's Data Security Posts

Use Redshift Data Scrambling for Additional Data Protection
Use Redshift Data Scrambling for Additional Data Protection
According to IBM, a data breach in the United States cost companies an average of 9.44 million dollars in 2022. It is now more important than ever for organizations to place high importance on protecting confidential information. Data scrambling, which can add an extra layer of security to data, is one approach to accomplish this.
In this post, we'll analyze the value of data protection, look at the potential financial consequences of data breaches, and talk about how Redshift Data Scrambling may help protect private information.
The Importance of Data Protection
Data protection is essential to safeguard sensitive data from unauthorized access. Identity theft, financial fraud,and other serious consequences are all possible as a result of a data breach. Data protection is also crucial for compliance reasons. Sensitive data must be protected by law in several sectors, including government, banking, and healthcare. Heavy fines, legal problems, and business loss may result from failure to abide by these regulations.
Hackers employ many techniques, including phishing, malware, insider threats, and hacking, to get access to confidential information. For example, a phishing assault may lead to the theft of login information, and malware may infect a system, opening the door for additional attacks and data theft.
So how to protect yourself against these attacks and minimize your data attack surface?
What is Redshift Data Masking?
Redshift data masking is a technique used to protect sensitive data in Amazon Redshift; a cloud-based data warehousing and analytics service. Redshift data masking involves replacing sensitive data with fictitious, realistic values to protect it from unauthorized access or exposure. It is possible to enhance data security by utilizing Redshift data masking in conjunction with other security measures, such as access control and encryption, in order to create a comprehensive data protection plan.
What is Redshift Data Scrambling?
Redshift data scrambling protects confidential information in a Redshift database by altering original data values using algorithms or formulas, creating unrecognizable data sets. This method is beneficial when sharing sensitive data with third parties or using it for testing, development, or analysis, ensuring privacy and security while enhancing usability.
The technique is highly customizable, allowing organizations to select the desired level of protection while maintaining data usability. Redshift data scrambling is cost-effective, requiring no additional hardware or software investments, providing an attractive, low-cost solution for organizations aiming to improve cloud data security.
Data Masking vs. Data Scrambling
Data masking involves replacing sensitive data with a fictitious but realistic value. However, data scrambling, on the other hand, involves changing the original data values using an algorithm or a formula to generate a new set of values.
