exabyte-Scale Mastery: Navigating Expansive Data Ecosystems
Sentra’s platform is designed to handle enormous data volumes with ease. Its distributed architecture and elastic scaling provide comprehensive oversight and ensure high performance as data proliferation intensifies. The platform's distributed architecture and elastic scaling capabilities guarantee high performance, regardless of data volume.
Key features:
- Distributed architecture for high-volume data
- Elastic scaling for dynamic cloud environments
- Integration with primary cloud services
Seamless Automation: Transforming Manual Workflows into Continuous Security
By automating data discovery, classification, and monitoring, Sentra eliminates the need for extensive manual intervention. This streamlined approach provides uninterrupted protection and rapid threat response.
Automation is essential for addressing the challenges of data sprawl without compromising system performance.
Deep Insights & Intelligent Validation: Harnessing Context for Proactive Risk Detection
Sentra distinguishes itself by providing deep contextual analysis of your data. Its intelligent validation process efficiently detects anomalies and prioritizes risks, enabling precise and proactive remediation.
This capability directly addresses the primary concern of achieving continuous, real-time monitoring and ensuring precise, efficient data protection.
Unified Security: Integrating with your Existing Systems for Enhanced Protection
One of the most significant advantages of Sentra's platform is its seamless integration with your current SIEM and SOAR tools. This unified approach allows you to maintain excellent observability with your trusted systems while benefiting from enhanced security measures without any operational disruption.
Conclusion
Effective cloud data monitoring is achieved by blending the strengths of your trusted observability tools with advanced security measures. By automating data discovery and classification, establishing real-time monitoring, and enforcing robust access governance, you can safeguard your data against emerging threats.
Elevate your operations with an extra layer of automated, cloud-native security that tackles data sprawl, proliferation, and compliance challenges. After carefully reviewing your current security and identifying any gaps, invest in modern tools that provide visibility, protection, and resilience.
Maintaining cloud security is a continuous task that demands vigilance, innovation, and proactive decision-making. Integrating solutions like Sentra's platform into your security framework will offer robust, scalable protection that evolves with your business needs. The future of your data security is in your hands, so take decisive steps to build a safer, more secure cloud environment.
<blogcta-big>
S3 Bucket Security Best Practices
S3 Bucket Security Best Practices
Amazon S3 is one of the most widely used cloud storage services in the world, and with that scale comes real security responsibility. Misconfigured buckets remain a leading cause of sensitive data exposure in cloud environments, from accidentally public objects to overly permissive policies that go unnoticed for months. Whether you're hosting static assets, storing application data, or archiving compliance records, getting S3 bucket security right is not optional. This guide covers foundational defaults, policy configurations, and practical checklists to give you an actionable reference as of early 2026.
How S3 Bucket Security Works by Default
A common misconception is that S3 buckets are inherently risky. In reality, all S3 buckets are private by default. When you create a new bucket, no public access is granted, and AWS automatically enables Block Public Access settings at the account level.
Access is governed by a layered permission model where an explicit Deny always overrides an Allow, regardless of where it's defined. Understanding this hierarchy is the foundation of any secure configuration:
- IAM identity-based policies, control what actions a user or role can perform
- Bucket resource-based policies, define who can access a specific bucket and under what conditions
- Access Control Lists (ACLs), legacy object-level permissions (AWS now recommends disabling these entirely)
- VPC endpoint policies, restrict which buckets and actions are reachable from within a VPC
AWS recommends setting S3 Object Ownership to "bucket owner enforced," which disables ACLs. This simplifies permission management significantly, instead of managing object-level ACLs across millions of objects, all access flows through bucket policies and IAM, which are far easier to audit.
AWS S3 Security Best Practices
A defense-in-depth approach means layering multiple controls rather than relying on any single setting. Here is the current AWS-recommended baseline:
S3 Bucket Policy Examples for Common Security Scenarios
Bucket policies are JSON documents attached directly to a bucket that define who can access it and under what conditions. Below are the most practically useful examples.
Enforce HTTPS-Only Access
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "RestrictToTLSRequestsOnly",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
],
"Condition": { "Bool": { "aws:SecureTransport": "false" } }
}]
}
Deny Unencrypted Uploads (Enforce KMS)
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "DenyObjectsThatAreNotSSEKMS",
"Principal": "*",
"Effect": "Deny",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::your-bucket-name/*",
"Condition": {
"Null": {
"s3:x-amz-server-side-encryption-aws-kms-key-id": "true" } } }]}
Other Common Patterns
- Restrict to a specific VPC endpoint: Use the aws:sourceVpce condition key to ensure the bucket is only reachable from a designated private network.
- Grant CloudFront OAI access: Allow only the Origin Access Identity principal, keeping objects private from direct URL access while serving them through the CDN.
- IP-based restrictions: Use NotIpAddress with aws:SourceIp to deny requests from outside a trusted CIDR range.
Always use "Version": "2012-10-17" and validate policies through IAM Access Analyzer before deployment to catch unintended access grants.
Enforcing SSL with the s3-bucket-ssl-requests-only Policy
Forcing all S3 traffic over HTTPS is one of the most straightforward, high-impact controls available. The AWS Config managed rule s3-bucket-ssl-requests-only checks whether your bucket policy explicitly denies HTTP requests, flagging non-compliant buckets automatically.
The policy evaluates the aws:SecureTransport condition key. When a request arrives over plain HTTP, this key evaluates to false, and the Deny statement blocks it. This applies to all principals, AWS services, cross-account roles, and anonymous requests alike. Adding the HTTPS-only Deny statement shown in the policy examples section above satisfies both the AWS Config rule and common compliance requirements under PCI-DSS and HIPAA.
Using an S3 Bucket Policy Generator Safely
The AWS Policy Generator is a useful starting point, but generated policies require careful review before going into production. Follow these steps:
- Select "S3 Bucket Policy" as the policy type, then fill in the principal, actions, resource ARN, and conditions (e.g., aws:SecureTransport or aws:SourceIp).
- Check for overly broad principals, avoid "Principal": "*" unless intentional.
- Verify resource ARNs are scoped correctly (bucket-level vs. object-level).
- Use IAM Access Analyzer's "Preview external access" feature to understand the real-world effect before saving.
The generator is a scaffold, security judgment still applies. Never paste generated JSON directly into production without review.
S3 Bucket Security Checklist
Use this consolidated checklist to audit any S3 bucket configuration:
How Sentra Strengthens S3 Bucket Security at Scale
Applying the right bucket policies and IAM controls is necessary, but at enterprise scale, knowing which buckets contain sensitive data, how that data moves, and who can access it becomes the harder problem. This is where cloud data exposure typically occurs: not from a single misconfigured bucket, but from data sprawl across hundreds of buckets that no one has a complete picture of.
Sentra discovers and classifies sensitive data at petabyte scale directly within your environment, data never leaves your control. It maps data movement across S3, identifies shadow data and over-permissioned buckets, and enforces data-driven guardrails aligned with compliance requirements. For organizations adopting AI, Sentra provides the visibility needed to ensure sensitive training data or model outputs in S3 are properly governed. Eliminating redundant and orphaned data typically reduces cloud storage costs by around 20%.
S3 bucket security is not a one-time configuration task. It's an ongoing practice spanning access control, encryption, network boundaries, monitoring, and data visibility. The controls covered here, from enforcing SSL and disabling ACLs to using policy generators safely and maintaining a security checklist, give you a comprehensive framework. As your environment grows, pairing these technical controls with continuous data discovery ensures your security posture scales with your data, not behind it.
How to Evaluate DSPM and DLP for Copilot and Gemini: A Security Architect’s Buyer’s Guide
How to Evaluate DSPM and DLP for Copilot and Gemini: A Security Architect’s Buyer’s Guide
Most security architects didn’t sign up to be AI product managers. Yet that’s what Copilot and Gemini rollouts feel like: “We want this in every business unit, as soon as possible. Make sure it’s safe.”
If you’re being asked to recommend or validate a DSPM platform, or to justify why your existing DLP stack is or isn’t enough, you need a realistic, vendor‑agnostic set of criteria that maps to how Copilot and Gemini actually work.
This guide is written from that perspective: what matters when you evaluate DSPM and DLP for AI assistants, what’s table stakes vs. differentiating, and what you should ask every vendor before you bring them to your steering committee.
1. Start with the AI use cases you actually have
Before you look at tools, clarify your Copilot and/or Gemini scope:
- Are you rolling out Microsoft 365 Copilot to a pilot group, or planning an org‑wide deployment?
- Are you enabling Gemini in Workspace only, or also Gemini for dev teams (Vertex AI, custom LLM apps, RAG)?
- Do you have existing AI initiatives (third‑party SaaS copilots, homegrown assistants) that will access M365 or Google data?
This matters because different tools have very different coverage:
- Some are M365‑centric with shallow Google support.
- Others focus on cloud infrastructure and data warehouses, and barely touch SaaS.
- Very few provide deep, in‑environment visibility across both SaaS and cloud platforms, which is what you need if Copilot/Gemini are just the tip of your AI iceberg.
Define the boundary first; evaluate tools second.
2. Non‑negotiable DSPM capabilities for Copilot and Gemini
When Copilot and Gemini are in scope, “generic DSPM” is not enough. You need specific capabilities that touch how those assistants see and use data.
2.1 Native visibility into M365 and Workspace
At minimum, a viable DSPM platform must:
- Discover and classify sensitive data across SharePoint, OneDrive, Exchange, Teams and Google Drive / shared drives.
- Understand sharing constructs (public/org‑wide links, external guests, shared drives) and relate them to data sensitivity.
- Support unstructured formats including Office docs, PDFs, images, and audio/video files.
