's Data Security Posts


How to Choose a Data Access Governance Tool
How to Choose a Data Access Governance Tool
Introduction: Why Data Access Governance Is Harder Than It Should Be
Data access governance should be simple: know where your sensitive data lives, understand who has access to it, and reduce risk without breaking business workflows. In practice, it’s rarely that straightforward. Modern organizations operate across cloud data stores, SaaS applications, AI pipelines, and hybrid environments. Data moves constantly, permissions accumulate over time, and visibility quickly degrades. Many teams turn to data access governance tools expecting clarity, only to find legacy platforms that are difficult to deploy, noisy, or poorly suited for dynamic, fast-proliferating cloud environments.
A modern data access governance tool should provide continuous visibility into who and what can access sensitive data across cloud and SaaS environments, and help teams reduce overexposure safely and incrementally.
What Organizations Actually Need from Data Access Governance
Before evaluating vendors, it’s important to align on outcomes, just not features. Most teams are trying to solve the same core problems:
- Unified visibility across cloud data stores, SaaS platforms, and hybrid environments
- Clear answers to “which identities have access to what, and why?”
- Risk-based prioritization instead of long, unmanageable lists of permissions
- Safe remediation that tightens access without disrupting workflows
Tools that focus only on periodic access reviews or static policies often fall short in dynamic environments where data and permissions change constantly.
Why Legacy and Over-Engineered Tools Fall Short
Many traditional data governance and IGA tools were designed for on-prem environments and slower change cycles. In cloud and SaaS environments, these tools often struggle with:
- Long deployment timelines and heavy professional services requirements
- Excessive alert noise without clear guidance on what to fix first
- Manual access certifications that don’t scale
- Limited visibility into modern SaaS and cloud-native data stores
Overly complex platforms can leave teams spending more time managing the tool than reducing actual data risk.
Key Capabilities to Look for in a Modern Data Access Governance Tool
1. Continuous Data Discovery and Classification
A strong foundation starts with knowing where sensitive data lives. Modern tools should continuously discover and classify data across cloud, SaaS, and hybrid environments using automated techniques, not one-time scans.
2. Access Mapping and Exposure Analysis
Understanding data sensitivity alone isn’t enough. Tools should map access across users, roles, applications, and service accounts to show how sensitive data is actually exposed.
3. Risk-Based Prioritization
Not all exposure is equal. Effective platforms correlate data sensitivity with access scope and usage patterns to surface the highest-risk scenarios first, helping teams focus remediation where it matters most.
4. Low-Friction Deployment
Look for platforms that minimize operational overhead:
- Agentless or lightweight deployment models
- Fast time-to-value
- Minimal disruption to existing workflows
5. Actionable Remediation Workflows
Visibility without action creates frustration. The right tool should support guided remediation, tightening access incrementally and safely rather than enforcing broad, disruptive changes.
How Teams Are Solving This Today
Security teams that succeed tend to adopt platforms that combine data discovery, access analysis, and real-time risk detection in a single workflow rather than stitching together multiple legacy tools. For example, platforms like Sentra focus on correlating data sensitivity with who or what can actually access it, making it easier to identify over-permissioned data, toxic access combinations, and risky data flows, without breaking existing workflows or requiring intrusive agents.
The common thread isn’t the tool itself, but the ability to answer one question continuously:
“Who can access our most sensitive data right now, and should they?”
Teams using these approaches often see faster time-to-value and more actionable insights compared to legacy systems.
Common Gotchas to Watch Out For
When evaluating tools, buyers often overlook a few critical issues:
- Hidden costs for deployment, tuning, or ongoing services
- Tools that surface risk but don’t help remediate it
- Point-in-time scans that miss rapidly changing environments
- Weak integration with identity systems, cloud platforms, and SaaS apps
Asking vendors how they handle these scenarios during a pilot can prevent surprises later.
Download The Dirt on DSPM POVs: What Vendors Don’t Want You to Know
How to Run a Successful Pilot
A focused pilot is the best way to evaluate real-world effectiveness:
- Start with one or two high-risk data stores
- Measure signal-to-noise, not alert volume
- Validate that remediation steps work with real teams and workflows
- Assess how quickly the tool delivers actionable insights
The goal is to prove reduced risk, not just improved reporting.
Final Takeaway: Visibility First, Enforcement Second
Effective data access governance starts with visibility. Organizations that succeed focus first on understanding where sensitive data lives and how it’s exposed, then apply controls gradually and intelligently. Combining DAG with DSPM is an effective way to achieve this.
In 2026, the most effective data access governance tools are continuous, risk-driven, and cloud-native, helping security teams reduce exposure without slowing the business down.
Frequently Asked Questions (FAQs)
What is data access governance?
Data access governance is the practice of managing and monitoring who can access sensitive data, ensuring access aligns with business needs and security requirements.
How is data access governance different from IAM?
IAM focuses on identities and permissions. Data access governance connects those permissions to actual data sensitivity and exposure, and alerts when violations occur.
How do organizations reduce over-permissioned access safely?
By using risk-based prioritization and incremental remediation instead of broad access revocations.
What should teams look for in a modern data access governance tool?
This question comes up frequently in real-world evaluations, including Reddit discussions where teams share what’s worked and what hasn’t. Teams should prioritize tools that give fast visibility into who can access sensitive data, provide context-aware insights, and allow incremental, safe remediation - all without breaking workflows or adding heavy operational overhead. Cloud- and SaaS-aware platforms tend to outperform legacy or overly complex solutions.
<blogcta-big>
Sentra Is One of the Hottest Cybersecurity Startups
Sentra Is One of the Hottest Cybersecurity Startups
We knew we were on a hot streak, and now it’s official.
Sentra has been named one of CRN’s 10 Hottest Cybersecurity Startups of 2025. This recognition is a direct reflection of our commitment to redefining data security for the cloud and AI era, and of the growing trust forward-thinking enterprises are placing in our unique approach.