In some cases, data scrambling can be used as part of data masking techniques. For instance, sensitive data such as credit card numbers can be scrambled before being masked to enhance data protection further.
Setting up Redshift Data Scrambling
Having gained an understanding of Redshift and data scrambling, we can now proceed to learn how to set it up for implementation. Enabling data scrambling in Redshift requires several steps.
To achieve data scrambling in Redshift, SQL queries are utilized to invoke built-in or user-defined functions. These functions utilize a blend of cryptographic techniques and randomization to scramble the data.
The following steps are explained using an example code just for a better understanding of how to set it up:
Step 1: Create a new Redshift cluster
Create a new Redshift cluster or use an existing cluster if available.
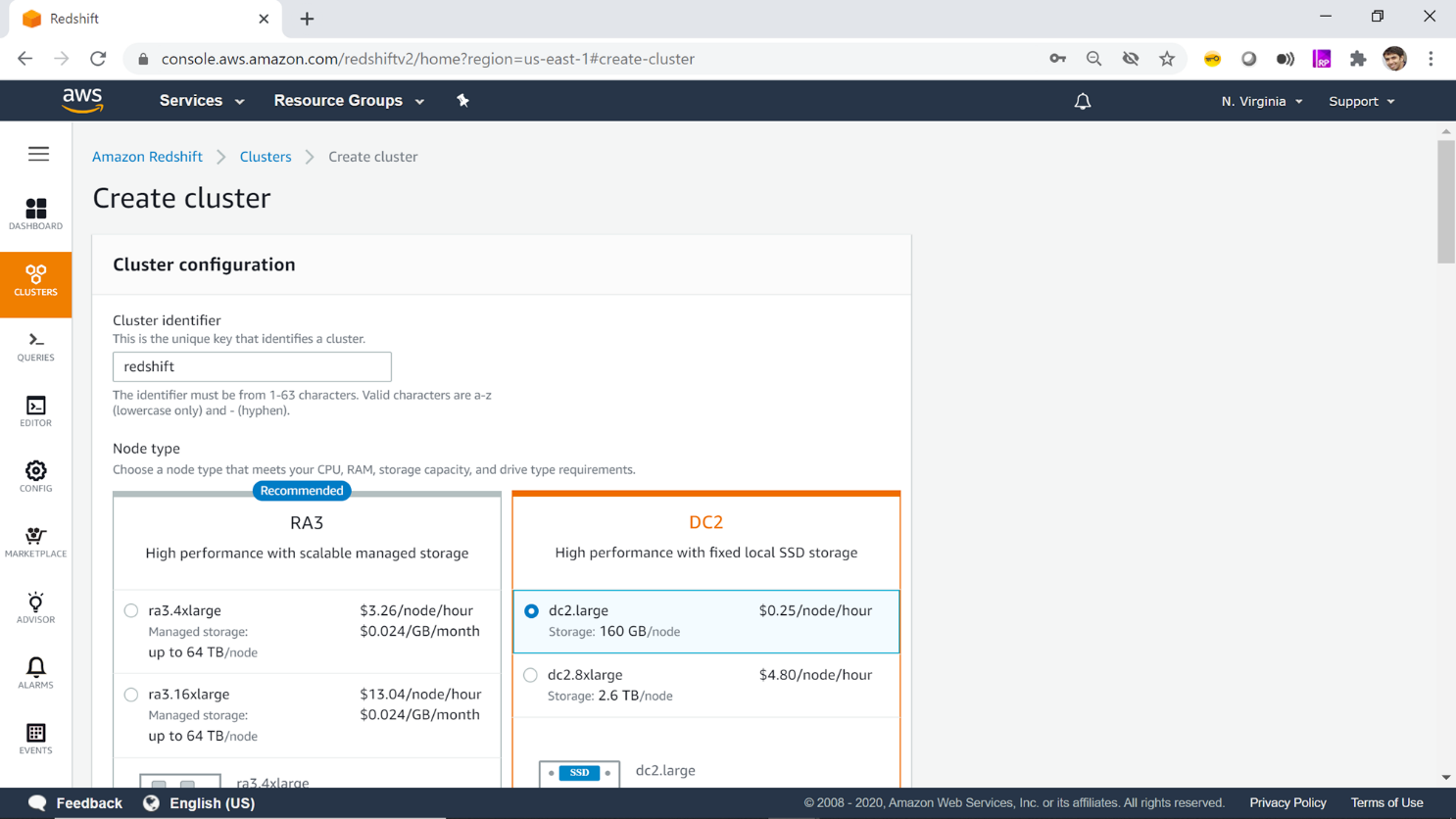
Step 2: Define a scrambling key
Define a scrambling key that will be used to scramble the sensitive data.
In this code snippet, we are defining a scrambling key by setting a session-level parameter named <inlineCode>my_scrambling_key<inlineCode> to the value <inlineCode>MyScramblingKey<inlineCode>. This key will be used by the user-defined function to scramble the sensitive data.
Step 3: Create a user-defined function (UDF)
Create a user-defined function in Redshift that will be used to scramble the sensitive data.
Here, we are creating a UDF named <inlineCode>scramble<inlineCode> that takes a string input and returns the scrambled output. The function is defined as <inlineCode>STABLE<inlineCode>, which means that it will always return the same result for the same input, which is important for data scrambling. You will need to input your own scrambling logic.
Step 4: Apply the UDF to sensitive columns
Apply the UDF to the sensitive columns in the database that need to be scrambled.
For example, applying the <inlineCode>scramble<inlineCode> UDF to a column saying, <inlineCode>ssn<inlineCode> in a table named <inlineCode>employee<inlineCode>. The <inlineCode>UPDATE<inlineCode> statement calls the <inlineCode>scramble<inlineCode> UDF and updates the values in the <inlineCode>ssn<inlineCode> column with the scrambled values.
Step 5: Test and validate the scrambled data
Test and validate the scrambled data to ensure that it is unreadable and unusable by unauthorized parties.
In this snippet, we are running a <inlineCode>SELECT<inlineCode> statement to retrieve the <inlineCode>ssn<inlineCode> column and the corresponding scrambled value using the <inlineCode>scramble<inlineCode> UDF. We can compare the original and scrambled values to ensure that the scrambling is working as expected.
Step 6: Monitor and maintain the scrambled data
To monitor and maintain the scrambled data, we can regularly check the sensitive columns to ensure that they are still rearranged and that there are no vulnerabilities or breaches. We should also maintain the scrambling key and UDF to ensure that they are up-to-date and effective.