Ask vendors:
- “Show me, live, how you discover sensitive data in Teams chats and OneDrive/Drive folders that are Copilot/Gemini‑accessible.”
- “Show me how you handle PDFs, audio, and meeting recordings - not just Word docs and spreadsheets.”
Sentra, for example, was explicitly built to discover sensitive data across IaaS, PaaS, SaaS, and on‑prem, and to handle formats like audio/video and complex PDFs as first‑class sources.
2.2 In‑place, agentless scanning
For many organizations, it’s now a hard requirement that data never leaves their cloud environment for scanning. Evaluate if the vendor scan in‑place within your tenants, using cloud APIs and serverless functions or do they require copying data or metadata into their infrastructure?
Sentra’s architecture is explicitly “data stays in the customer environment”, which is why large, regulated enterprises have standardized on it.
2.3 AI‑grade classification accuracy and context
Copilot and Gemini are only as safe as your labels and identity model. That requires:
- High‑accuracy classification (>98%) across structured and unstructured content.
- The ability to distinguish synthetic vs. real data and to attach rich context: department, geography, business function, sensitivity, owner.
Ask:
- “How do you measure classification accuracy, and on what datasets?”
- “Can you show me how your platform treats, for example, a Zoom recording vs. a scanned PDF vs. a CSV export?”
Sentra uses AI‑assisted models and granular context classes at both file and entity level, which is why customers report >98% accuracy and trust the labels enough to drive enforcement.
3. Evaluating DLP in an AI‑first world
Most enterprises already have DLP: endpoint, email, web, CASB. The question is whether it can handle AI assistants and the honest answer is that DLP alone usually can’t, because:
- It operates blind to real data context, relying on regex and static rules.
- It usually doesn’t see unstructured SaaS stores or AI outputs reliably.
- Policies quickly become so noisy that they get weakened or disabled.
The evaluation question is not “DLP or DSPM?” It’s:
“Which DSPM platform can make my DLP stack effective for Copilot and Gemini, without a rip‑and‑replace?”
Look for:
- Tight integration with Microsoft Purview (for MPIP labels and Copilot DLP) and, where relevant, Google DLP.
- The ability to auto‑apply and maintain labels that DLP actually enforces.
- Support for feeding data context (sensitivity + business impact + access graphs) into enforcement decisions.
Sentra becomes the single source of truth for sensitivity and business impact that existing DLP tools rely on.
4. Scale, performance, and operating cost
AI rollouts increase data volumes and usage faster than most teams expect. A DSPM that looks fine on 50 TB may struggle at 5 PB.
Evaluation questions:
- “What’s your largest production deployment by data volume? How many PB?”
- “How long does an initial full scan take at that scale, and what’s the recurring scan pattern?”
- “What does cloud compute spend look like at 10 PB, 50 PB, 100 PB?”
Sentra customer tests prove ability to scan 9 PB in under 72 hours at 10–1000x greater scan efficiency than legacy platforms, with projected scanning of 100 PB at roughly $40,000/year in cloud compute.
If a vendor can’t answer those questions quantitatively, assume you’ll be rationing scans, which undercuts the whole point of DSPM for AI.
5. Governance, reporting, and “explainability” for architects
Your stakeholders, security leadership, compliance, boards, will ask three things:
- “Where, exactly, can Copilot and Gemini see regulated data?”
- “How do we know permissions and labels are correct?”
- “Can you prove we’re compliant right now, not just at audit time?”
A strong DSPM platform helps you answer those questions without building custom reporting in a SIEM:
- AI‑specific risk views that show AI assistants, datasets, and identities in one place.
- Compliance mappings to frameworks like GLBA, SOX, FFIEC, GDPR, HIPAA, PCI DSS, and state privacy laws.
- Executive‑ready summaries of AI‑related data risk and progress over time (e.g., percentage of regulated data coverage, number of Copilot‑accessible high‑risk stores before vs. after remediation).
Sentra’s AI Data Readiness and continuous compliance materials give a good template for what “explainable DSPM” looks like in practice.
6. Putting it together: A concise RFP checklist
When you boil it down, your evaluation criteria for DSPM/DLP for Copilot and Gemini should include:
- In‑place, multi‑cloud/SaaS discovery with strong M365 and Workspace coverage
- Proven high‑accuracy classification and rich business context for unstructured data
- Identity‑to‑data mapping with least‑privilege insights
- Native integrations with MPIP/Purview and Google DLP, with label automation
- Real‑world scale (PB‑level) and quantified cloud cost
- AI‑aware risk views, compliance mappings, and reporting
Use those as your “table stakes” in RFPs and technical deep dives. You can add vendor‑specific questions on top, but if a tool can’t clear this bar, it will not make Copilot and Gemini genuinely safe - it will just give you more dashboards.
<blogcta-big>
Cloud Data Protection Solutions
Cloud Data Protection Solutions
As enterprises scale cloud adoption and AI integration in 2026, protecting sensitive data across complex environments has never been more critical. Data sprawls across IaaS, PaaS, SaaS, and on-premise systems, creating blind spots that regulators and threat actors are eager to exploit. Cloud data protection solutions have evolved well beyond simple backup and recovery, today's leading platforms combine AI-powered discovery, real-time data movement tracking, access control analysis, and compliance support into unified architectures. Choosing the right solution determines how confidently your organization can operate in the cloud.
Best Cloud Data Protection Solutions
The market spans two distinct categories, each addressing different layers of cloud security.
Backup, Recovery, and Data Resilience
- Druva Data Security Cloud, Rated 4.9 on Gartner with "Customer's Choice" recognition. Centralized backup, archival, disaster recovery, and compliance across endpoints, servers, databases, and SaaS in hybrid/multicloud environments.
- Cohesity DataProtect, Rated 4.7. Automates backup and recovery across on-premises, cloud, and hybrid infrastructures with policy-based management and encryption.
- Veeam Data Platform, Rated 4.6. Combines secure backup with intelligent data insights and built-in ransomware defenses.
- Rubrik Security Cloud, Integrates backup, recovery, and automated policy-driven protection against ransomware and compliance gaps across mixed environments.
- Dell Data Protection Suite, Rated 4.7. Addresses data loss, compliance, and ransomware through backup, recovery, encryption, and deduplication.
Cloud-Native Security and DSPM
- Sentra, Discovers and governs sensitive data at petabyte scale inside your own environment, with agentless architecture, real-time data movement tracking, and AI-powered classification.
- Wiz, Agentless scanning, real-time risk prioritization, and automated mapping to 100+ regulatory frameworks across multi-cloud environments.
- BigID, Comprehensive data discovery and classification with automated remediation, including native Snowflake integration for dynamic data masking.
- Palo Alto Networks Prisma Cloud, Scalable hybrid and multi-cloud protection with AI analytics, DLP, and compliance enforcement throughout the development lifecycle.
- Microsoft Defender for Cloud, Integrated multi-cloud security with continuous vulnerability assessments and ML-based threat detection across Azure, AWS, and Google Cloud.
What Users Say About These Platforms
User feedback as of early 2026 reveals consistent themes across the leading platforms.
Sentra
Pros:
- Data discovery accuracy and automation capabilities are standout strengths
- Compliance and audit preparation becomes significantly smoother, one user described HITECH audits becoming "a breeze"
- Classification engine reduces manual effort and improves overall efficiency
Cons:
- Initial dashboard experience can feel overwhelming
- Some limitations in on-premises coverage compared to cloud environments
- Third-party sync delays flagged by a subset of users
Rubrik
Pros:
- Strong visibility across fragmented environments with advanced encryption and data auditing
- Frequently described as a top choice for cybersecurity professionals managing multi-cloud
Cons:
- Scalability limitations noted by some reviewers
- Integration challenges with mature SaaS solutions
Wiz
Pros:
- Agentless deployment and multi-cloud visibility surface risk context quickly
Cons:
- Alert overload and configuration complexity require careful tuning
BigID
Pros:
- Comprehensive data discovery and privacy automation with responsive customer service
Cons:
- Delays in technical support and slower DSAR report generation reported
As of February 2026, none of these platforms have published Trustpilot scores with sufficient review counts to generate a verified aggregate rating.
How Leading Platforms Compare on Core Capabilities
Cloud Data Security Best Practices
Selecting the right platform is only part of the equation. How you configure and operate it determines your actual security posture.
- Apply the shared responsibility model correctly. Cloud providers secure infrastructure; you are responsible for your data, identities, and application configurations.
- Enforce least-privilege access. Use role-based or attribute-based access controls, require MFA, and regularly audit permissions.
- Encrypt data at rest and in transit. Use TLS 1.2+ and manage keys through your provider's KMS with regular rotation.
- Implement continuous monitoring and logging. Real-time visibility into access patterns and anomalous behavior is essential. CSPM and SIEM tools provide this layer.
- Adopt zero-trust architecture. Continuously verify identities, segment workloads, and monitor all communications regardless of origin.
- Eliminate shadow and ROT data. Redundant, obsolete, and trivial data increases your attack surface and storage costs. Automated identification and removal reduces risk and cloud spend.
- Maintain and test an incident response plan. Documented playbooks with defined roles and regular simulations ensure rapid containment.
Top Cloud Security Tools for Data Protection
Beyond the major platforms, several specialized tools are worth integrating into a layered defense strategy:
- Check Point CloudGuard, ML-powered threat prevention for dynamic cloud environments, including ransomware and zero-day mitigation.
- Trend Micro Cloud One, Intrusion detection, anti-malware, and firewall protections tailored for cloud workloads.
- Aqua Security, Specializes in containerized and cloud-native environments, integrating runtime threat prevention into DevSecOps workflows for Kubernetes, Docker, and serverless.