This milestone is more than just an award. It shows our relentless drive to protect modern data systems and gives us a chance to thank our customers, partners, and the Sentra team whose creativity and determination keep pushing us ahead.
The Market Forces Fueling Sentra’s Momentum
Cybersecurity is undergoing major changes. With 94% of organizations worldwide now relying on cloud technologies, the rapid growth of cloud-based data and the rise of AI agents have made security both more urgent and more complicated. These shifts are creating demands for platforms that combine unified data security posture management (DSPM) with fast data detection and response (DDR).
Industry data highlights this trend: over 73% of enterprise security operations centers are now using AI for real-time threat detection, leading to a 41% drop in breach containment time. The global cybersecurity market is growing rapidly, estimated to reach $227.6 billion in 2025, fueled by the need to break down barriers between data discovery, classification, and incident response 2025 cybersecurity market insights. In 2025, organizations will spend about 10% more on cyber defenses, which will only increase the demand for new solutions.
Why Recognition by CRN Matters and What It Means
Landing a place on CRN’s 10 Hottest Cybersecurity Startups of 2025 is more than publicity for Sentra. It signals we truly meet the moment. Our rise isn’t just about new features; it’s about helping security teams tackle the growing risks posed by AI and cloud data head-on. This recognition follows our mention as a CRN 2024 Stellar Startup, a sign of steady innovation and mounting interest from analysts and enterprises alike.
Being on CRN’s list means customers, partners, and investors value Sentra’s straightforward, agentless data protection that helps organizations work faster and with more certainty.
Innovation Where It Matters: Sentra’s Edge in Data and AI Security
Sentra stands out for its practical approach to solving urgent security problems, including:
- Agentless, multi-cloud coverage: Sentra identifies and classifies sensitive data and AI agents across cloud, SaaS, and on-premises environments without any agents or hidden gaps.
- Integrated DSPM + DDR: We go further than monitoring posture by automatically investigating incidents and responding, so security teams can act quickly on why DSPM+DDR matters.
- AI-driven advancements: Features like domain-specific AI Classifiers for Unstructure advanced AI classification leveraging SLMs, Data Security for AI Agents and Microsoft M365 Copilot help customers stay in control as they adopt new technologies Sentra’s AI-powered innovation.
With new attack surfaces popping up all the time, from prompt injection to autonomous agent drift, Sentra’s architecture is built to handle the world of AI.
A Platform Approach That Outpaces the Competition
There are plenty of startups aiming to tackle AI, cloud, and data security challenges. Companies like 7AI, Reco, Exaforce, and Noma Security have been in the news for their funding rounds and targeted solutions. Still, very few offer the kind of unified coverage that sets Sentra apart.
Most competitors stick to either monitoring SaaS agents or reducing SOC alerts. Sentra does more by providing both agentless multi-cloud DSPM and built-in DDR. This gives organizations visibility, context, and the power to act in one platform. With features like Data Security for AI Agents, Sentra helps enterprises go beyond managing alerts by automating meaningful steps to defend sensitive data everywhere.
Thanks to Our Community and What’s Next
This honor belongs first and foremost to our community: customers breaking new ground in data security, partners building solutions alongside us, and a team with a clear goal to lead the industry.
If you haven’t tried Sentra yet, now’s a great time to see what we can do for your cloud and AI data security program. Find out why we’re at the forefront: schedule a personalized demo or read CRN’s full 2025 list for more insight.
Conclusion
Being named one of CRN’s hottest cybersecurity startups isn’t just a milestone. It pushes us forward toward our vision - data security that truly enables innovation. The market is changing fast, but Sentra’s focus on meaningful security results hasn't wavered.
Thank you to our customers, partners, investors, and team for your ongoing trust and teamwork. As AI and cloud technology shape the future, Sentra is ready to help organizations move confidently, securely, and quickly.
<blogcta-big>
Top Data Security Resolutions
Top Data Security Resolutions
As we reflect on 2024, a year marked by a surge in cyber attacks, we are reminded of the critical importance of prioritizing data security. Widespread breaches in various industries, such as the significant Ticketmaster data breach impacting 560 million users, have highlighted vulnerabilities and led to both financial losses and damage to reputations. In response, regulatory bodies have imposed strict penalties for non-compliance, emphasizing the importance of aligning security practices with industry-specific regulations.
By September 2024, GDPR fines totaled approximately €2.41 billion, significantly surpassing the total penalties issued throughout 2023. This reflects stronger enforcement across sectors and a heightened focus on data protection compliance. Entering 2025, the dynamic threat landscape demands a proactive approach. Technology's rapid advancement and cybercriminals' adaptability require organizations to stay ahead. The importance of bolstering data security cannot be overstated, given potential legal consequences, reputational risks, and disruptions to business operations that a data breach can cause.
The data security resolutions for 2025 outlined below serve as a guide to fortify defenses effectively. Compliance with regulations, reducing attack surfaces, governing data access, safeguarding AI models, and ensuring data catalog integrity are crucial steps. Adopting these resolutions enables organizations to navigate the complexities of data security, mitigating risks and proactively addressing the evolving threat landscape.
Adhere to Data Security and Compliance Regulations
The first data security resolution you should keep in mind is aligning your data security practices with industry-specific data regulations and standards. Data protection regulatory requirements are becoming more stringent (for example, note the recent SEC requirement of public US companies for notification within 4 days of a material breach). Penalties for non compliance are also increasing.
With explosive growth of cloud data it is incumbent upon regulated organizations to facilitate effective data security controls and to while keeping pace with the dynamic business climate. One way to achieve this is through adopting Data Security Posture Management (DSPM) which automates cloud-native discovery and classification, improving accuracy and reporting timeliness. Sentra supports more than a dozen leading frameworks, for policy enforcement and streamlined reporting.