Different Options for Scrambling Data in Redshift
Selecting a data scrambling technique involves balancing security levels, data sensitivity, and application requirements. Various general algorithms exist, each with unique pros and cons. To scramble data in Amazon Redshift, you can use the following Python code samples in conjunction with a library like psycopg2 to interact with your Redshift cluster. Before executing the code samples, you will need to install the psycopg2 library:
Random
Utilizing a random number generator, the Random option quickly secures data, although its susceptibility to reverse engineering limits its robustness for long-term protection.
Shuffle
The Shuffle option enhances security by rearranging data characters. However, it remains prone to brute-force attacks, despite being harder to reverse-engineer.
Reversible
By scrambling characters in a decryption key-reversible manner, the Reversible method poses a greater challenge to attackers but is still vulnerable to brute-force attacks. We’ll use the Caesar cipher as an example.
Custom
The Custom option enables users to create tailor-made algorithms to resist specific attack types, potentially offering superior security. However, the development and implementation of custom algorithms demand greater time and expertise.
Best Practices for Using Redshift Data Scrambling
There are several best practices that should be followed when using Redshift Data Scrambling to ensure maximum protection:
Use Unique Keys for Each Table
To ensure that the data is not compromised if one key is compromised, each table should have its own unique key pair. This can be achieved by creating a unique index on the table.
Encrypt Sensitive Data Fields
Sensitive data fields such as credit card numbers and social security numbers should be encrypted to provide an additional layer of security. You can encrypt data fields in Redshift using the ENCRYPT function. Here's an example of how to encrypt a credit card number field:
Use Strong Encryption Algorithms
Strong encryption algorithms such as AES-256 should be used to provide the strongest protection. Redshift supports AES-256 encryption for data at rest and in transit.
Control Access to Encryption Keys
Access to encryption keys should be restricted to authorized personnel to prevent unauthorized access to sensitive data. You can achieve this by setting up an AWS KMS (Key Management Service) to manage your encryption keys. Here's an example of how to restrict access to an encryption key using KMS in Python:
Regularly Rotate Encryption Keys
Regular rotation of encryption keys ensures that any compromised keys do not provide unauthorized access to sensitive data. You can schedule regular key rotation in AWS KMS by setting a key policy that specifies a rotation schedule. Here's an example of how to schedule annual key rotation in KMS using the AWS CLI:
Turn on logging
To track user access to sensitive data and identify any unwanted access, logging must be enabled. All SQL commands that are executed on your cluster are logged when you activate query logging in Amazon Redshift. This applies to queries that access sensitive data as well as data-scrambling operations. Afterwards, you may examine these logs to look for any strange access patterns or suspect activities.
You may use the following SQL statement to make query logging available in Amazon Redshift:
The stl query system table may be used to retrieve the logs once query logging has been enabled. For instance, the SQL query shown below will display all queries that reached a certain table:
Monitor Performance
Data scrambling is often a resource-intensive practice, so it’s good to monitor CPU usage, memory usage, and disk I/O to ensure your cluster isn’t being overloaded. In Redshift, you can use the <inlineCode>svl_query_summary<inlineCode> and <inlineCode>svl_query_report<inlineCode> system views to monitor query performance. You can also use Amazon CloudWatch to monitor metrics such as CPU usage and disk space.
Establishing Backup and Disaster Recovery
In order to prevent data loss in the case of a disaster, backup and disaster recovery mechanisms should be put in place. Automated backups and manual snapshots are only two of the backup and recovery methods offered by Amazon Redshift. Automatic backups are taken once every eight hours by default.
Moreover, you may always manually take a snapshot of your cluster. In the case of a breakdown or disaster, your cluster may be restored using these backups and snapshots. Use this SQL query to manually take a snapshot of your cluster in Amazon Redshift:
To restore a snapshot, you can use the <inlineCode>RESTORE<inlineCode> command. For example:
Frequent Review and Updates
To ensure that data scrambling procedures remain effective and up-to-date with the latest security requirements, it is crucial to consistently review and update them. This process should include examining backup and recovery procedures, encryption techniques, and access controls.
In Amazon Redshift, you can assess access controls by inspecting all roles and their associated permissions in the <inlineCode>pg_roles<inlineCode> system catalog database. It is essential to confirm that only authorized individuals have access to sensitive information.