- CrowdStrike Falcon, Comprehensive CNAPP unifying vulnerability management, API security, and threat intelligence.
- Sysdig, Secures container images, Kubernetes clusters, and CI/CD pipelines with runtime threat detection and forensic analysis.
- Tenable Cloud Security, Continuous monitoring and AI-driven threat detection with customizable security policies.
Complementing these tools with CASB, DSPM, and IAM solutions creates a layered defense addressing discovery, access control, threat detection, and compliance simultaneously.
How Sentra Approaches Cloud Data Protection
For organizations that need to go beyond backup into true cloud data security, Sentra offers a fundamentally different architecture. Rather than routing data through an external vendor, Sentra scans in-place, your sensitive data never leaves your environment. This is particularly relevant for regulated industries where data residency and sovereignty are non-negotiable.
Key Capabilities
- Purely agentless onboarding, No sidecars, no agents, zero impact on production latency
- Unified view across IaaS, PaaS, SaaS, and on-premise file shares with continuous discovery and classification at petabyte scale
- DataTreks™, Creates an interactive map of your data estate, tracking how sensitive data moves through ETL processes, migrations, backups, and AI pipelines
- Toxic combination detection, Correlates data sensitivity with access controls, flagging high-sensitivity data behind overly permissive policies
- AI governance guardrails, Prevents unauthorized AI access to sensitive data as enterprises integrate LLMs and other AI systems
In documented deployments, Sentra has processed 9 petabytes in under 72 hours and analyzed 100 petabytes at approximately $40,000. Its data security posture management approach also eliminates shadow and ROT data, typically reducing cloud storage costs by around 20%.
Choosing the Right Fit
The right solution depends on the problem you're solving. If your primary need is backup, recovery, and ransomware resilience, Druva, Veeam, Cohesity, and Rubrik are purpose-built for that. If your challenge is discovering where sensitive data lives and how it moves, particularly for AI adoption or regulatory audits, DSPM-focused platforms like Sentra and BigID are better aligned. For automated compliance mapping across GDPR, HIPAA, and the EU AI Act, Wiz's 100+ built-in framework assessments offer a clear advantage.
Most mature security programs layer multiple tools: a backup platform for resilience, a DSPM solution for data visibility and governance, and a CNAPP or CSPM tool for infrastructure-level threat detection. The key is ensuring these tools share context rather than creating additional silos. As data environments grow more complex and AI workloads introduce new vectors for exposure, investing in cloud data protection solutions that provide genuine visibility, not just coverage, will define which organizations operate with confidence.
<blogcta-big>
BigID vs Sentra: A Cloud‑Native DSPM Built for Security Teams
BigID vs Sentra: A Cloud‑Native DSPM Built for Security Teams
When “Enterprise‑Grade” Becomes Too Heavy
BigID helped define the first generation of data discovery and privacy governance platforms. Many large enterprises use it today for PI/PII mapping, RoPA, and DSAR workflows.
But as environments have shifted to multi‑cloud, SaaS, AI, and massive unstructured data, a pattern has emerged in conversations with security leaders and teams:
- Long, complex implementations that depend on professional services
- Scans that are slow or brittle at large scale
- Noisy classification, especially on unstructured data in M365 and file shares
- A UI and reporting model built around privacy/GRC more than day‑to‑day security
- Capacity‑based pricing that’s hard to justify if you don’t fully exploit the platform
Security leaders are increasingly asking:
“If we were buying today, for security‑led DSPM in a cloud‑heavy world, would we choose BigID again, or something built for today’s reality?”
This page gives a straight comparison of BigID vs Sentra through a security‑first lens: time‑to‑value, coverage, classification quality, security use cases, and ROI.
BigID in a Nutshell
Strengths
- Strong privacy, governance, and data intelligence feature set
- Well‑established brand with broad enterprise adoption
- Deep capabilities for DSARs, RoPA, and regulatory mapping
Common challenges security teams report
- Implementation heaviness: significant setup, services, and ongoing tuning
- Performance issues: slow and fragile scans in large or complex estates
- Noise: high false‑positive rates for some unstructured and cloud workloads
- Privacy‑first workflows: harder to operationalize for incident response and DSPM‑driven remediation
- Enterprise‑grade pricing: capacity‑based and often opaque, with costs rising as data and connectors grow
If your primary mandate is privacy and governance, BigID may still be a fit. If your charter is data security; reducing cloud and SaaS risk, supporting AI, and unifying DSPM with detection and access governance, Sentra is built for that outcome.
See Why Enterprises Chose Sentra Over BigID.
Sentra in a Nutshell
Sentra is a cloud‑native data security platform that unifies:
- DSPM – continuous data discovery, classification, and posture
- Data Detection & Response (DDR) – data‑aware threat detection and monitoring
- Data Access Governance (DAG) – identity‑to‑data mapping and access control
Key design principles:
- Agentless, in‑environment architecture: connect via cloud/SaaS APIs and lightweight on‑prem scanners so data never leaves your environment.
- Built for cloud, SaaS, and hybrid: consistent coverage across AWS, Azure, GCP, data warehouses/lakes, M365, SaaS apps, and on‑prem file shares & databases.
- High‑fidelity classification: AI‑powered, context‑aware classification tuned for both structured and unstructured data, designed to minimize false positives.
- Security‑first workflows: risk scoring, exposure views, identity‑aware permissions, and data‑aware alerts aligned to SOC, cloud security, and data security teams.
If you’re looking for a BigID alternative that is purpose-built for modern security programs, not just privacy and compliance teams, this is where Sentra pulls ahead as a clear leader.
BigID vs Sentra at a Glance
Time‑to‑Value & Implementation
BigID
- Often treated as a multi‑quarter program, with POCs expanding into large projects.
- Connectors and policies frequently rely on professional services and specialist expertise.
- Day‑2 operations (scan tuning, catalog curation, workflow configuration) can require a dedicated team.
Sentra
- Installs quickly in minutes with an agentless, API‑based deployment model, so teams start seeing classifications and risk insights almost immediately.
- Provides continuous, autonomous data discovery across IaaS, PaaS, DBaaS, SaaS, and on‑prem data stores, including previously unknown (shadow) data, without custom connectors or heavy reconfiguration.
- Scans hundreds of petabytes and any size of data store in days while remaining highly compute‑efficient, keeping operational costs low.
- Ships with robust, enterprise‑ready scan settings and a flexible policy engine, so security and data teams can tune coverage and cadence to their environment without vendor‑led projects.
If your BigID rollout has stalled or never moved beyond a handful of systems, Sentra’s “install‑in‑minutes, immediate‑value” model is a very different experience.
Coverage: Cloud, SaaS, and On‑Prem
BigID
- Strong visibility across many enterprise data sources, especially structured repositories and data catalogs.
- In practice, customers often cite coverage gaps or operational friction in:
- M365 and collaboration suites
- Legacy file shares and large unstructured repositories
- Hybrid/on‑prem environments alongside cloud workloads
Sentra
- Built as a cloud‑native data security platform that covers:
- IaaS/PaaS: AWS, Azure, GCP
- Data platforms: warehouses, lakes, DBaaS
- SaaS & collaboration: M365 (SharePoint, OneDrive, Teams, Exchange) and other SaaS
- On‑prem: major file servers and relational databases via in‑environment scanners
- Designed so that hybrid and multi‑cloud environments are the norm, not an edge case.
If you’re wrestling with a mix of cloud, SaaS, and stubborn on‑prem systems, Sentra’s ability to treat all of that as one data estate is a big advantage.
Classification Quality & Noise
BigID
- Strong foundation for PI/PII discovery and privacy use cases, but security teams often report:
- High volumes of hits that require manual triage
- Lower precision across certain unstructured or non‑traditional sources
- Over time, this can erode trust because analysts spend more time triaging than remediating.
Sentra
- Uses advanced NLP and model‑driven classification to understand context as well as content.
- Tuned to deliver high precision and recall for both structured and unstructured data, reducing false positives.
- Enriches each finding with rich context e.g.; business purpose, sensitivity, access, residency, security controls, so security teams can make faster decisions.
The result: shorter, more accurate queues of issues, instead of endless spreadsheets of ambiguous hits.
Use Cases: Privacy Catalog vs Security Control Plane
BigID
- Excellent for:
- DSAR handling and privacy workflows
- RoPA and compliance mapping
- High‑level data inventories for audit and governance
- For security‑specific use cases (DSPM, incident response, insider risk), teams often end up:
- Exporting BigID findings into SIEM/SOAR or other tools
- Building custom workflows on top, or supplementing with a separate platform
Sentra
Designed from day one as a data‑centric security control plane, not just a catalog:
- DSPM: continuous mapping of sensitive data, risk scoring, exposure views, and policy enforcement.
- DDR: data‑aware threat detection and activity monitoring across cloud and SaaS.
- DAG: mapping of human and machine identities to data, uncovering over‑privileged access and toxic combinations.
- Integrates with SIEM, SOAR, IAM/CIEM, CNAPP, CSPM, DLP, and ITSM to push data context into the rest of your stack.
Pricing, Economics & ROI
BigID
- Typically capacity‑based and custom‑quoted.
- As you onboard more data sources or increase coverage, licensing can climb quickly.
- When paired with heavier implementation and triage cost, some organizations find it hard to defend renewal spend.
Sentra
- Architecture and algorithms are optimized so the platform can scan very large estates efficiently, which helps control both infrastructure and license costs.
- By unifying DSPM, DDR, and data access governance, Sentra can collapse multiple point tools into one platform.
