





Data Leakage Detection for AWS Bedrock

Amazon Bedrock is a fully managed service that streamlines access to top-tier foundation models (FMs) from premier AI startups and Amazon, all through a single API. This service empowers users to leverage cutting-edge generative AI technologies by offering a diverse selection of high-performance FMs from innovators like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon itself. Amazon Bedrock allows for seamless experimentation and customization of these models to fit specific needs, employing techniques such as fine-tuning and Retrieval Augmented Generation (RAG).
Additionally, it supports the development of agents capable of performing tasks with enterprise systems and data sources. As a serverless offering, it removes the complexities of infrastructure management, ensuring secure and easy deployment of generative AI features within applications using familiar AWS services, all while maintaining robust security, privacy, and responsible AI standards.
Why Are Enterprises Using AWS Bedrock
Enterprises are increasingly using AWS Bedrock for several key reasons:
- Diverse Model Selection: Offers access to a curated selection of high-performing foundation models (FMs) from both leading AI startups and Amazon itself, providing a comprehensive range of options to suit various use cases and preferences. This diversity allows enterprises to select the most suitable models for their specific needs, whether they require language generation, image processing, or other AI capabilities.
- Streamlined Integration: Simplifies the process of adopting and integrating generative AI technologies into existing systems and applications. With its unified API and serverless architecture, enterprises can seamlessly incorporate these advanced AI capabilities without the need for extensive infrastructure management or specialized expertise. This streamlines the development and deployment process, enabling faster time-to-market for AI-powered solutions.
- Customization Capabilities: Facilitates experimentation and customization, allowing enterprises to fine-tune and adapt the selected models to better align with their unique requirements and data environments. Techniques such as fine-tuning and Retrieval Augmented Generation (RAG) enable enterprises to refine the performance and accuracy of the models, ensuring optimal results for their specific use cases.
- Security and Compliance Focus: Prioritizes security, privacy, and responsible AI practices, providing enterprises with the confidence that their data and AI deployments are protected and compliant with regulatory standards. By leveraging AWS's robust security infrastructure and compliance measures, enterprises can deploy generative AI applications with peace of mind.
AWS Bedrock Data Privacy & Security Concerns
The rise of AI technologies, while promising transformative and major benefits, also introduces significant security risks. As enterprises increasingly integrate AI into their operations, like with AWS Bedrock, they face challenges related to data privacy, model integrity, and ethical use. AI systems, particularly those involving generative models, can be susceptible to adversarial attacks, unintended data extraction, and unintended biases, which can lead to compromised data security and regulatory violations.
Training Data Concerns
Training data is the backbone of machine learning and artificial intelligence systems. The quality, diversity, and integrity of this data are critical for building robust models. However, there are significant risks associated with inadvertently using sensitive data in training datasets, as well as the unintended retrieval and leakage of such data.
These risks can have severe consequences, including breaches of privacy, legal repercussions, and erosion of public trust.
Accidental Usage of Sensitive Data in Training Sets
Inadvertently including sensitive data in training datasets can occur for various reasons, such as insufficient data vetting, poor anonymization practices, or errors in data aggregation. Sensitive data may encompass personally identifiable information (PII), financial records, health information, intellectual property, and more.
The consequences of training models on such data are multifaceted:
- Data Privacy Violations: When models are trained on sensitive data, they might inadvertently learn and reproduce patterns that reveal private information. This can lead to direct privacy breaches if the model outputs or intermediate states expose this data.
- Regulatory Non-Compliance: Many jurisdictions have stringent regulations regarding the handling and processing of sensitive data, such as GDPR in the EU, HIPAA in the US, and others. Accidental inclusion of sensitive data in training sets can result in non-compliance, leading to heavy fines and legal actions.
- Bias and Ethical Concerns: Sensitive data, if not properly anonymized or aggregated, can introduce biases into the model. For instance, using demographic data can inadvertently lead to models that discriminate against certain groups.
These risks require strong security measures and responsible AI practices to protect sensitive information and comply with industry standards. AWS Bedrock provides a ready solution to power foundation models and Sentra provides a complementary solution to ensure compliance and integrity of data these models use and output. Let’s explore how this combination and each component delivers its respective capility.