To analyze encryption techniques, use the <inlineCode>pg_catalog.pg_attribute<inlineCode> system catalog table, which allows you to inspect data types and encryption settings for each column in your tables. Ensure that sensitive data fields are protected with robust encryption methods, such as AES-256.
The AWS CLI commands <inlineCode>aws backup plan<inlineCode> and <inlineCode>aws backup vault<inlineCode> enable you to review your backup plans and vaults, as well as evaluate backup and recovery procedures. Make sure your backup and recovery procedures are properly configured and up-to-date.
Decrypting Data in Redshift
There are different options for decrypting data, depending on the encryption method used and the tools available; the decryption process is similar to of encryption, usually a custom UDF is used to decrypt the data, let’s look at one example of decrypting data scrambling with a substitution cipher.
Step 1: Create a UDF with decryption logic for substitution
Step 2: Move the data back after truncating and applying the decryption function
In this example, encrypted_column2 is the encrypted version of column2 in the temp_table. The decrypt_substitution function is applied to encrypted_column2, and the result is inserted into the decrypted_column2 in the original_table. Make sure to replace column1, column2, and column3 with the appropriate column names, and adjust the INSERT INTO statement accordingly if you have more or fewer columns in your table.
Conclusion
Redshift data scrambling is an effective tool for additional data protection and should be considered as part of an organization's overall data security strategy. In this blog post, we looked into the importance of data protection and how this can be integrated effectively into the data warehouse. Then, we covered the difference between data scrambling and data masking before diving into how one can set up Redshift data scrambling.
Once you begin to accustom to Redshift data scrambling, you can upgrade your security techniques with different techniques for scrambling data and best practices including encryption practices, logging, and performance monitoring. Organizations may improve their data security posture management (DSPM) and reduce the risk of possible breaches by adhering to these recommendations and using an efficient strategy.
<blogcta-big>

Ghosts in the Model: Uncovering Generative AI Risks
Ghosts in the Model: Uncovering Generative AI Risks
Generative AI risks are no longer hypothetical. They’re shaping the way enterprises think about cloud security. As artificial intelligence (AI) becomes deeply integrated into enterprise workflows, organizations are increasingly leveraging cloud-based AI services to enhance efficiency and decision-making.
In 2024, 56% of organizations adopted AI to develop custom applications, with 39% of Azure users leveraging Azure OpenAI services. However, with rapid AI adoption in cloud environments, security risks are escalating. As AI continues to shape business operations, the security and privacy risks associated with cloud-based AI services must not be overlooked. Understanding these risks (and how to mitigate them) is essential for organizations looking to protect their proprietary models and sensitive data.
Types of Generative AI Risks in Cloud Environments
When discussing AI services in cloud environments, there are two primary types of services that introduce different types of security and privacy risks. This article dives into these risks and explores best practices to mitigate them, ensuring organizations can leverage AI securely and effectively.
1. Data Exposure and Access Risks in Generative AI Platforms
Examples include OpenAI, Google, Meta, and Microsoft, which develop large-scale AI models and provide AI-related services, such as Azure OpenAI, Amazon Bedrock, Google’s Bard, Microsoft Copilot Studio. These services allow organizations to build AI Agents and GenAI services that are designed to help users perform tasks more efficiently by integrating with existing tools and platforms. For instance, Microsoft Copilot can provide writing suggestions, summarize documents, or offer insights within platforms like Word or Excel, though securing regulated data in Microsoft 365 Copilot requires specific security considerations..
What is RAG (Retrieval-Augmented Generation)?
Many AI systems use Retrieval-Augmented Generation (RAG) to improve accuracy. Instead of solely relying on a model’s pre-trained knowledge, RAG allows the system to fetch relevant data from external sources, such as a vector database, using algorithms like k-nearest neighbor. This retrieved information is then incorporated into the model’s response.
When used in enterprise AI applications, RAG enables AI agents to provide contextually relevant responses. However, it also introduces a risk - if access controls are too broad, users may inadvertently gain access to sensitive corporate data.
How Does RAG (Retrieval-Augmented Generation) Apply to AI Agents?
In AI agents, RAG is typically used to enhance responses by retrieving relevant information from a predefined knowledge base.
Example: In AWS Bedrock, you can define a serverless vector database in OpenSearch as a knowledge base for a custom AI agent. This setup allows the agent to retrieve and incorporate relevant context dynamically, effectively implementing RAG.