- Higher classification fidelity and better automation translate into:
- Less analyst time wasted on noise
- Faster incident containment
- Smoother, more automated audits
For teams feeling the squeeze of BigID’s TCO, an evaluation with Sentra often shows better security outcomes per dollar, not just a different line item.
When to Choose BigID vs Sentra
BigID may be the better fit if:
- Your primary buyer and owner are privacy, legal, or data governance teams.
- You need a feature‑rich privacy platform first, with security as a secondary concern.
- You’re comfortable with a more complex, services‑led deployment and ongoing management model.
Sentra is likely the better fit if:
- You are a security org leader (CISO, Head of Cloud Security, Director of Data Security).
- Your top problems are cloud, SaaS, AI, and unstructured data risk, not just privacy reporting.
- You want a BigID alternative that:
- Deploys agentlessly in days
- Handles hybrid/multi‑cloud by design
- Unifies DSPM, DDR, and access governance into one platform
- Reduces noise and drives measurable risk reduction
Next Step: Run a Sentra POV Against Your Own Data
The clearest way to compare BigID and Sentra is to see how each performs in your actual environment. Run a focused Sentra POV on a few high‑value domains (e.g., key cloud accounts, M365, a major warehouse) and measure time‑to‑value, coverage, noise, and risk reduction side by side.
Check out our guide, The Dirt on DSPM POVs, to structure the evaluation so vendors can’t hide behind polished demos.
<blogcta-big>
Enterprise Data Security
Enterprise Data Security
Enterprise Data Security has evolved from a back-office IT concern into a strategic imperative that defines how organizations compete, innovate, and maintain trust in 2026. As businesses accelerate their adoption of cloud infrastructure, artificial intelligence, and distributed work models, the attack surface has expanded exponentially. Modern enterprises face a dual challenge: securing petabytes of data scattered across hybrid environments while enabling rapid access for AI-driven analytics and collaboration tools. This article explores the comprehensive strategies and architectures that define effective Enterprise Data Security today.
What is Enterprise Data Security?
Enterprise Data Security refers to the comprehensive set of policies, technologies, and processes designed to protect an organization's sensitive information from unauthorized access, breaches, and misuse across all environments, whether on-premises, in the cloud, or within SaaS applications. Unlike traditional perimeter-based security, modern enterprise data security operates on a data-centric model that follows information wherever it moves, ensuring protection is embedded at the data layer rather than relying solely on network boundaries.
The scope encompasses several critical components:
- Data discovery and classification that identifies and categorizes sensitive assets
- Access governance that enforces least-privilege principles and monitors who can reach what data
- Encryption and tokenization that protect data at rest and in transit
- Continuous monitoring that detects anomalous behavior and potential threats in real time
Legal compliance is inseparable from this framework. Regulations such as GDPR, HIPAA, CCPA, and the emerging EU AI Act mandate strict controls over personal data, health information, and AI training datasets, making compliance a fundamental architectural requirement rather than a checkbox exercise.
Why Enterprise Data Security Matters
Organizations today face an unprecedented threat landscape where digital communications and cloud adoption have dramatically increased exposure to cyberattacks, insider threats, and accidental data leaks. A single breach can result in millions of dollars in regulatory fines, irreparable damage to brand reputation, and loss of customer trust. These are all consequences that extend far beyond immediate financial impact.
Proactive data security is essential because reactive measures are no longer sufficient. Attackers exploit misconfigurations, over-permissioned access, and shadow data (forgotten or redundant information that accumulates in cloud storage) to gain footholds within enterprise environments. By the time a breach is detected through traditional means, sensitive data may have already been exfiltrated or encrypted for ransom.
Beyond threat mitigation, enterprise data security enables business innovation. Organizations that maintain complete visibility and control over their data can confidently adopt AI technologies, knowing that sensitive information won't inadvertently train public models or leak through AI-generated outputs. Secure data governance also reduces cloud storage costs by identifying and eliminating redundant, obsolete, or trivial (ROT) data; organizations typically achieve storage cost reductions of approximately 20% while simultaneously improving their security posture.
Enterprise Security Architecture
Modern enterprise security architecture is built on multiple layers of defense that work together to protect data throughout its lifecycle. At the foundation lies network security, including next-generation firewalls that inspect traffic at the application layer, intrusion detection and prevention systems, and secure web gateways that filter malicious content. However, as data increasingly resides outside traditional network perimeters, the architecture has shifted toward identity-centric and data-centric models.
Core Architectural Components
- Multi-factor authentication (MFA) requiring users to verify identity through multiple independent credentials before accessing sensitive systems
- Identity and access management (IAM) platforms that enforce role-based access controls and continuously evaluate permissions to prevent privilege creep
- Sandboxing and micro-segmentation that isolate workloads and limit lateral movement within networks
- Encryption technologies that protect data both at rest and in transit
A critical architectural element in 2026 is the in-environment data security platform. Unlike legacy solutions that require data to be copied to vendor-controlled clouds for analysis, modern architectures scan and classify data in place, within the customer's own infrastructure. This approach eliminates the risk of sensitive data leaving organizational control during security assessments and aligns with regulatory requirements for data residency and sovereignty.
Prevent Sensitive Data Exposure
Preventing sensitive data exposure requires a systematic approach that begins with discovery and classification. Organizations must first determine which data is truly sensitive; whether its personally identifiable information (PII), protected health information (PHI), financial records, or intellectual property, and classify it according to regulatory requirements and business risk.
Key Prevention Strategies
- Data minimization: Only retain information strictly necessary for business operations
- Tokenization and truncation: Replace sensitive data with non-sensitive substitutes or remove unnecessary portions
- Consistent encryption: Apply strong encryption algorithms across all data states
- Least-privilege access: Ensure users and systems can only access minimum information needed for their roles
Identifying "toxic combinations" is particularly important: scenarios where high-sensitivity data sits behind broad or over-permissioned access controls. Modern platforms dynamically map and correlate data sensitivity with access permissions, flagging cases where critical information is accessible to overly broad groups like "Everyone" or "Authenticated Users." By continuously monitoring these relationships and providing remediation guidance, organizations can secure vulnerable data before it's exploited.
Secure and Responsible AI
As organizations rapidly adopt AI technologies, implementing secure and responsible AI practices has become a cornerstone of enterprise data security. AI systems, particularly large language models (LLMs) and generative AI tools, require access to vast amounts of data for training and inference, creating new vectors for data exposure if not properly governed.
The first step is establishing complete visibility into AI deployments. Organizations must discover and inventory all AI copilots and agents operating within their environment, including tools like Microsoft 365 Copilot and Google Gemini, and map exactly which data sources and knowledge bases these systems can access. This visibility is essential because AI tools inherit the permissions of the users who deploy them, meaning that misconfigured access controls can allow AI to surface sensitive information that should remain restricted.
AI Governance Essentials
- Enforce policies that restrict which datasets can be used for AI training or inference
- Track data movement between regions, environments, and into AI pipelines
- Implement role-based access controls specifically designed for AI agents
- Monitor AI-driven interactions continuously and automate remediation when policies are violated
By embedding these controls into AI adoption strategies, enterprises can unlock the productivity benefits of AI while maintaining strict data protection standards.
Continuous Regulatory Compliance
Maintaining continuous regulatory compliance demands an integrated system that embeds compliance into daily operations rather than treating it as a periodic audit exercise. In January 2026, regulatory frameworks are more complex and demanding than ever, with overlapping requirements from GDPR, HIPAA, CCPA, SOC 2, ISO 27001, and the new EU AI Act, among others.
Ongoing monitoring and automation form the backbone of continuous compliance. Systems must continuously scan environments for sensitive data, automatically classify it according to regulatory categories, and generate real-time alerts when compliance violations occur. Automated audit logging captures every access event, configuration change, and data movement, creating an immutable trail of evidence that auditors can review at any time.
Compliance Best Practices
Securing Enterprise Data with Sentra
Sentra is a cloud-native data security platform built for the AI era, delivering AI-ready data governance and compliance by discovering and governing sensitive data at petabyte scale inside your own environment. Instead of copying data into a vendor cloud, Sentra runs scanners in your cloud and on-premises environments, so sensitive content never leaves your control.
Key capabilities: Sentra provides a unified view of sensitive data across IaaS, PaaS, SaaS, data lakes/warehouses, and on‑premises file shares, using AI-powered classification with extremely high accuracy for structured and unstructured data. The platform automatically infers data perimeters (environment, region, account type, etc.) and builds an interactive picture of your data estate, not just where sensitive data lives, but how it moves and changes risk as it travels between clouds, regions, environments, collaboration tools, and AI pipelines.
By correlating data sensitivity, identity, and access controls, Sentra identifies toxic combinations where high‑sensitivity data sits behind broad or over‑permissioned access, including large groups and AI assistants that can traverse permissive ACLs. It continuously monitors permissions, file attributes, and access behavior, then prescribes concrete remediation actions so teams can eliminate risky exposure before it’s exploited. This data‑centric approach is especially critical for AI initiatives: Sentra inventories copilots and agents, maps what they can see, and enforces data‑driven guardrails that control what AI is allowed to do with specific data classes (e.g., no‑summarize / no‑export for highly sensitive content).
Sentra integrates deeply with the Microsoft ecosystem, including Microsoft 365, Purview Information Protection, Azure, and Microsoft 365 Copilot. It automatically classifies and labels sensitive data with high accuracy, then uses those labels to drive policy enforcement via Purview DLP and other downstream controls, ensuring consistent protection across SharePoint, OneDrive, Teams, and broader Microsoft data estates.