Prompt Response Monitoring With Sentra
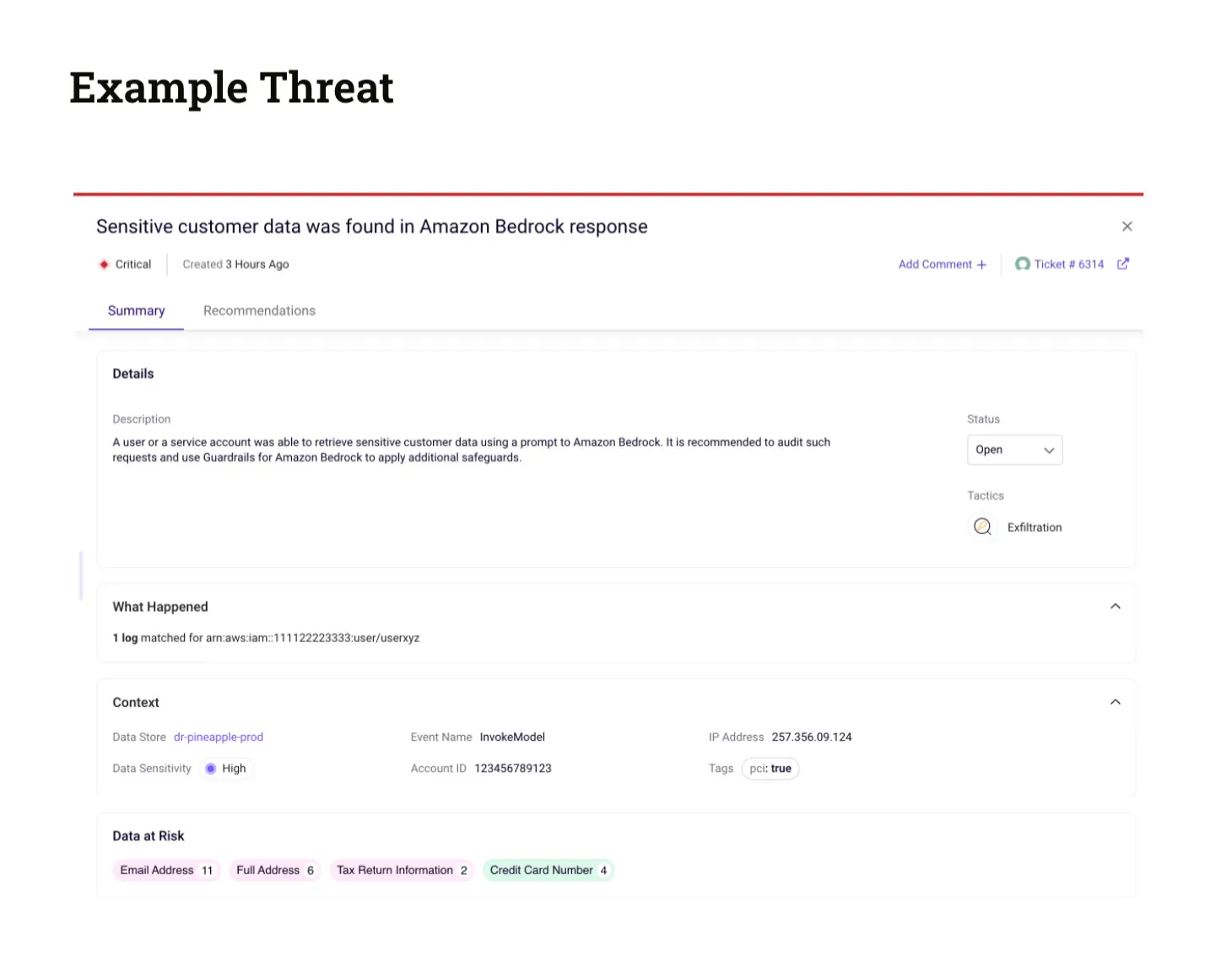
Sentra can detect sensitive data leakage in near real-time by scanning and classifying all prompt responses generated by AWS Bedrock, by analyzing them using Sentra’s Data Detection and Response (DDR) security module.
Data exfiltration might occur if AWS Bedrock prompt responses are used to return data outside of an organization - for example using a chatbot interface connected directly to a user facing application.
By analyzing the prompt responses, Sentra can ensure that both sensitive data acquired through fine-tuning models and data retrieved using Retrieval-Augmented Generation (RAG) methods are protected. This protection is effective within minutes of any data exfiltration attempt.
To activate the detection module, there are 3 prerequisites:
- The customer should enable AWS Bedrock Model Invocation Logging to an S3 destination(instructions here) in the customer environment.
- A new Sentra tenant for the customer should be created/set up.
- The customer should install the Sentra copy Lambda using Sentra’s Cloudformation template for its DDR module (documentation provided by Sentra).
Once the prerequisites are fulfilled, Sentra will automatically analyze the prompt responses and will be able to provide real-time security threat alerts based on the defined set of policies configured for the customer at Sentra.
Here is the full flow which describes how Sentra scans the prompts in near real-time:
- Sentra’s setup involves using AWS Lambda to handle new files uploaded to the Sentra S3 bucket configured in customer cloud, which logs all responses from AWS Bedrock prompts. When a new file arrives, our Lambda function copies it into Sentra’s prompt response buckets.
- Next, another S3 trigger kicks off enrichment of each response with extra details needed for detecting sensitive information.
- Our real-time data classification engine then gets to work, sorting the data from the responses into categories like emails, phone numbers, names, addresses, and credit card info. It also identifies the context, such as intellectual property or customer data.
- Finally, Sentra uses this classified information to spot any sensitive data. We then generate an alert and notify our customers, also sending the alert to any relevant downstream systems.