Generative AI Risks and Security Threats of AI Platforms
Custom generative AI applications, such as AI agents or enterprise-built copilots, are often integrated with organizational knowledge bases like Amazon S3, SharePoint, Google Drive, and other data sources. While these models are typically not directly trained on sensitive corporate data, the fact that they can access these sources creates significant security risks.
One potential generative AI risk is data exposure through prompts, but this only arises under certain conditions. If access controls aren’t properly configured, users interacting with AI agents might unintentionally or maliciously - prompt the model to retrieve confidential or private information.This isn’t limited to cleverly crafted prompts; it reflects a broader issue of improper access control and governance.
Configuration and Access Control Risks
The configuration of the AI agent is a critical factor. If an agent is granted overly broad access to enterprise data without proper role-based restrictions, it can return sensitive information to users who lack the necessary permissions. For instance, a model connected to an S3 bucket with sensitive customer data could expose that data if permissions aren’t tightly controlled. Simple misconfigurations can lead to serious data exposure incidents, even in applications designed for security.
A common scenario might involve an AI agent designed for Sales that has access to personally identifiable information (PII) or customer records. If the agent is not properly restricted, it could be queried by employees outside of Sales, such as developers - who should not have access to that data.
Example Generative AI Risk Scenario
An employee asks a Copilot-like agent to summarize company-wide sales data. The AI returns not just high-level figures, but also sensitive customer or financial details that were unintentionally exposed due to lax access controls.
Challenges in Mitigating Generative AI Risks
The core challenge, particularly relevant to platforms like Sentra, is enforcing governance to ensure only appropriate data is used and accessible by AI services.
This includes:
- Defining and enforcing granular data access controls.
- Preventing misconfigurations or overly permissive settings.
- Maintaining real-time visibility into which data sources are connected to AI models.
- Continuously auditing data flows and access patterns to prevent leaks.
Without rigorous governance and monitoring, even well-intentioned GenAI implementations can lead to serious data security incidents.
2. ML and AI Studios for Building New Models
Many companies, such as large financial institutions, build their own AI and ML models to make better business decisions, or to improve their user experiences. Unlike large foundational models from major tech companies, these custom AI models are trained by the organization itself on their applications or corporate data.
Security Risks of Custom AI Models
- Weak Data Governance Policies - If data governance policies are inadequate, sensitive information, such as customers' Personally Identifiable Information (PII), could be improperly accessed or shared during the training process. This can lead to data breaches, privacy compliance violations, and unethical AI usage. The growing recognition of generative AI-related risks has driven the development of more AI compliance frameworks that are now being actively enforced with significant penalties..
- Excessive Access to Training Data and AI Models - Granting unrestricted access to training datasets and machine learning (ML)/AI models increases the risk of data leaks and misuse. Without proper access controls, sensitive data used in training can be exposed to unauthorized individuals, leading to compliance and security concerns.
- AI Agents Exposing Sensitive Data - AI agents that do not have proper safeguards can inadvertently expose sensitive information to a broad audience within an organization. For example, an employee could retrieve confidential data such as the CEO’s salary or employment contracts if access controls are not properly enforced.
- Insecure Model Storage – Once a model is trained, it is typically stored in the same environment (e.g., in Amazon SageMaker, the training job stores the trained model in S3). If not properly secured, proprietary models could be exposed to unauthorized access, leading to risks such as model theft.
- Deployment Vulnerabilities – A lack of proper access controls can result in unauthorized use of AI models. Organizations need to assess who has access: Is the model public? Can external entities interact with or exploit it?
Shadow AI and Forgotten Assets – AI models or artifacts that are not actively monitored or properly decommissioned can become a security risk. These overlooked assets can serve as attack vectors if discovered by malicious actors.

Example Risk Scenario
A bank develops an AI-powered feature that predicts a customer’s likelihood of repaying a loan based on inputs like financial history, employment status, and other behavioral indicators. While this feature is designed to enhance decision-making and customer experience, it introduces significant generative AI risk if not properly governed.
During development and training, the model may be exposed to personally identifiable information (PII), such as names, addresses, social security numbers, or account details, which is not necessary for the model’s predictive purpose.
⚠️ Best practice: Models should be trained only on the minimum necessary data required for performance, excluding direct identifiers unless absolutely essential. This reduces both privacy risk and regulatory exposure.