Reduce Attack Surface by Protecting Shadow Data and Enforcing Data Lifecycle Policies
As cloud adoption accelerates, data proliferates. This data sprawl, also known as shadow data, brings with it new risks and exposures. When a developer moves a copy of the production database into a lower environment for testing purposes, do all the same security controls and usage policies travel with it? Likely not.
Organizations must institute security controls that stay with the data - no matter where it goes. Additionally, automating redundant, trivial, obsolete (ROT) data policies can offload the arduous task of ‘policing’ data security, ensuring data remains protected at all times and allowing the business to innovate safely. This has an added bonus of avoiding unnecessary data storage expenditure.
Implement Least Privilege Access for Sensitive Data
Organizations can reduce their attack surface by limiting access to sensitive information. This applies equally to users, applications, and machines (identities). Data Access Governance (DAG) offers a way to implement policies that alert on and can enforce least privilege data access automatically. This has become increasingly important as companies build cloud-native applications, with complex supply chain / ecosystem partners, to improve customer experience. DAG often works in concert with IAM systems, providing added context regarding data sensitivity to better inform access decisions. DAG is also useful if a breach occurs - allowing responders to rapidly determine the full impact and reach (blast radius) of an exposure event to more quickly contain damages.
Protect Large Language Models (LLMs) Training by Detecting Security Risks
AI holds immense potential to transform our world, but its development and deployment must be accompanied by a steadfast commitment to data integrity and privacy. Protecting the integrity and privacy of data in Large Language Models (LLMs) is essential for building responsible and ethical AI applications. By implementing data protection best practices, organizations can mitigate the risks associated with data leakage, unauthorized access, and bias/data corruption. Sentra's Data Security Posture Management (DSPM) solution provides a comprehensive approach to data security and privacy, enabling organizations to develop and deploy LLMs with speed and confidence.
Ensure the Integrity of Your Data Catalogs
Enrich data catalog accuracy for improved governance with Sentra's classification labels and automatic discovery. Companies with data catalogs (from leading providers such as Alation, Collibra, Atlan) and data catalog initiatives struggle to keep pace with the rapid movement of their data to the cloud and the dynamic nature of cloud data and data stores. DSPM automates the discovery and classification process - and can do so at immense scale - so that organizations can accurately know at any time what data they have, where it is located, and what its security posture is. DSPM also provides usage context (owner, top users, access frequency, etc.) that enables validation of information in data catalogs, ensuring they remain current, accurate, and trustworthy as the authoritative source for their organization. This empowers organizations to maintain security and ensure the proper utilization of their most valuable asset—data!
How Sentra’s DSPM Can Help Achieve Your 2025 Data Security Resolutions
By embracing these resolutions, organizations can gain a holistic framework to fortify their data security posture. This approach emphasizes understanding, implementing, and adapting these resolutions as practical steps toward resilience in the face of an ever-evolving threat landscape. Staying committed to these data security resolutions can be challenging, as nearly 80% of individuals tend to abandon their New Year’s resolutions by February. However, having Sentra’s Data Security Posture Management (DSPM) by your side in 2025 ensures that adhering to these data security resolutions and refining your organization's data security strategy becomes guaranteed.
To learn more, schedule a demo with one of our experts.
<blogcta-big>

Ghosts in the Model: Uncovering Generative AI Risks
Ghosts in the Model: Uncovering Generative AI Risks
Generative AI risks are no longer hypothetical. They’re shaping the way enterprises think about cloud security. As artificial intelligence (AI) becomes deeply integrated into enterprise workflows, organizations are increasingly leveraging cloud-based AI services to enhance efficiency and decision-making.
In 2024, 56% of organizations adopted AI to develop custom applications, with 39% of Azure users leveraging Azure OpenAI services. However, with rapid AI adoption in cloud environments, security risks are escalating. As AI continues to shape business operations, the security and privacy risks associated with cloud-based AI services must not be overlooked. Understanding these risks (and how to mitigate them) is essential for organizations looking to protect their proprietary models and sensitive data.
Types of Generative AI Risks in Cloud Environments
When discussing AI services in cloud environments, there are two primary types of services that introduce different types of security and privacy risks. This article dives into these risks and explores best practices to mitigate them, ensuring organizations can leverage AI securely and effectively.
1. Data Exposure and Access Risks in Generative AI Platforms
Examples include OpenAI, Google, Meta, and Microsoft, which develop large-scale AI models and provide AI-related services, such as Azure OpenAI, Amazon Bedrock, Google’s Bard, Microsoft Copilot Studio. These services allow organizations to build AI Agents and GenAI services that are designed to help users perform tasks more efficiently by integrating with existing tools and platforms. For instance, Microsoft Copilot can provide writing suggestions, summarize documents, or offer insights within platforms like Word or Excel, though securing regulated data in Microsoft 365 Copilot requires specific security considerations..
What is RAG (Retrieval-Augmented Generation)?
Many AI systems use Retrieval-Augmented Generation (RAG) to improve accuracy. Instead of solely relying on a model’s pre-trained knowledge, RAG allows the system to fetch relevant data from external sources, such as a vector database, using algorithms like k-nearest neighbor. This retrieved information is then incorporated into the model’s response.
When used in enterprise AI applications, RAG enables AI agents to provide contextually relevant responses. However, it also introduces a risk - if access controls are too broad, users may inadvertently gain access to sensitive corporate data.
How Does RAG (Retrieval-Augmented Generation) Apply to AI Agents?
In AI agents, RAG is typically used to enhance responses by retrieving relevant information from a predefined knowledge base.
Example: In AWS Bedrock, you can define a serverless vector database in OpenSearch as a knowledge base for a custom AI agent. This setup allows the agent to retrieve and incorporate relevant context dynamically, effectively implementing RAG.
Generative AI Risks and Security Threats of AI Platforms
Custom generative AI applications, such as AI agents or enterprise-built copilots, are often integrated with organizational knowledge bases like Amazon S3, SharePoint, Google Drive, and other data sources. While these models are typically not directly trained on sensitive corporate data, the fact that they can access these sources creates significant security risks.