Beyond risk reduction, Sentra delivers measurable business value by eliminating shadow data and redundant, obsolete, or trivial (ROT) data, typically cutting cloud storage footprints by around 20% while shrinking the overall data attack surface. Combined with improved compliance readiness and AI‑aware governance, Sentra becomes a strategic platform for enterprises that need to adopt AI securely while maintaining full ownership and control over their most sensitive data.
Conclusion
Enterprise Data Security in 2026 demands a fundamental shift from perimeter-based defenses to data-centric architectures that follow information wherever it moves. Organizations must implement comprehensive strategies that combine automated discovery and classification, proactive threat prevention, continuous compliance monitoring, and secure AI governance. The challenges are significant; data sprawl, toxic permission combinations, unstructured data classification at scale, and the rapid adoption of AI tools all create new attack vectors that traditional security approaches cannot adequately address.
Success requires platforms that provide unified visibility across hybrid environments without compromising data sovereignty, that track data movement in real time to detect risky flows, and that enforce granular access controls aligned with least-privilege principles. By embedding security into every phase of the data lifecycle, from creation and storage to processing and deletion, enterprises can confidently pursue digital transformation and AI innovation while maintaining the trust of customers, partners, and regulators.
<blogcta-big>
BigID Alternatives: 7 Modern DSPM Platforms Compared
BigID Alternatives: 7 Modern DSPM Platforms Compared
Why Teams Look for a BigID Alternative
BigID has become a well‑known name in data privacy, governance, and discovery. But as buyer expectations shift toward security‑first DSPM and cloud data protection, a growing number of teams are actively exploring competitors because they:
- Struggle with slow or brittle scans as environments grow
- Are overwhelmed by noisy data classification, especially on unstructured data
- Need deeper cloud, SaaS, and hybrid coverage than they’re getting today
- Want a platform designed around security operations, not only privacy workflows
- Are squeezed by capacity‑based, enterprise‑heavy pricing and services costs
If that sounds familiar, you’re in the right place. Below are 7 BigID alternatives, plus a simple framework to help you decide which one best fits your use case.
What to Look For in a BigID Alternative
Before we list vendors, it’s worth crystallizing evaluation criteria.
For most organizations rethinking BigID, the right alternative will:
- Deploy with low friction: Agentless or light‑touch integration; days, not quarters, to value.
- Cover your real estate: Cloud, SaaS, and (if relevant) on‑prem file shares/DBs and data lakes.
- Deliver high‑precision classification: Especially for unstructured data and AI/LLM workloads.
- Support top concern use cases: AI Data Readiness, Continuous Compliance, and Supercharge Your DLP
- Offer transparent, scalable economics: Predictable pricing and clear value as you grow.
Keep that lens in mind as you review the options below.
1. Sentra – Best Overall BigID Alternative for Security‑Led DSPM
Best for: Security‑first teams that need a cloud‑native data security platform spanning DSPM, DDR, and data access governance across cloud, SaaS, and hybrid that is highly accurate at discovering and classifying unstructured data at massive scale.
Why teams choose Sentra after BigID
- Security‑built, not privacy‑retrofit: Sentra is designed as a data security platform that unifies:
- Modern coverage: Agentless, in‑environment connections across:
- AWS, Azure, GCP
- Data warehouses and lakes
- SaaS & collaboration (M365, and other key SaaS apps)
- On‑prem file shares and databases
- High‑fidelity classification: AI/NLP‑driven, context‑rich classification to reduce false positives and make findings actionable, particularly on unstructured and AI‑related data.
- Security workflow fit: Risk scoring, exposure dashboards, data-aware alerts, and integrations into SIEM, SOAR, IAM/CIEM, CNAPP, and DLP.
When Sentra is the right BigID alternative
- You’ve hit BigID’s limits around scan performance, noise, or cloud/SaaS depth.
- You’re looking to move from a privacy catalog to a security control plane with measurable risk reduction.
2. Securiti – Strong for Privacy + Data Command Center
Best for: Organizations that want a broad “data command center” for privacy, security, and compliance, and can handle a heavier, platform‑style deployment.
Strengths vs BigID
- Comparable ambition around privacy, governance, and data intelligence, with strong consent and DSAR capabilities.
- Rich feature set and templates aligned to global privacy regulations.
- Good fit where privacy ops and GRC are co‑owners with security.
Tradeoffs
- Can feel heavy and complex to implement and operate, similar to BigID.
- Security‑ops‑oriented DSPM and real‑time detection remain less opinionated than some security‑first platforms.
When to favor Securiti over BigID
- You want a unified privacy + governance hub and are already oriented toward a platform‑style privacy stack.
- You have strong internal resources or partner support for implementation.
3. Cyera – Cloud‑Centric DSPM Peer
Best for: Organizations that want a cloud‑first DSPM with strong discovery across cloud data stores and are largely public‑cloud‑centric.
Strengths vs BigID
- Faster, more cloud‑native deployment than legacy discovery tools.
- Clear positioning around cloud DSPM and risk views.
Tradeoffs
- Emphasis is primarily on cloud data stores; depth for unstructured, SaaS, hybrid, and AI/ML workloads may require close evaluation.
- Less focused on unified DDR and access governance than a full data security platform.
When to favor Cyera over BigID
- You are heavily public‑cloud focused and primarily need DSPM for IaaS/PaaS and data platforms.
- Privacy, DSAR, and governance workflows are secondary to cloud security.
4. Varonis – Legacy DSP for File Systems & On‑Prem
Best for: On‑prem and file‑centric environments, especially where traditional file servers, NAS, and Windows shares remain central.
Strengths vs BigID
- Deep heritage in file‑based data security, permissions analytics, and insider risk in on‑prem Windows/NetApp environments.
- Strong access governance and remediation at the file system layer.
Tradeoffs
- Less natural fit for multi‑cloud and SaaS‑heavy architectures.
- Heavier deployment model; not as cloud‑native or agentless as newer DSPM platforms.
When to favor Varonis over BigID
- Your priority is on‑prem file/system security, and you’re comfortable pairing it with separate tools for cloud DSPM.
- You value mature file/permissions analytics and are not primarily cloud‑native.
5. OneTrust – Privacy, Governance & Trust Platform
Best for: Enterprises that see trust, privacy, ESG, and governance as a unified charter and want a broad platform, with security as one piece of the story.
Strengths vs BigID
- Very broad capabilities across privacy, GRC, ESG, and trust intelligence.
- Flexible configuration for multi‑framework compliance.
Tradeoffs
- Like BigID, OneTrust can be complex and contract‑heavy.
- Security‑led DSPM is not the primary lens; it’s more a component of a larger trust platform.
When to favor OneTrust over BigID
- Your driving force is a privacy + trust office, not the CISO team.
- You want a wide governance platform with DSPM as one of many modules.
6. TrustArc / Osano / Captain Compliance – Lighter Privacy Ops Alternatives
Best for: Organizations primarily shopping for lighter‑weight privacy/compliance tooling like cookie consent, DSAR, RoPA, rather than full DSPM.
Strengths vs BigID
- Simpler, more affordable options for privacy compliance at SMB to upper‑mid‑market scale.
- Faster stand‑up for consent banners, privacy notices, and DSAR workflows.
Tradeoffs
- Not substitutes for enterprise‑grade DSPM or data security platforms.
- Much shallower discovery and risk visibility than BigID, Sentra, or other DSPM tools.
When to favor these tools over BigID
- You’ve realized BigID is overkill for your needs, and your main problem is privacy compliance automation, not comprehensive data security.
- Security teams plan to address DSPM separately.
7. Strac, Wiz, and Other DSPM‑Enabled Security Platforms
There’s a final category of BigID alternatives that matter in some buying cycles:
- Strac: Strong emphasis on SaaS DLP + DSPM for collaboration apps, real‑time remediation, and browser/endpoint controls. Good if your main problem is in‑app DLP for SaaS and GenAI.
- Wiz (with DSPM module): CNAPP platform that added DSPM capabilities. Works best when you want to tie data risk to cloud infrastructure and application risk in one place.
These tools can be good alternatives or complements depending on whether your anchor is application/cloud platform security (CNAPP) or SaaS DLP, rather than a deep data‑first security platform.
How to Decide: A Simple “BigID Alternatives” Decision Guide
Ask yourself three quick questions:
- Who owns the problem?
- Privacy/GRC/legal → consider BigID, Securiti, OneTrust, or lighter privacy tools.
- Security/CISO/cloud security → look hard at Sentra, Cyera, Wiz.
- What’s your environment reality?
- Primarily on‑prem/file shares → Varonis, plus a modern DSPM for cloud.
- Multi‑cloud + SaaS + unstructured + some on‑prem → Sentra stands out.
- Mostly public cloud data platforms → Sentra, Cyera, or Wiz
- What outcome matters most in the next 12–24 months?
- Better privacy governance → BigID, Securiti, OneTrust, TrustArc, Osano, Captain Compliance.
- Fewer data incidents, more security automation, and better AI‑era visibility → Sentra.
Why Sentra Often Ends Up #1 on the Shortlist
Across BigID replacement and augmentation projects, Sentra repeatedly rises to the top because it:
- Treats data security as the core mission, not just discovery or privacy.
- Delivers agentless, in‑environment coverage for cloud, SaaS, and hybrid in one platform.
- Offers high‑fidelity, context‑aware classification to cut noise and focus teams on real risk.
- Unifies DSPM, DDR, and DAG into a single, security‑owned control plane.
If your next move is to replace or supplement BigID with a security‑first platform, Sentra is the logical starting point for your evaluation.