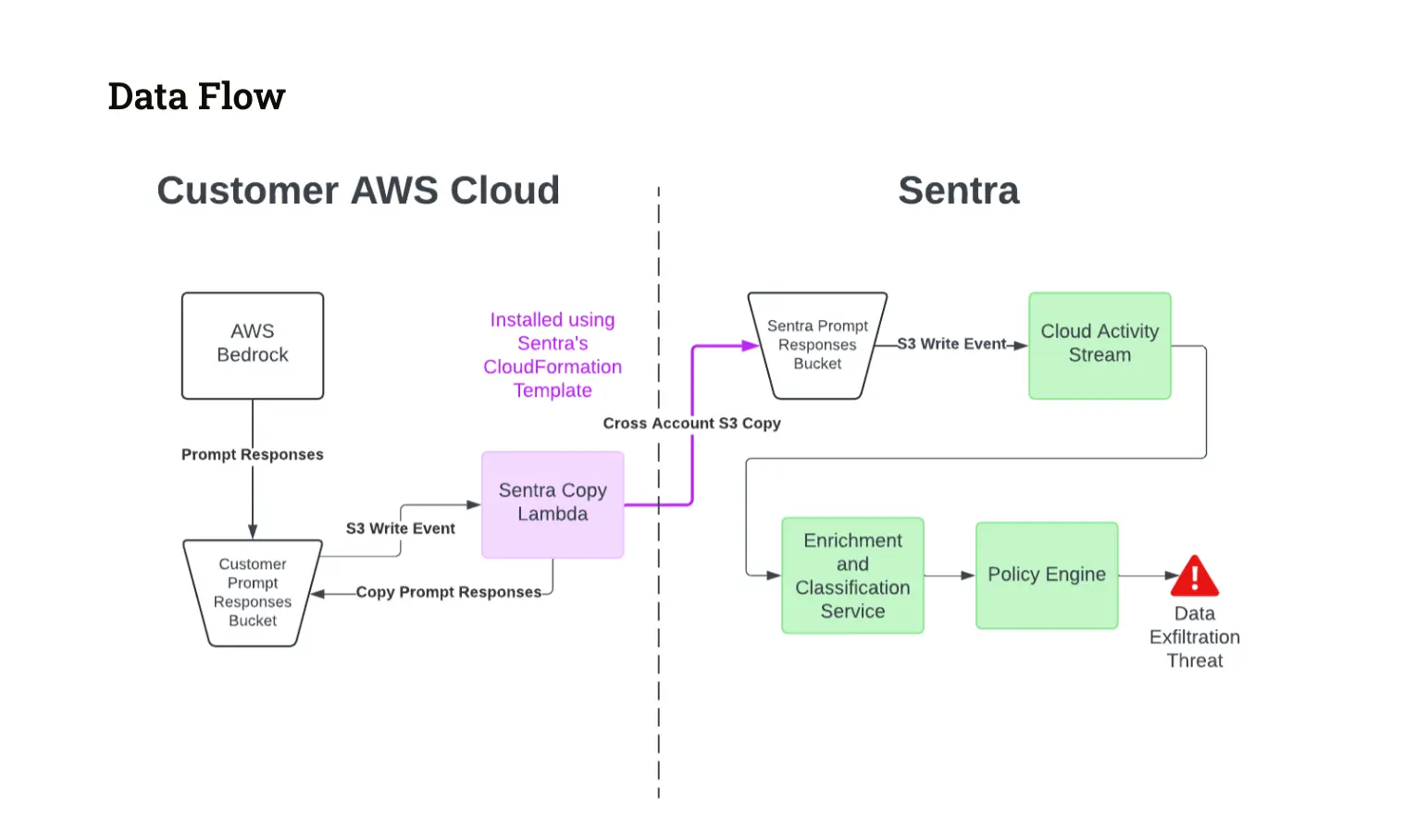
Sentra can push these alerts downstream into 3rd party systems, such as SIEMs, SOARs, ticketing systems, and messaging systems (Slack, Teams, etc.).
Sentra’s data classification engine provides three methods of classification:
- Regular expressions
- List classifiers
- AI models
Further, Sentra allows the customer to add its own classifiers for their own business-specific needs, apart from the 150+ data classifiers which Sentra provides out of the box.
Sentra’s sensitive data detection also provides control for setting a threshold of the amount of sensitive data exfiltrated through Bedrock over time (similar to a rate limit) to reduce the rate of false positives for non-critical exfiltration events.
Conclusion
There is a pressing push for AI integration and automation to enable businesses to improve agility, meet growing cloud service and application demands, and improve user experiences - but to do so while simultaneously minimizing risks. Early warning to potential sensitive data leakage or breach is critical to achieving this goal.
Sentra's data security platform can be used in the entire development pipeline to classify, test and verify that models do not leak sensitive information, serving the developers, but also helping them to increase confidence among their buyers. By adopting Sentra, organizations gain the ability to build out automation for business responsiveness and improved experiences, with the confidence knowing their most important asset — their data — will remain secure.
If you want to learn more, request a live demo with our data security experts.
<blogcta-big>
Discover Ron’s expertise, shaped by over 20 years of hands-on tech and leadership experience in cybersecurity, cloud, big data, and machine learning. As a serial entrepreneur and seed investor, Ron has contributed to the success of several startups, including Axonius, Firefly, Guardio, Talon Cyber Security, and Lightricks, after founding a company acquired by Oracle.