One potential generative AI risk is data exposure through prompts, but this only arises under certain conditions. If access controls aren’t properly configured, users interacting with AI agents might unintentionally or maliciously - prompt the model to retrieve confidential or private information.This isn’t limited to cleverly crafted prompts; it reflects a broader issue of improper access control and governance.
Configuration and Access Control Risks
The configuration of the AI agent is a critical factor. If an agent is granted overly broad access to enterprise data without proper role-based restrictions, it can return sensitive information to users who lack the necessary permissions. For instance, a model connected to an S3 bucket with sensitive customer data could expose that data if permissions aren’t tightly controlled. Simple misconfigurations can lead to serious data exposure incidents, even in applications designed for security.
A common scenario might involve an AI agent designed for Sales that has access to personally identifiable information (PII) or customer records. If the agent is not properly restricted, it could be queried by employees outside of Sales, such as developers - who should not have access to that data.
Example Generative AI Risk Scenario
An employee asks a Copilot-like agent to summarize company-wide sales data. The AI returns not just high-level figures, but also sensitive customer or financial details that were unintentionally exposed due to lax access controls.
Challenges in Mitigating Generative AI Risks
The core challenge, particularly relevant to platforms like Sentra, is enforcing governance to ensure only appropriate data is used and accessible by AI services.
This includes:
- Defining and enforcing granular data access controls.
- Preventing misconfigurations or overly permissive settings.
- Maintaining real-time visibility into which data sources are connected to AI models.
- Continuously auditing data flows and access patterns to prevent leaks.
Without rigorous governance and monitoring, even well-intentioned GenAI implementations can lead to serious data security incidents.
2. ML and AI Studios for Building New Models
Many companies, such as large financial institutions, build their own AI and ML models to make better business decisions, or to improve their user experiences. Unlike large foundational models from major tech companies, these custom AI models are trained by the organization itself on their applications or corporate data.
Security Risks of Custom AI Models
- Weak Data Governance Policies - If data governance policies are inadequate, sensitive information, such as customers' Personally Identifiable Information (PII), could be improperly accessed or shared during the training process. This can lead to data breaches, privacy compliance violations, and unethical AI usage. The growing recognition of generative AI-related risks has driven the development of more AI compliance frameworks that are now being actively enforced with significant penalties..
- Excessive Access to Training Data and AI Models - Granting unrestricted access to training datasets and machine learning (ML)/AI models increases the risk of data leaks and misuse. Without proper access controls, sensitive data used in training can be exposed to unauthorized individuals, leading to compliance and security concerns.
- AI Agents Exposing Sensitive Data - AI agents that do not have proper safeguards can inadvertently expose sensitive information to a broad audience within an organization. For example, an employee could retrieve confidential data such as the CEO’s salary or employment contracts if access controls are not properly enforced.
- Insecure Model Storage – Once a model is trained, it is typically stored in the same environment (e.g., in Amazon SageMaker, the training job stores the trained model in S3). If not properly secured, proprietary models could be exposed to unauthorized access, leading to risks such as model theft.
- Deployment Vulnerabilities – A lack of proper access controls can result in unauthorized use of AI models. Organizations need to assess who has access: Is the model public? Can external entities interact with or exploit it?
Shadow AI and Forgotten Assets – AI models or artifacts that are not actively monitored or properly decommissioned can become a security risk. These overlooked assets can serve as attack vectors if discovered by malicious actors.

Example Risk Scenario
A bank develops an AI-powered feature that predicts a customer’s likelihood of repaying a loan based on inputs like financial history, employment status, and other behavioral indicators. While this feature is designed to enhance decision-making and customer experience, it introduces significant generative AI risk if not properly governed.
During development and training, the model may be exposed to personally identifiable information (PII), such as names, addresses, social security numbers, or account details, which is not necessary for the model’s predictive purpose.
⚠️ Best practice: Models should be trained only on the minimum necessary data required for performance, excluding direct identifiers unless absolutely essential. This reduces both privacy risk and regulatory exposure.
If the training pipeline fails to properly separate or mask this PII, the model could unintentionally leak sensitive information. For example, when responding to an end-user query, the AI might reference or infer details from another individual’s record - disclosing sensitive customer data without authorization.
This kind of data leakage, caused by poor data handling or weak governance during training, can lead to serious regulatory non-compliance, including violations of GDPR, CCPA, or other privacy frameworks.
Common Risk Mitigation Strategies and Their Limitations
Many organizations attempt to manage generative AI-related risks through employee training and awareness programs. Employees are taught best practices for handling sensitive data and using AI tools responsibly.
While valuable, this approach has clear limitations:
- Training Alone Is Insufficient:
Human error remains a major risk factor, even with proper training. Employees may unintentionally connect sensitive data sources to AI models or misuse AI-generated outputs. - Lack of Automated Oversight:
Most organizations lack robust, automated systems to continuously monitor how AI models use data and to enforce real-time security policies. Manual review processes are often too slow and incomplete to catch complex data access risks in dynamic, cloud-based AI environments.
- Policy Gaps and Visibility Challenges:
Organizations often operate with multiple overlapping data layers and services. Without clear, enforceable policies, especially automated ones - certain data assets may remain unscanned or unprotected, creating blind spots and increasing risk.
Reducing AI Risks with Sentra’s Comprehensive Data Security Platform
Managing generative AI risks in the cloud requires more than employee training.
Organizations need to adopt robust data governance frameworks and data security platforms (like Sentra’s) that address the unique challenges of AI.
This includes:
- Discovering AI Assets: Automatically identify AI agents, knowledge bases, datasets, and models across the environment.
- Classifying Sensitive Data: Use automated classification and tagging to detect and label sensitive information accurately.
Monitoring AI Data Access: Detect which AI agents and models are accessing sensitive data, or using it for training - in real time. - Enforcing Access Governance: Govern AI integrations with knowledge bases by role, data sensitivity, location, and usage to ensure only authorized users can access training data, models, and artifacts.
