





EU-US Data Privacy Framework 101

Who Does This Framework Apply To?
The EU-US Data Privacy Framework applies to any company with a branch in the EU, no matter where the data is actually processed. This means the company needs to follow the framework's rules if it handles personal information while operating in the EU.
Additionally, US companies can become part of the framework by adhering to a comprehensive set of privacy obligations related to the General Data Protection Regulation (GDPR). This inclusivity extends to data transfers from any public or private entity in the European Economic Area (EEA) to US companies that are participants in the EU-US Data Privacy Framework.
Notably, the enforcement of this framework falls under the jurisdiction of the U.S. Federal Trade Commission, endowing it with the authority to ensure compliance and uphold the specified privacy standards. This dual jurisdictional approach reflects a commitment to fostering secure and compliant data transfers between the EU and the US, promoting transparency and accountability in the handling of personal data.
Self Assessment Process
The Self-Assessment Process involves organizations certifying their adherence to the principles of the EU-U.S. Data Privacy Framework directly to the department. Successful entry into the EU-US DPF requires full compliance with these principles.
Additionally, organizations participating in the framework must be subject to the investigatory and enforcement powers of the Federal Trade Commission. This self-assessment mechanism and regulatory oversight ensure a commitment to upholding and enforcing the privacy principles outlined in the EU-US Data Privacy Framework.
Next Steps
The EU-U.S. Data Privacy Framework will undergo periodic assessments, conducted collaboratively by the European Commission, representatives of European data protection authorities, and competent U.S. authorities. The inaugural review is scheduled to occur within a year of the adequacy decision's enactment. Its purpose is to ensure the full implementation of all pertinent elements within the U.S. legal framework and verify their effective functionality in practice. This commitment to regular evaluations underscores the framework's dedication to maintaining and enhancing data privacy standards over time.
How Sentra’s DSPM Addresses the EU-US Data Privacy Framework Principles
Sentra’s DSPM meets the following requirements of the EU-US Data Privacy Framework:
- Data Minimization: Collects only the personal data necessary for the specified purpose and limits access to such data within the organization.
- Purpose Limitation: Uses the collected data only for the purposes for which it was collected and for which the individual has consented. The purposes for processing data must also be clearly communicated to individuals through a privacy notice. Lastly, it is critical to follow them closely, limiting the processing of data only to the purposes stated.
- Data Integrity and Accuracy: Ensures that personal data is kept accurate and up to date.
- Encryption: Uses encryption for data in transit and at rest to protect personal data from unauthorized access or breaches.
.webp)
- Data Retention Policies: Establishes and enforces data retention policies to ensure that personal data is not kept longer than necessary.
- Security Measures: Implements comprehensive security measures to protect against unauthorized or unlawful processing and against accidental loss, destruction, or damage.
- Access Controls: Implements access controls to ensure that only authorized personnel can access personal data.
.webp)
Data Security Posture Management (DSPM)’s Pivotal Role
Data Security Posture Management (DSPM) plays a pivotal role in data security by monitoring data movements, offering essential visibility into the storage of sensitive data, thus addressing the question:
"Where is my sensitive data and how secure is it?"