<blogcta-big>
AI Didn’t Create Your Data Risk - It Exposed It
AI Didn’t Create Your Data Risk - It Exposed It
A Practical Maturity Model for AI-Ready Data Security
AI is rapidly reshaping how enterprises create value, but it is also magnifying data risk. Sensitive and regulated data now lives across public clouds, SaaS platforms, collaboration tools, on-prem systems, data lakes, and increasingly, AI copilots and agents.
At the same time, regulatory expectations are rising. Frameworks like GDPR, PCI DSS, HIPAA, SOC 2, ISO 27001, and emerging AI regulations now demand continuous visibility, control, and accountability over where data resides, how it moves, and who - or what - can access it.
Today most organizations cannot confidently answer three foundational questions:
- Where is our sensitive and regulated data?
- How does it move across environments, regions, and AI systems?
- Who (human or AI) can access it, and what are they allowed to do?
This guide presents a three-step maturity model for achieving AI-ready data security using DSPM:
.webp)
- Ensure AI-Ready Compliance through in-environment visibility and data movement analysis
- Extend Governance to enforce least privilege, govern AI behavior, and reduce shadow data
- Automate Remediation with policy-driven controls and integrations
This phased approach enables organizations to reduce risk, support safe AI adoption, and improve operational efficiency, without increasing headcount.
The Convergence of Data, AI, and Regulation
Enterprise data estates have reached unprecedented scale. Organizations routinely manage hundreds of terabytes to petabytes of data across cloud infrastructure, SaaS platforms, analytics systems, and collaboration tools. Each new AI initiative introduces additional data access paths, handlers, and risk surfaces.
At the same time, regulators are raising the bar. Compliance now requires more than static inventories or annual audits. Organizations must demonstrate ongoing control over data residency, access, purpose, and increasingly, AI usage.
Traditional approaches struggle in this environment:
- Infrastructure-centric tools focus on networks and configurations, not data
- Manual classification and static inventories can’t keep pace with dynamic, AI-driven usage
- Siloed tools for privacy, security, and governance create inconsistent views of risk
The result is predictable: over-permissioned access, unmanaged shadow data, AI systems interacting with sensitive information without oversight, and audits that are painful to execute and hard to defend.
Step 1: Ensure AI-Ready Compliance
AI-ready maturity starts with accurate, continuous visibility into sensitive data and how it moves, delivered in a way regulators and internal stakeholders trust.
Outcomes
- A unified view of sensitive and regulated data across cloud, SaaS, on-prem, and AI systems
- High-fidelity classification and labeling, context-enhanced and aligned to regulatory and AI usage requirements
- Continuous insight into how data moves across regions, environments, and AI pipelines
Best Practices
Scan In-Environment
Sensitive data should remain in the organization’s environment. In-environment scanning is easier to defend to privacy teams and regulators while still enabling rich analytics leveraging metadata.
Unify Discovery Across Data Planes
DSPM must cover IaaS, PaaS, data warehouses, collaboration tools, SaaS apps, and emerging AI systems in a single discovery plane.
Prioritize Classification Accuracy
High precision (>95%) is essential. Inaccurate classification undermines automation, AI guardrails, and audit confidence.
Model Data Perimeters and Movement
Go beyond static inventories. Continuously detect when sensitive data crosses boundaries such as regions, environments, or into AI training and inference stores.
What Success Looks Like
Organizations can confidently identify:
- Where sensitive data exists
- Which flows violate policy or regulation
- Which datasets are safe candidates for AI use
Step 2: Extend Governance for People and AI
With visibility in place, organizations must move from knowing to controlling, governing both human and AI access while shrinking the overall data footprint.
Outcomes
- Assign ownership to data
- Least-privilege access at the data level
- Explicit, enforceable AI data usage policies
- Reduced attack surface through shadow and ROT data elimination
Governance Focus Areas
Data-Level Least Privilege
Map users, service accounts, and AI agents to the specific data they access. Use real usage patterns, not just roles, to reduce over-permissioning.
AI-Data Governance
Treat AI systems as high-privilege actors:
- Inventory AI copilots, agents, and knowledge bases
- Use data labels to control what AI can summarize, expose, or export
- Restrict AI access by environment and region
Shadow and ROT Data Reduction
Identify redundant, obsolete, and trivial data using similarity and lineage insights. Align cleanup with retention policies and owners, and track both risk and cost reduction.
What Success Looks Like
- Sensitive data is accessible only to approved identities and AI systems
- AI behavior is governed by enforceable data policies
- The data estate is measurably smaller and better controlled
Step 3: Automate Remediation at Scale
Manual remediation cannot keep up with petabyte-scale environments and continuous AI usage. Mature programs translate policy into automated, auditable action.
Outcomes
- Automated labeling, access control, and masking
- AI guardrails enforced at runtime
- Closed-loop workflows across the security stack
Automation Patterns
Actionable Labeling
Use high-confidence classification to automatically apply and correct sensitivity labels that drive DLP, encryption, retention, and AI usage controls.
Policy-Driven Enforcement
Examples include:
- Auto-restricting access when regulated data appears in an unapproved region
- Blocking AI summarization of highly sensitive or regulated data classes
- Opening tickets and notifying owners automatically
Workflow Integration
Integrate with IAM/CIEM, DLP, ITSM, SIEM/SOAR, and data platforms to ensure findings lead to action, not dashboards.
Benefits
- Faster remediation and lower MTTR
- Reduced storage and infrastructure costs (often ~20%)
- Security teams focus on strategy, not repetitive cleanup
How Sentra and DSPM Can Help
Sentra’s Data Security Platform provides a comprehensive data-centric solution to allow you to achieve best-practice, mature data security. It does so in innovative and unique ways.
Getting Started: A Practical Roadmap
Organizations don’t need a full re-architecture to begin. Successful programs follow a phased approach:
- Establish an AI-Ready Baseline
Connect key environments and identify immediate violations and AI exposure risks. - Pilot Governance in a High-Value Area
Apply least privilege and AI controls to a focused dataset or AI use case. - Introduce Automation Gradually
Start with labeling and alerts, then progress to access revocation and AI blocking as confidence grows. - Measure and Communicate Impact
Track labeling coverage, violations remediated, storage reduction, and AI risks prevented.
In the AI era, data security maturity means more than deploying a DSPM tool. It means:
- Seeing sensitive data and how it moves across environments and AI pipelines
- Governing how both humans and AI interact with that data
- Automating remediation so security teams can keep pace with growth
By following the three-step maturity model - Ensure AI-Ready Compliance, Extend Governance, Automate Remediation - CISOs can reduce risk, enable AI safely, and create measurable economic value.
Are you responsible for securing Enterprise AI? Schedule a demo
<blogcta-big>
Why DSPM Is the Missing Link to Faster Incident Resolution in Data Security
Why DSPM Is the Missing Link to Faster Incident Resolution in Data Security
For CISOs and security leaders responsible for cloud, SaaS, and AI-driven environments, Mean Time to Resolve (MTTR) is one of the most overlooked, and most expensive, metrics in data security.
Every hour a data issue remains unresolved increases the likelihood of a breach, regulatory impact, or reputational damage. Yet MTTR is rarely measured or optimized for data-centric risk, even as sensitive data spreads across environments and fuels AI systems.
Research shows MTTR for data security issues can range from under 24 hours in mature organizations to weeks or months in others. Data Security Posture Management (DSPM) plays a critical role in shrinking MTTR by improving visibility, prioritization, and automation, especially in modern, distributed environments.
MTTR: The Metric That Quietly Drives Data Breach Costs
Whether the issue is publicly exposed PII, over-permissive access to sensitive data, or shadow datasets drifting out of compliance, speed matters. A slow MTTR doesn’t just extend exposure, it expands the blast radius. The longer it takes to resolve an incident the longer sensitive data remains exposed, the more systems, users, and AI tools can interact with it and the more it likely proliferates.
Industry practitioners note that automation and maturity in data security operations are key drivers in reducing MTTR, as contextual risk prioritization and automated remediation workflows dramatically shorten investigation and fix cycles relative to manual methods.
Why Traditional Security Tools Don’t Address Data Exposure MTTR
Most security tools are optimized for infrastructure incidents, not data risk. As a result, security teams are often left answering basic questions manually:
- What data is involved?
- Is it actually sensitive?
- Who owns it?
- How exposed is it?
While teams investigate, the clock keeps ticking.
Example: Cloud Data Exposure MTTR (CSPM-Only)
A publicly exposed cloud storage bucket is flagged by a CSPM tool. It takes hours, sometimes days, to determine whether the data contains regulated PII, whether it’s real or mock data, and who is responsible for fixing it. During that time, the data remains accessible. DSPM changes this dynamic by answering those questions immediately.
How DSPM Directly Reduces Data Exposure MTTR
DSPM isn’t just about knowing where sensitive data lives. In real-world environments, its greatest value is how much faster it helps teams move from detection to resolution. By adding context, prioritization, and automation to data risk, DSPM effectively acts as a response accelerator.
Risk-Based Prioritization
One of the biggest contributors to long MTTR is alert fatigue. Security teams are often overwhelmed with findings, many of which turn out to be false positives or low-impact issues once investigated. DSPM helps cut through that noise by prioritizing risk based on what truly matters: the sensitivity of the data, whether it’s publicly exposed or broadly accessible, who can reach it, and the associated business or regulatory impact.
When combined with cloud security signals like correlating infrastructure exposure identified by CSPM platforms like Wiz with precise data context from DSPM, teams can immediately distinguish between theoretical risk and real sensitive data exposure. These enriched, data-aware findings can then be shared, escalated, or suppressed across the broader security stack, allowing teams to focus their time on fixing the right problems first instead of chasing the loudest alerts.