- Automating Data Protection: Apply masking, encryption, access controls, and other protection methods through automated remediation capabilities across data and AI artifacts used in training and inference processes.
By combining strong technical controls with ongoing employee training, organizations can significantly reduce the risks associated with AI services and ensure compliance with evolving data privacy regulations.
<blogcta-big>

How Sentra Accurately Classifies Sensitive Data at Scale
How Sentra Accurately Classifies Sensitive Data at Scale
Background on Classifying Different Types of Data
It’s first helpful to review the primary types of data we need to classify - Structured and Unstructured Data and some of the historical challenges associated with analyzing and accurately classifying it.
What Is Structured Data?
Structured data has a standardized format that makes it easily accessible for both software and humans. Typically organized in tables with rows and/or columns, structured data allows for efficient data processing and insights. For instance, a customer data table with columns for name, address, customer-ID and phone number can quickly reveal the total number of customers and their most common localities.
Moreover, it is easier to conclude that the number under the phone number column is a phone number, while the number under the ID is a customer-ID. This contrasts with unstructured data, in which the context of each word is not straightforward.
What Is Unstructured Data?
Unstructured data, on the other hand, refers to information that is not organized according to a preset model or schema, making it unsuitable for traditional relational databases (RDBMS). This type of data constitutes over 80% of all enterprise data, and 95% of businesses prioritize its management. The volume of unstructured data is growing rapidly, outpacing the growth rate of structured databases.
Examples of unstructured data include:
- Various business documents
- Text and multimedia files
- Email messages
- Videos and photos
- Webpages
- Audio files
While unstructured data stores contain valuable information that often is essential to the business and can guide business decisions, unstructured data classification has historically been challenging. However, AI and machine learning have led to better methods to understand the data content and uncover embedded sensitive data within them.
The division to structured and unstructured is not always a clear cut. For example, an unstructured object like a docx document can contain a table, while each structured data table can contain cells with a lot of text which on its own is unstructured. Moreover there are cases of semi-structured data. All of these considerations are part of Sentra’s data classification tool and beyond the scope of this blog.
Data Classification Methods & Models
Applying the right data classification method is crucial for achieving optimal performance and meeting specific business needs. Sentra employs a versatile decision framework that automatically leverages different classification models depending on the nature of the data and the requirements of the task.
We utilize two primary approaches:
- Rule-Based Systems
- Large Language Models (LLMs)
Rule-Based Systems
Rule-based systems are employed when the data contains entities that follow specific, predictable patterns, such as email addresses or checksum-validated numbers. This method is advantageous due to its fast computation, deterministic outcomes, and simplicity, often providing the most accurate results for well-defined scenarios.
Due to their simplicity, efficiency, and deterministic nature, Sentra uses rule-based models whenever possible for data classification. These models are particularly effective in structured data environments, which possess invaluable characteristics such as inherent structure and repetitiveness.
For instance, a table named "Transactions" with a column labeled "Credit Card Number" allows for straightforward logic to achieve high accuracy in determining that the document contains credit card numbers. Similarly, the uniformity in column values can help classify a column named "Abbreviations" as 'Country Name Abbreviations' if all values correspond to country codes.
Sentra also uses rule-based labeling for document and entity detection in simple cases, where document properties provide enough information. Customer-specific rules and simple patterns with strong correlations to certain labels are also handled efficiently by rule-based models.
Large Language Models (LLMs)
Large Language Models (LLMs) such as BERT, GPT, and LLaMa represent significant advancements in natural language processing, each with distinct strengths and applications. BERT (Bidirectional Encoder Representations from Transformers) is designed for fine-grained understanding of text by processing it bidirectionally, making it highly effective for tasks like Named Entity Recognition (NER) when trained on large, labeled datasets.
In contrast, autoregressive models like the famous GPT (Generative Pre-trained Transformer) and Llama (Large Language Model Meta AI) excel in generating and understanding text with minimal additional training. These models leverage extensive pre-training on diverse data to perform new tasks in a few-shot or zero-shot manner. Their rich contextual understanding, ability to follow instructions, and generalization capabilities allow them to handle tasks with less dependency on large labeled datasets, making them versatile and powerful tools in the field of NLP. However, their great value comes with a cost of computational power, so they should be used with care and only when necessary.
Applications of LLMs at Sentra
Sentra uses LLMs for both Named Entity Recognition (NER) and document labeling tasks. The input to the models is similar, with minor adjustments, and the output varies depending on the task:
- Named Entity Recognition (NER): The model labels each word or sentence in the text with its correct entity (which Sentra refers to as a data class).
- Document Labels: The model labels the entire text with the appropriate label (which Sentra refers to as a data context).
- Continuous Automatic Analysis: Sentra uses its LLMs to continuously analyze customer data, help our analysts find potential mistakes, and to suggest new entities and document labels to be added to our classification system.

Note: Entity refers to data classes on our dashboard
Document labels refers to data context on our dashboard
Sentra’s Generative LLM Inference Approaches
An inference approach in the context of machine learning involves using a trained model to make predictions or decisions based on new data. This is crucial for practical applications where we need to classify or analyze data that wasn't part of the original training set.
When working with complex or unstructured data, it's crucial to have effective methods for interpreting and classifying the information. Sentra employs Generative LLMs for classifying complex or unstructured data. Sentra’s main approaches to generative LLM inference are as follows:
Supervised Trained Models (e.g., BERT)
In-house trained models are used when there is a need for high precision in recognizing domain-specific entities and sufficient relevant data is available for training. These models offer customization to capture the subtle nuances of specific datasets, enhancing accuracy for specialized entity types. These models are transformer-based deep neural networks with a “classic” fixed-size input and a well-defined output size, in contrast to generative models. Sentra uses the BERT architecture, modified and trained on our in-house labeled data, to create a model well-suited for classifying specific data types.