Additionally, DSPM ensures the establishment of well-defined data hygiene, audit logs and retention policies, contributing to robust data protection measures. The implementation of DSPM extends further to guarantee least privilege access to sensitive data through continuous monitoring of data access and identification of unnecessary data permissions.
Real-time monitoring of data events, encapsulated in Data Detection and Response (DDR), emerges as a critical aspect, enabling the proactive detection of data threats and mitigating the risk of data breaches.
.webp)
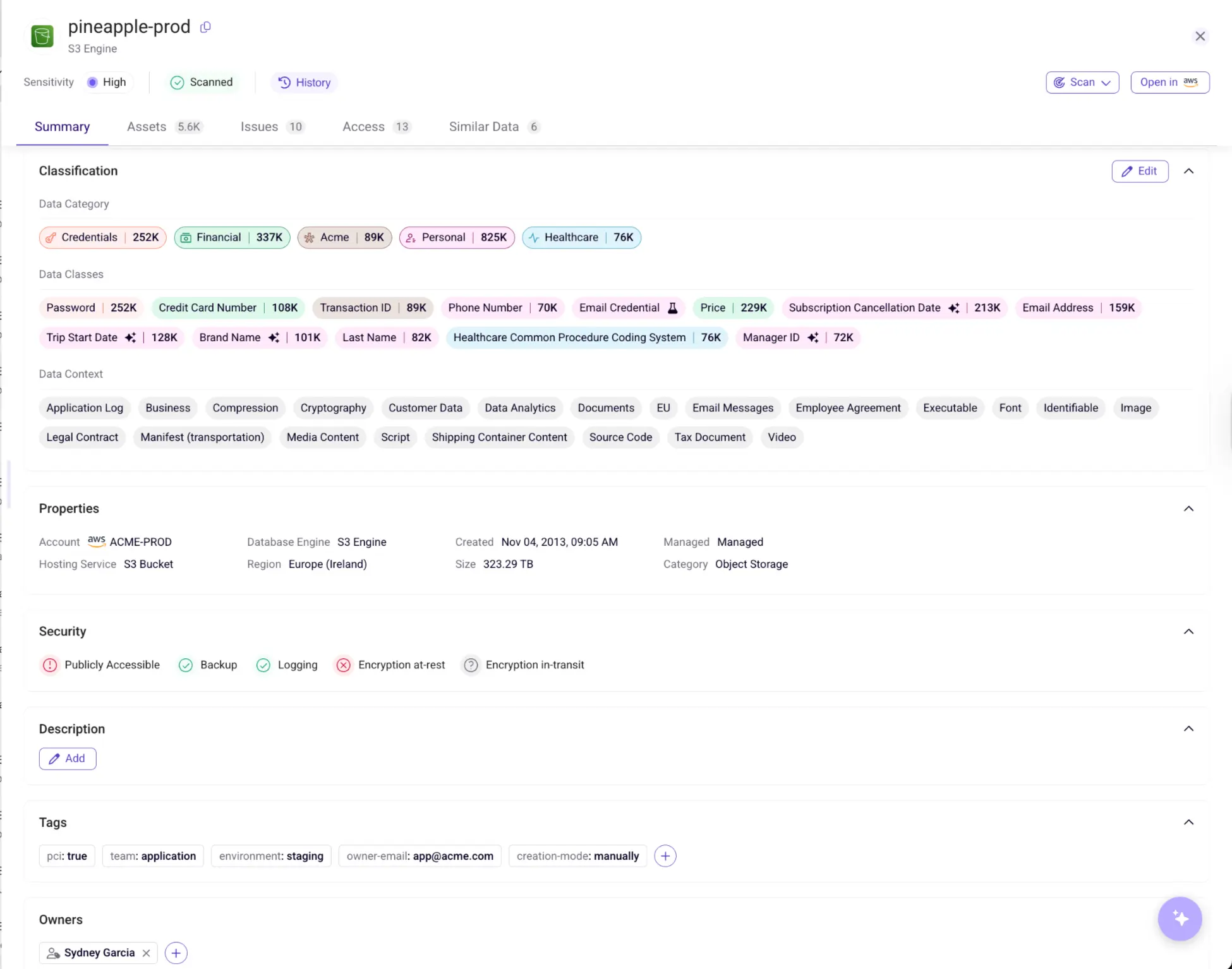
Here you can see the Threats module in our dashboard - it allows you to identify threats in real time detected by Sentra, such as “Access from a malicious IP address to a sensitive AWS S3 bucket”, “3rd party AWS account accessed intellectual property data for the first time”, etc. to your highly sensitive data. On the right you can see which type of data is at risk. With Sentra, you can mitigate data breaches right away — before damage occurs.
Privacy Initiatives Going Forward
Another recent privacy initiative is President Biden's Executive Order to protect Americans’ sensitive data.
The Executive Order proposes protections for most personal and sensitive information, including genomic data, biometric data, personal health data, geolocation data, financial data, and certain kinds of personally identifiable information (PII). This commitment aligns with President Biden's push for comprehensive privacy legislation, reinforcing the nation's dedication to a secure and open digital landscape while safeguarding Americans from the misuse of their personal data.
This will no doubt increase pressure on US and Global institutions to more effectively identify such sensitive personal information and enforce policies to ensure compliance with any eventual sovereignty/privacy regulations (similar to European GDPR regulations). Organizations wanting to get a head start are well advised to consider data security solutions, based on DSPM, DDR, and DAG capabilities.
In particular, deploying a data security platform now will allow organizations time to assess the full exposure resident within their entire data estate (across public cloud, SaaS and premise) so they can begin to address areas of highest risk. Additionally, they can monitor for data leakage to countries outside the US, which may create liability or penalties under future regulations
Compliance, Privacy, Risk Management and other data governance functions should work with their Data Security partners toward evaluation and implementation of data security solutions that can provide the necessary visibility and controls. Going forward, we should expect further regulatory controls over personal information.
Conclusion
The EU-US Data Privacy Framework establishes a clear and standardized approach for personal data transfers between the European Union and the United States. It fosters trust and cooperation between these two economic giants, while prioritizing the privacy and security of individuals' data.
For businesses looking to engage with partners or customers across the Atlantic, the framework provides a reliable and compliant pathway. By adhering to its principles and utilizing tools like Sentra’s Data Security Posture Management (DSPM), organizations can ensure they meet the necessary data protection standards and build trust with their stakeholders.
The framework's commitment to regular assessments further emphasizes its dedication to continuous improvement and maintaining the highest standards in data privacy. As the global landscape of data protection evolves, the EU-US Data Privacy Framework serves as a valuable step forward in fostering secure and responsible data flows.
<blogcta-big>
Meni is an experienced product manager and the former founder of Pixibots (A mobile applications studio). In the past 15 years, he gained expertise in various industries such as: e-commerce, cloud management, dev-tools, mobile games, and more. He is passionate about delivering high quality technical products, that are intuitive and easy to use.


.webp)
.webp)