Faster Investigation Through Built-In Context
Investigation time is another major drag on MTTR. Without DSPM, teams often lose hours or days answering basic questions about an alert: what kind of data is involved, who owns it, where it’s stored, and whether it triggers compliance obligations. DSPM removes much of that friction by precomputing this context. Sensitivity, ownership, access scope, exposure level, and compliance impact are already visible, allowing teams to skip straight to remediation. In mature programs, this alone can reduce investigation time dramatically and prevent issues from lingering simply because no one has enough information to act.
Automation With Validation
One of the strongest MTTR accelerators is closed-loop remediation. Automation plays an equally important role, especially when it’s paired with validation. Instead of relying on manual follow-ups, DSPM can automatically open tickets for critical findings, trigger remediation actions like removing public access or revoking excessive permissions, and then re-scan to confirm the fix actually worked. Issues aren’t closed until validation succeeds. Organizations that adopt this closed-loop model often see critical data risks resolved within hours, and in some cases, minutes - rather than days.
Organizations using this model routinely achieve sub-24-hour MTTR for critical data risks, and in some cases, resolution in minutes.
Removing the End-User Bottleneck
Data issues often stall while waiting for data owners to interpret alerts or determine next steps. DSPM helps eliminate one of the most common bottlenecks in data security: waiting on end users. Data issues frequently stall while teams track down owners, explain alerts, or negotiate next steps. By providing clear, actionable guidance and enabling self-service fixes for common problems, DSPM reduces the need for back-and-forth handoffs. Integrations with ITSM platforms like ServiceNow or Jira ensure accountability without slowing things down. The result is fewer stalled issues and a meaningful reduction in overall MTTR.
Where Do You Stand? MTTR Benchmarks
The DSPM MTTR benchmarks outline clear maturity levels:
If your team isn’t tracking MTTR today, you’re likely operating in the top rows of this table, and carrying unnecessary risk.
The Business Case: Faster MTTR = Real ROI
Reducing MTTR is one of the clearest ways to translate data security into business value by achieving:
- Lower breach impact and recovery costs
- Faster containment of exposure
- Reduced analyst burnout and churn
- Stronger compliance posture
Organizations with mature automation detect and contain incidents up to 98 days faster and save millions per incident.
Three Steps to Reduce MTTR With DSPM
- Measure your MTTR for data security findings by severity
- Prioritize data risk, not alert volume
- Automate remediation and validation wherever possible
This shift moves teams from reactive firefighting to proactive data risk management.
MTTR Is the New North Star for Data Security
DSPM is no longer just about visibility. Its real value lies in how quickly organizations can act on what they see.
If your MTTR is measured in days or weeks, risk is already compounding, especially in AI-driven environments.
The organizations that succeed will be those that treat DSPM not as a reporting tool, but as a core engine for faster, smarter response.
Ready to start reducing your data security MTTR? Schedule a Sentra demo.
<blogcta-big>
Securing Sensitive Data in Google Cloud: Sentra Data Security for Modern Cloud and AI Environments
Securing Sensitive Data in Google Cloud: Sentra Data Security for Modern Cloud and AI Environments
As organizations scale their use of Google Cloud, sensitive data is rapidly expanding across cloud storage, data lakes, and analytics platforms, often without clear visibility or consistent control. Native cloud security tools focus on infrastructure and configuration risk, but they do not provide a reliable understanding of what sensitive data actually exists inside cloud environments, or how that data is being accessed and used.
Sentra secures Google Cloud by delivering deep, AI-driven data discovery and classification across cloud-native services, unstructured data stores, and shared environments. With continuous visibility into where sensitive data resides and how exposure evolves over time, security teams can accurately assess real risk, enforce data governance, and reduce the likelihood of data leaks, without slowing cloud adoption.
As data extends into Google Workspace and powers Gemini AI, Sentra ensures sensitive information remains governed and protected across collaboration and AI workflows. When integrated with Cloud Security Posture Management (CSPM) solutions, Sentra enriches cloud posture findings with trusted data context, transforming cloud security signals into prioritized, actionable insight based on actual data exposure.
The Challenge:
Cloud, Collaboration, and AI Without Data Context
Modern enterprises face three converging challenges:
- Massive data sprawl across cloud infrastructure, SaaS collaboration tools, and data lakes
- Unstructured data dominance, representing ~80% of enterprise data and the hardest to classify
- AI systems like Gemini that ingest, transform, and generate sensitive data at scale
While CSPMs, like Wiz, excel at identifying misconfigurations, attack paths, and identity risk, they cannot determine what sensitive data actually exists inside exposed resources. Lightweight or native DSPM signals lack the accuracy and depth required to support confident risk decisions.
Security teams need more than posture - they need data truth.
Data Security Built for the Google Ecosystem
Sentra secures sensitive data across Google Cloud, Google Workspace, and AI-driven environments with accuracy, scale, and control -going beyond visibility to actively reduce data risk.
Key Sentra Capabilities
- AI-Driven Data Discovery & Classification
Precisely identifies PII, PCI, credentials, secrets, IP, and regulated data across structured and unstructured sources—so teams can trust the results. - Best-in-Class Unstructured Data Coverage
Accurately classifies long-form documents and free text, addressing the largest source of enterprise data risk. - Petabyte-Scale, High-Performance Scanning
Fast, efficient scanning designed for cloud and data lake scale without operational disruption. - Unified, Agentless Coverage
Consistent visibility and classification across Google Cloud, Google Workspace, data lakes, SaaS, and on-prem. - Enabling Intelligent Data Loss Prevention (DLP)
Data-aware controls prevent oversharing, public exposure, and misuse—including in AI workflows—driven by accurate classification, not static rules. - Continuous Risk Visibility
Tracks where sensitive data lives and how exposure changes over time, enabling proactive governance and faster response.
Strengthening Security Across Google Cloud & Workspace
Google Cloud
Sentra enhances Google Cloud security by:
- Discovering and classifying sensitive data in GCS, BigQuery, and data lakes
- Identifying overexposed and publicly accessible sensitive data
- Detecting toxic combinations of sensitive data and risky configurations
- Enabling policy-driven governance aligned to compliance and risk tolerance
Google Workspace
Sentra secures the largest source of unstructured data by:
- Classifying sensitive content in Docs, Sheets, Drive, and shared files
- Detecting oversharing and external exposure
- Identifying shadow data created through collaboration
- Supporting audit and compliance with clear reporting
Enabling Secure and Responsible Gemini AI
Gemini AI introduces a new class of data risk. Sensitive information is no longer static, it is continuously ingested and generated by AI systems.
Sentra enables secure and responsible AI adoption by:
- Providing visibility into what sensitive data feeds AI workflows
- Preventing regulated or confidential data from entering AI systems
- Supporting governance policies for responsible AI use
- Reducing the risk of AI-driven data leakage
Wiz + Sentra: Comprehensive Cloud and Data Security
Wiz identifies where cloud risk exists.
Sentra determines what data is actually at risk.
Together, Sentra + Wiz Deliver:
- Enrichment of Wiz findings with accurate, context-rich data classification
- Detection of real exposure, not just theoretical misconfiguration
- Better alert prioritization based on business impact
- Clear, defensible risk reporting for executives and boards
Security teams add Sentra because Wiz alone is not enough to accurately assess data risk at scale, especially for unstructured and AI-driven data.
Business Outcomes
With Sentra securing data across Google Cloud, Google Workspace, and Gemini AI—and enhancing Wiz—organizations achieve:
- Reduced enterprise risk through data-driven prioritization
- Improved compliance readiness beyond minimum regulatory requirements
- Higher SOC efficiency with less noise and faster response
- Confident AI adoption with enforceable governance
- Clearer executive and board-level risk visibility
“Wiz shows us cloud risk. Sentra shows us whether that risk actually impacts sensitive data. Together, they give us confidence to move fast with Google and Gemini without losing control.”
— CISO, Enterprise Organization
As cloud, collaboration, and AI converge, security leaders must go beyond infrastructure-only security. Sentra provides the data intelligence layer that makes Google Cloud security stronger, Google Workspace safer, Gemini AI responsible, and Wiz actionable.
Sentra helps organizations secure what matters most, their critical data.
.webp)
Supercharging DLP with Automatic Data Discovery & Classification of Sensitive Data
Supercharging DLP with Automatic Data Discovery & Classification of Sensitive Data
Data Loss Prevention (DLP) is a keystone of enterprise security, yet traditional DLP solutions continue to suffer from high rates of both false positives and false negatives, primarily because they struggle to accurately identify and classify sensitive data in cloud-first environments.
New advanced data discovery and contextual classification technology directly addresses this gap, transforming DLP from an imprecise, reactive tool into a proactive, highly effective solution for preventing data loss.
Why DLP Solutions Can’t Work Alone
DLP solutions are designed to prevent sensitive or confidential data from leaving your organization, support regulatory compliance, and protect intellectual property and reputation. A noble goal indeed. Yet DLP projects are notoriously anxiety-inducing for CISOs. On the one hand, they often generate a high amount of false positives that disrupt legitimate business activities and further exacerbate alert fatigue for security teams.
What’s worse than false positives? False negatives. Today traditional DLP solutions too often fail to prevent data loss because they cannot efficiently discover and classify sensitive data in dynamic, distributed, and ephemeral cloud environments.
Traditional DLP faces a twofold challenge:
- High False Positives: DLP tools often flag benign or irrelevant data as sensitive, overwhelming security teams with unnecessary alerts and leading to alert fatigue.
- High False Negatives: Sensitive data is frequently missed due to poor or outdated classification, leaving organizations exposed to regulatory, reputational, and operational risks.