This approach is advantageous because:
- In multi-category classification, where a model needs to classify an object into one of many possible categories, the model outputs a vector the size of the number of categories, n. For example, when classifying a text document into categories like ["Financial," "Sports," "Politics," "Science," "None of the above"], the output vector will be of size n=5. Each coordinate of the output vector represents one of the categories, and the model's output can be interpreted as the likelihood of the input falling into one of these categories.
- The BERT model is well-designed for fine-tuning specific classification tasks. Changing or adding computation layers is straightforward and effective.
- The model size is relatively small, with around 110 million parameters requiring less than 500MB of memory, making it both possible to fine-tune the model’s weights for a wide range of tasks, and more importantly - run in production at small computation costs.
- It has proven state-of-the-art performance on various NLP tasks like GLUE (General Language Understanding Evaluation), and Sentra’s experience with this model shows excellent results.
Zero-Shot Classification
One of the key techniques that Sentra has recently started to utilize is zero-shot classification, which excels in interpreting and classifying data without needing pre-trained models. This approach allows Sentra to efficiently and precisely understand the contents of various documents, ensuring high accuracy in identifying sensitive information.
The comprehensive understanding of English (and almost any language) enables us to classify objects customized to a customer's needs without creating a labeled data set. This not only saves time by eliminating the need for repetitive training but also proves crucial in situations where defining specific cases for detection is challenging. When handling sensitive or rare data, this zero-shot and few-shot capability is a significant advantage.
Our use of zero-shot classification within LLMs significantly enhances our data analysis capabilities. By leveraging this method, we achieve an accuracy rate with a false positive rate as low as three to five percent, eliminating the need for extensive pre-training.
Sentra’s Data Sensitivity Estimation Methodologies
Accurate classification is only a (very crucial) step to determine if a document is sensitive. At the end of the day, a customer must be able to also discern whether a document contains the addresses, phone numbers or emails of the company’s offices, or the company’s clients.
Accumulated Knowledge
Sentra has developed domain expertise to predict which objects are generally considered more sensitive. For example, documents with login information are more sensitive compared to documents containing random names.
Sentra has developed the main expertise based on our collected AI analysis over time.
How does Sentra accumulate the knowledge? (is it via AI/ML?)
Sentra accumulates knowledge both from combining insights from our experience with current customers and their needs with machine learning models that continuously improve based on the data they are trained with over time.
Customer-Specific Needs
Sentra tailors sensitivity models to each customer’s specific needs, allowing feedback and examples to refine our models for optimal results. This customization ensures that sensitivity estimation models are precisely tuned to each customer’s requirements.
What is an example of a customer-specific need?
For instance, one of our customers required a particular combination of PII (personally identifiable information) and NPPI (nonpublic personal information). We tailored our solution by creating a composite classifier to meet their needs by designating documents containing these combinations as having a higher sensitivity level.
Sentra’s sensitivity assessment (that drives classification definition) can be based on detected data classes, document labels, and detection volumes, which triggers extra analysis from our system if needed.
Conclusion
In summary, Sentra’s comprehensive approach to data classification and sensitivity estimation ensures precise and adaptable handling of sensitive data, supporting robust data security at scale. With accurate, granular data classification, security teams can confidently proceed to remediation steps without need for further validation - saving time and streamlining processes. Further, accurate tags allow for automation - by sharing contextual sensitivity data with upstream controls (ex. DLP systems) and remediation workflow tools (ex. ITSM or SOAR).
Additionally, our research and development teams stay abreast of the rapid advancements in Generative AI, particularly focusing on Large Language Models (LLMs). This proactive approach to data classification ensures our models not only meet but often exceed industry standards, delivering state-of-the-art performance while minimizing costs. Given the fast-evolving nature of LLMs, it is highly likely that the models we use today—BERT, GPT, Mistral, and Llama—will soon be replaced by even more advanced, yet-to-be-published technologies.
<blogcta-big>

Sensitive Data Classification Challenges Security Teams Face
Sensitive Data Classification Challenges Security Teams Face
Ensuring the security of your data involves more than just pinpointing its location. It's a multifaceted process in which knowing where your data resides is just the initial step. Beyond that, accurate classification plays a pivotal role. Picture it like assembling a puzzle – having all the pieces and knowing their locations is essential, but the real mastery comes from classifying them (knowing which belong to the edge, which make up the sky in the picture, and so on…), seamlessly creating the complete picture for your proper data security and privacy programs.
Just last year, the global average cost of a data breach surged to USD 4.45 million, a 15% increase over the previous three years. This highlights the critical need to automatically discover and accurately classify personal and unique identifiers, which can transform into sensitive information when combined with other data points.
This unique capability is what sets Sentra’s approach apart— enabling the detection and proper classification of data that many solutions overlook or mis-classify.
What Is Data Classification and Why Is It Important?
Data classification is the process of organizing and labeling data based on its sensitivity and importance. This involves assigning categories like "confidential," "internal," or "public" to different types of data. It’s further helpful to understand the ‘context’ of data - it’s purpose - such as legal agreements, health information, financial record, source code/IP, etc. With data context you can more precisely understand the data’s sensitivity and accurately classify it (to apply proper policies and related violation alerting, eliminating false positives as well).
Here's why data classification is crucial in the cloud:
- Enhanced Security: By understanding the sensitivity of your data, you can implement appropriate security measures. Highly confidential data might require encryption or stricter access controls compared to publicly accessible information.
- Improved Compliance: Many data privacy regulations require organizations to classify personally identifying data to ensure its proper handling and protection. Classification helps you comply with regulations like GDPR or HIPAA.
- Reduced Risk of Breaches: Data breaches often stem from targeted attacks on specific types of information. Classification helps identify your most valuable data assets, so you can apply proper controls and minimize the impact of a potential breach.
- Efficient Management: Knowing what data you have and where it resides allows for better organization and management within the cloud environment. This can streamline processes and optimize storage costs.
Data classification acts as a foundation for effective data security. It helps prioritize your security efforts, ensures compliance, and ultimately protects your valuable data. Securing your data and mitigating privacy risks begins with a data classification solution that prioritizes privacy and security. Addressing various challenges necessitates a deeper understanding of the data, as many issues require additional context.
The end goal is automating processes and making findings actionable - which requires granular, detailed context regarding the data’s usage and purpose, to create confidence in the classification result.
In this article, we will define toxic combinations and explore specific capabilities required from a data classification solution to tackle related data security, compliance, and privacy challenges effectively.
Data Classification Challenges
Challenge 1: Unstructured Data Classification
Unstructured data is information that lacks a predefined format or organization, making it challenging to analyze and extract insights, yet it holds significant value for organizations seeking to leverage diverse data sources for informed decision-making. Examples of unstructured data include customer support chat logs, educational videos, and product photos. Detecting data classes within unstructured data with high accuracy poses a significant challenge, particularly when relying solely on simplistic methods like regular expressions and pattern matching. Unstructured data, by its very nature, lacks a predefined and organized format, making it challenging for conventional classification approaches. Legacy solutions often grapple with the difficulty of accurately discerning data classes, leading to an abundance of false positives and noise.
This highlights the need for more advanced and nuanced techniques in unstructured data classification to enhance accuracy and reduce its inherent complexities. Addressing this challenge requires leveraging sophisticated algorithms and machine learning models capable of understanding the intricate patterns and relationships within unstructured data, thereby improving the precision of data class detection.
In the search for accurate data classification within unstructured data, incorporating technologies that harness machine learning and artificial intelligence is critical. These advanced technologies possess the capability to comprehend the intricacies of context and natural language, thereby significantly enhancing the accuracy of sensitive information identification and classification.
For example, detecting a residential address is challenging because it can appear in multiple shapes and forms, and even a phone number or a GPS coordinate can be easily confused with other numbers without fully understanding the context. However, LLMs can use text-based classification techniques (NLP, keyword matching, etc.) to accurately classify this type of unstructured data. Furthermore, understanding the context surrounding each data asset, whether it be a table or a file, becomes paramount. Whether it pertains to a legal agreement, employee contract, e-commerce transaction, intellectual property, or tax documents, discerning the context aids in determining the nature of the data and guides the implementation of appropriate security measures. This approach not only refines the accuracy of data class detection but also ensures that the sensitivity of the unstructured data is appropriately acknowledged and safeguarded in line with its contextual significance.
Optimal solutions employ machine learning and AI technology that really understand the context and natural language in order to classify and identify sensitive information accurately. Advancements in technologies have expanded beyond text-based classification to image-based classification and audio/speech-based classification, enabling companies and individuals to efficiently and accurately classify sensitive data at scale.
Challenge 2: Customer Data vs Employee Data
Employee data and customer data are the most common data categories stored by companies in the cloud. Identifying customer and employee data is extremely important. For instance, customer data that also contains Personal Identifiable Information (PII) must be stored in compliant production environments and must not travel to lower environments such as data analytics or development.
- What is customer data?
Customer data is all the data that we store and collect from our customers and users.
- B2C - Customer data in B2C companies, includes a lot of PII about their end users, all the information they transact with our service.
- B2B - Customer data in B2B companies includes all the information of the organization itself, such as financial information, technological information, etc., depending on the organization.
This could be very sensitive information about each organization that must remain confidential or otherwise can lead to data breaches, intellectual property theft, reputation damage, etc.
- What is employee data?
Employee data includes all the information and knowledge that the employees themselves produce and consume. This could include many types of different information, depending on what team it comes from.
For instance:
-Tech and intellectual property, source code from the engineering team.
-HR information, from the HR team.
-Legal information from the legal team, source code, and many more.
It is crucial to properly classify employee and customer data, and which data falls under which category, as they must be secured differently. A good data classification solution needs to understand and differentiate the different types of data. Access to customer data should be restricted, while access to employee data depends on the organizational structure of the user’s department. This is important to enforce in every organization.
Challenge 3: Understanding Toxic Combinations
What Is a Toxic Combination?
A toxic combination occurs when seemingly innocuous data classes are combined to increase the sensitivity of the information. On their own, these pieces of information are harmless, but when put together, they become “toxic”.
The focus here extends beyond individual data pieces; it's about understanding the heightened sensitivity that emerges when these pieces come together. In essence, securing your data is not just about individual elements but understanding how these combinations create new vulnerabilities.
We can divide data findings into three main categories:
- Personal Identifiers: Piece of information that can identify a single person - for example, an email address or social security number (SSN), belongs only to one person.
- Personal Quasi Identifiers: A quasi identifier is a piece of information that by itself is not enough to identify just one person. For example, a zip code, address, an age, etc. Let’s say Bob - there are many Bobs in the world, but if we also have Bob’s address - there is most likely just one Bob living in this address.
- Sensitive Information: Each piece of information that should remain sensitive/private. Such as medical diseases, history, prescriptions, lab results, etc. automotive industry - GPS location. Sensitive data on its own is not sensitive, but the combination of identifiers with sensitive information is very sensitive.
.webp)
Finding personal identifiers by themselves, such as an email address, does not necessarily mean that the data is highly sensitive. Same with sensitive data such as medical info or financial transactions, that may not be sensitive if they can not be associated with individuals or other identifiable entities.
However, the combination of these different information types, such as personal identifiers and sensitive data together, does mean that the data requires multiple data security and protection controls and therefore it’s crucial that the classification solution will understand that.
Detecting ‘Toxic Data Combinations’ With a Composite Class Identifier
Sentra has introduced a new ‘Composite’ data class identifier to allow customers to easily build bespoke ‘toxic combinations’ classifiers they wish for Sentra to deploy to identify within their data sets.