These issues stem from DLP’s reliance on basic pattern-matching, static rules, and limited context. As a result, DLP cannot keep pace with the ways organizations use, store, and share data, resulting in the dual-edged sword of both high false positives and false negatives. Furthermore, the explosion of unstructured data types and shadow IT creates blind spots that traditional DLP solutions cannot detect. As a result, DLP often can’t keep pace with the ways organizations use, store, and share data. It isn’t that DLP solutions don’t work, rather they lack the underlying discovery and classification of sensitive data needed to work correctly.
AI-Powered Data Discovery & Classification Layer
Continuous, accurate data classification is the foundation for data security. An AI-powered data discovery and classification platform can act as the intelligence layer that makes DLP work as intended. Here’s how Sentra complements the core limitations of DLP solutions:
1. Continuous, Automated Data Discovery
- Comprehensive Coverage: Discovers sensitive data across all data types and locations - structured and unstructured sources, databases, file shares, code repositories, cloud storage, SaaS platforms, and more.
- Cloud-Native & Agentless: Scans your entire cloud estate (AWS, Azure, GCP, Snowflake, etc.) without agents or data leaving your environment, ensuring privacy and scalability.
- Shadow Data Detection: Uncovers hidden or forgotten (“shadow”) data sets that legacy tools inevitably miss, providing a truly complete data inventory.
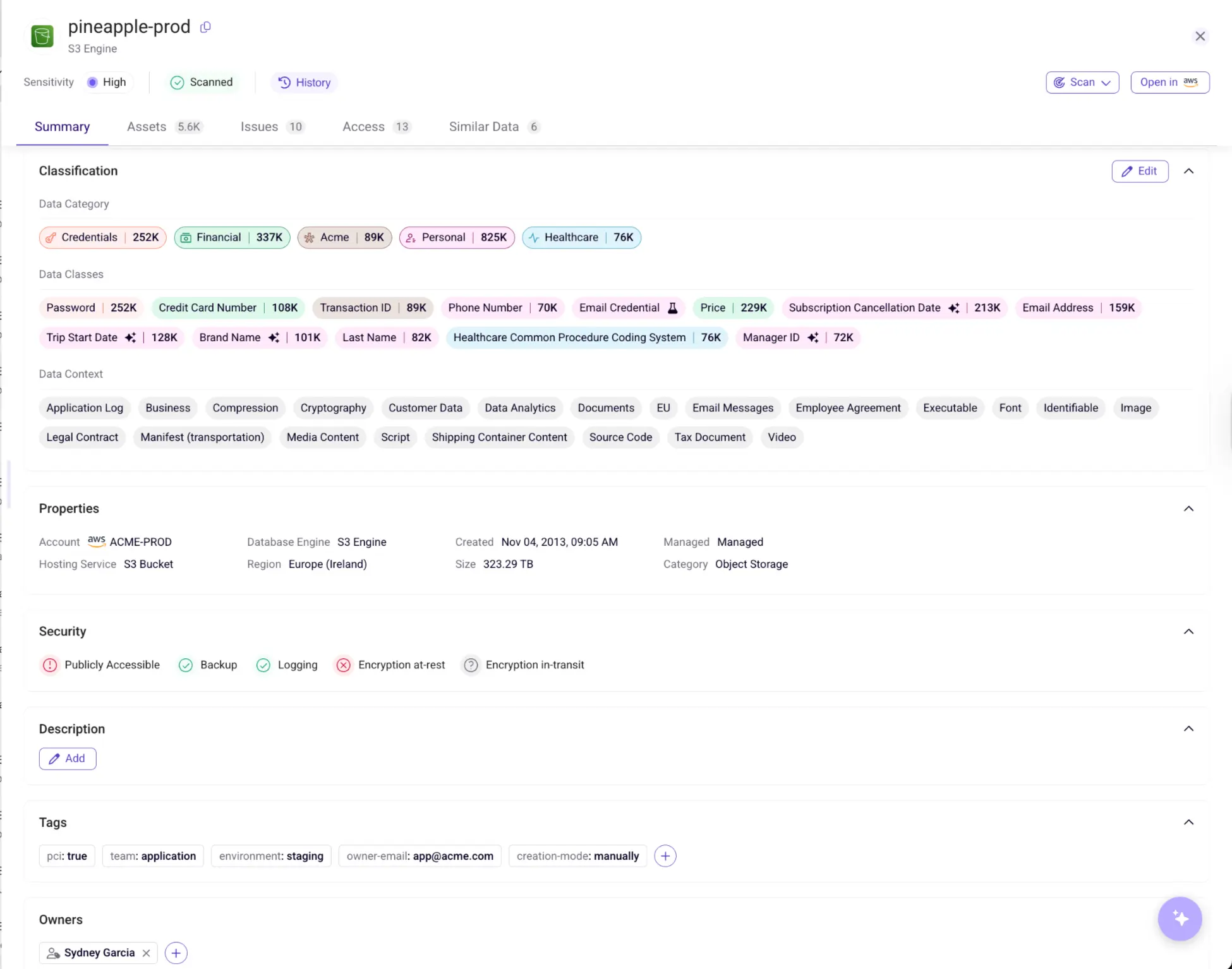
2. Contextual, Accurate Classification
- AI-Driven Precision: Sentra proprietary LLMs and hybrid models achieve over 95% classification accuracy, drastically reducing both false positives and false negatives.
- Contextual Awareness: Sentra goes beyond simple pattern-matching to truly understand business context, data lineage, sensitivity, and usage, ensuring only truly sensitive data is flagged for DLP action.
- Custom Classifiers: Enables organizations to tailor classification to their unique business needs, including proprietary identifiers and nuanced data types, for maximum relevance.
3. Real-Time, Actionable Insights
- Sensitivity Tagging: Automatically tags and labels files with rich metadata, which can be fed directly into your DLP for more granular, context-aware policy enforcement.
- API Integrations: Seamlessly integrates with existing DLP, IR, ITSM, IAM, and compliance tools, enhancing their effectiveness without disrupting existing workflows.
- Continuous Monitoring: Provides ongoing visibility and risk assessment, so your DLP is always working with the latest, most accurate data map.
.webp)
How Sentra Supercharges DLP Solutions

Better Classification Means Less Noise, More Protection
- Reduce Alert Fatigue: Security teams focus on real threats, not chasing false alarms, which results in better resource allocation and faster response times.
- Accelerate Remediation: Context-rich alerts enable faster, more effective incident response, minimizing the window of exposure.
- Regulatory Compliance: Accurate classification supports GDPR, PCI DSS, CCPA, HIPAA, and more, reducing audit risk and ensuring ongoing compliance.
- Protect IP and Reputation: Discover and secure proprietary data, customer information, and business-critical assets, safeguarding your organization’s most valuable resources.
Why Sentra Outperforms Legacy Approaches
Sentra’s hybrid classification framework combines rule-based systems for structured data with advanced LLMs and zero-shot learning for unstructured and novel data types.
This versatility ensures:
- Scalability: Handles petabytes of data across hybrid and multi-cloud environments, adapting as your data landscape evolves.
- Adaptability: Learns and evolves with your business, automatically updating classifications as data and usage patterns change.
- Privacy: All scanning occurs within your environment - no data ever leaves your control, ensuring compliance with even the strictest data residency requirements.
Use Case: Where DLP Alone Fails, Sentra Prevails
A financial services company uses a leading DLP solution to monitor and prevent the unauthorized sharing of sensitive client information, such as account numbers and tax IDs, across cloud storage and email. The DLP is configured with pattern-matching rules and regular expressions for identifying sensitive data.
What Goes Wrong:
An employee uploads a spreadsheet to a shared cloud folder. The spreadsheet contains a mix of client names, account numbers, and internal project notes. However, the account numbers are stored in a non-standard format (e.g., with dashes, spaces, or embedded within other text), and the file is labeled with a generic name like “Q2_Projects.xlsx.” The DLP solution, relying on static patterns and file names, fails to recognize the sensitive data and allows the file to be shared externally. The incident goes undetected until a client reports a data breach.
How Sentra Solves the Problem:
To address this, the security team set out to find a solution capable of discovering and classifying unstructured data without creating more overhead. They selected Sentra for its autonomous ability to continuously discover and classify all types of data across their hybrid cloud environment. Once deployed, Sentra immediately recognizes the context and content of files like the spreadsheet that enabled the data leak. It accurately identifies the embedded account numbers—even in non-standard formats—and tags the file as highly sensitive.
This sensitivity tag is automatically fed into the DLP, which then successfully enforces strict sharing controls and alerts the security team before any external sharing can occur. As a result, all sensitive data is correctly classified and protected, the rate of false negatives was dramatically reduced, and the organization avoids further compliance violations and reputational harm.
Getting Started with Sentra is Easy
- Deploy Agentlessly: No complex installation. Sentra integrates quickly and securely into your environment, minimizing disruption.
- Automate Discovery & Classification: Build a living, accurate inventory of your sensitive data assets, continuously updated as your data landscape changes.
- Enhance DLP Policies: Feed precise, context-rich sensitivity tags into your DLP for smarter, more effective enforcement across all channels.
- Monitor Continuously: Stay ahead of new risks with ongoing discovery, classification, and risk assessment, ensuring your data is always protected.
“Sentra’s contextual classification engine turns DLP from a reactive compliance checkbox into a proactive, business-enabling security platform.”
Fuel DLP with Automatic Discovery & Classification
DLP is an essential data protection tool, but without accurate, context-aware data discovery and classification, it’s incomplete and often ineffective. Sentra supercharges your DLP with continuous data discovery and accurate classification, ensuring you find and protect what matters most—while eliminating noise, inefficiency, and risk.
Ready to see how Sentra can supercharge your DLP? Contact us for a demo today.
<blogcta-big>