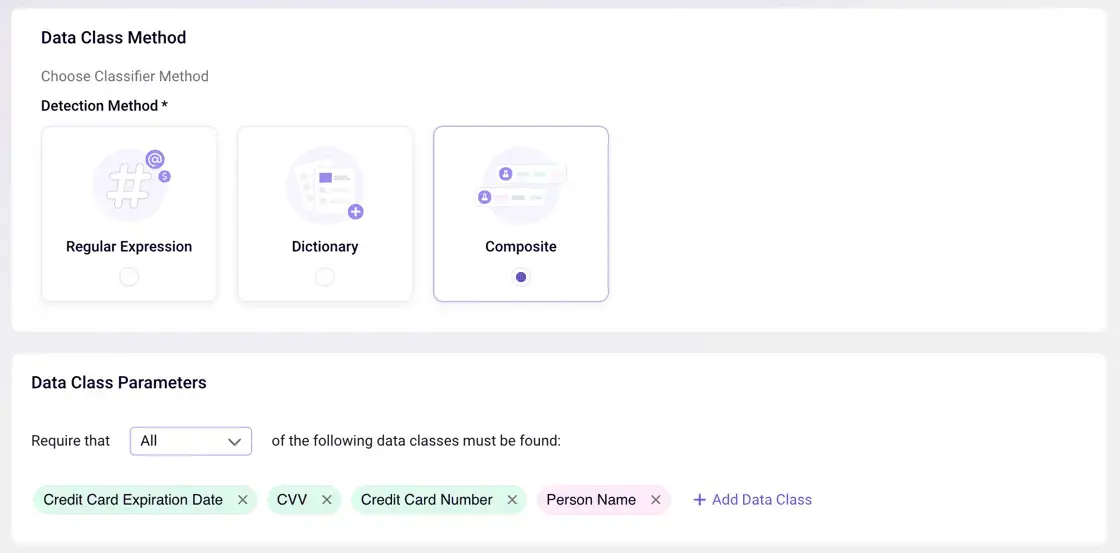
Importance of Finding Toxic Combinations
This capability is critical because having sensitive information about individuals can harm the business reputation, or cause them fines, privacy violations, and more. Under certain data privacy and protection requirements, this is even more crucial to discover and be aware of. For example, HIPAA requires protection of patient healthcare data. So, if an individual’s email is combined with his address, and his medical history (which is now associated with his email and address), this combination of information becomes sensitive data.
Challenge 4: Detecting Uncommon Personal Identifiers for Privacy Regulations
There are many different compliance regulations, such as Privacy and Data Protection Acts, which require organizations to secure and protect all personally identifiable information. With sensitive cloud data constantly in flux, there are many unknown data risks arising. This is due to a lack of visibility and an inaccurate data classification solution.Classification solutions must be able to detect uncommon or proprietary personal identifiers. For example, a product serial number that belongs to a specific individual, U.S. Vehicle Identification Number (VIN) might belong to a specific car owner, or GPS location that indicates an individual home address can be used to identify this person in other data sets.
These examples highlight the diverse nature of identifiable information. This diversity requires classification solutions to be versatile and capable of recognizing a wide range of personal identifiers beyond the typical ones.
Organizations are urged to implement classification solutions that both comply with general privacy and data protection regulations and also possess the sophistication to identify and protect against a broad spectrum of personal identifiers, including those that are unconventional or proprietary in nature. This ensures a comprehensive approach to safeguarding sensitive information in accordance with legal and privacy requirements.
Challenge 5: Adhering to Data Localization Requirements
Data Localization refers to the practice of storing and processing data within a specific geographic region or jurisdiction. It involves restricting the movement and access to data based on geographic boundaries, and can be motivated by a variety of factors, such as regulatory requirements, data privacy concerns, and national security considerations.
In adherence to the Data Localization requirements, it becomes imperative for classification solutions to understand the specific jurisdictions associated with each of the data subjects that are found in Personal Identifiable Information (PII) they belong to.For example, if we find a document with PII, we need to know if this PII belongs to Indian residents, California residents or German citizens, to name a few. This will then dictate, for example, in which geography this data must be stored and allow the solution to indicate any violations of data privacy and data protection frameworks, such as GDPR, CCPA or DPDPA.
Below is an example of Sentra’s Monthly Data Security Report: GDPR
.webp)
.png)
Why Data Localization Is Critical
- Adhering to local laws and regulations: Ensure data storage and processing within specific jurisdictions is a crucial aspect for organizations. For instance, certain countries mandate the storage and processing of specific data types, such as personal or financial data, within their borders, compelling organizations to meet these requirements and avoid potential fines or penalties.
- Protecting data privacy and security: By storing and processing data within a specific jurisdiction, organizations can have more control over who has access to the data, and can take steps to protect it from unauthorized access or breaches. This approach allows organizations to exert greater control over data access, enabling them to implement measures that safeguard it from unauthorized access or potential breaches.
- Supporting national security and sovereignty: Some countries may want to store and process data within their borders. This decision is driven by the desire to have more control over their own data and protect their citizens' information from foreign governments or entities, emphasizing the role of data localization in supporting these strategic objectives.
Conclusion: Sentra’s Data Classification Solution
Sentra provides the granular classification capabilities to discern and accurately classify the formerly difficult to classify data types just mentioned. Through a variety of analysis methods, we address those data types and obscure combinations that are crucial to effective data security. These combinations too often lead to false positives and disappointment in traditional classification systems.
In review, Sentra’s data classification solution accurately:
- Classifies Unstructured data by applying advanced AI/ML analysis techniques
- Discerns Employee from Customer data by analyzing rich business context
- Identifies Toxic Combinations of sensitive data via advanced data correlation techniques
- Detects Uncommon Personal Identifiers to comply with stringent privacy regulations
- Understands PII Jurisdiction to properly map to applicable sovereignty requirements
To learn more, visit Sentra’s data classification use case page or schedule a demo with one of our experts.
<blogcta-big>