If the training pipeline fails to properly separate or mask this PII, the model could unintentionally leak sensitive information. For example, when responding to an end-user query, the AI might reference or infer details from another individual’s record - disclosing sensitive customer data without authorization.
This kind of data leakage, caused by poor data handling or weak governance during training, can lead to serious regulatory non-compliance, including violations of GDPR, CCPA, or other privacy frameworks.
Common Risk Mitigation Strategies and Their Limitations
Many organizations attempt to manage generative AI-related risks through employee training and awareness programs. Employees are taught best practices for handling sensitive data and using AI tools responsibly.
While valuable, this approach has clear limitations:
- Training Alone Is Insufficient:
Human error remains a major risk factor, even with proper training. Employees may unintentionally connect sensitive data sources to AI models or misuse AI-generated outputs. - Lack of Automated Oversight:
Most organizations lack robust, automated systems to continuously monitor how AI models use data and to enforce real-time security policies. Manual review processes are often too slow and incomplete to catch complex data access risks in dynamic, cloud-based AI environments.
- Policy Gaps and Visibility Challenges:
Organizations often operate with multiple overlapping data layers and services. Without clear, enforceable policies, especially automated ones - certain data assets may remain unscanned or unprotected, creating blind spots and increasing risk.
Reducing AI Risks with Sentra’s Comprehensive Data Security Platform
Managing generative AI risks in the cloud requires more than employee training.
Organizations need to adopt robust data governance frameworks and data security platforms (like Sentra’s) that address the unique challenges of AI.
This includes:
- Discovering AI Assets: Automatically identify AI agents, knowledge bases, datasets, and models across the environment.
- Classifying Sensitive Data: Use automated classification and tagging to detect and label sensitive information accurately.
Monitoring AI Data Access: Detect which AI agents and models are accessing sensitive data, or using it for training - in real time. - Enforcing Access Governance: Govern AI integrations with knowledge bases by role, data sensitivity, location, and usage to ensure only authorized users can access training data, models, and artifacts.
- Automating Data Protection: Apply masking, encryption, access controls, and other protection methods through automated remediation capabilities across data and AI artifacts used in training and inference processes.
By combining strong technical controls with ongoing employee training, organizations can significantly reduce the risks associated with AI services and ensure compliance with evolving data privacy regulations.
<blogcta-big>
AI: Balancing Innovation with Data Security
AI: Balancing Innovation with Data Security
The Rise of AI
Artificial Intelligence (AI) is a broad discipline focused on creating machines capable of mimicking human intelligence and more specifically…learning. It even dates back to the 1950s.
These tasks might include understanding natural language, recognizing images, solving complex problems, and even driving cars. Unlike traditional software, AI systems can learn from experience, adapt to new inputs, and perform human-like tasks by processing large amounts of data.
Today, around 42% of companies have reported exploring AI use within their company, and over 50% of companies plan to incorporate AI technologies in 2024. The AI Market is expected to reach a staggering $407 billion by 2027.
What Is the Difference Between AI, ML and LLM?
AI encompasses a vast range of technologies, including Machine Learning (ML), Generative AI (GAI), and Large Language Models (LLM), among others.
Machine Learning, a subset of AI, was developed in the 1980s. Its main focus is on enabling machines to learn from data, improve their performance, and make decisions without explicit programming. Google's search algorithm is a prime example of an ML application, using previous data to refine search results.
Generative AI (GAI), evolved from ML in the early 21st century, represents a class of algorithms capable of generating new data. They construct data that resembles the input, making them essential in fields like content creation and data augmentation.
Large Language Models (LLM) also arose from the GAI subset. LLMs generate human-like text by predicting the likelihood of a word given the previous words used in the text. They are the core technology behind many voice assistants and chatbots. One of the most well-known examples of LLMs is OpenAI's ChatGPT model.
LLMs are trained on huge sets of data — which is why they are called "large" language models. LLMs are built on machine learning: specifically, a type of neural network called a transformer model.
In simpler terms, an LLM is a computer program that has been fed enough examples to be able to recognize and interpret human language or other types of complex data. Many LLMs are trained on data that has been gathered from the Internet — thousands or even millions of gigabytes' worth of text. But the quality of the samples impacts how well LLMs will learn natural language, so LLM's programmers may use a more curated data set.
Here are some of the main functions LLMs currently serve:
- Natural language generation
- Language translation
- Sentiment analysis
- Content creation
What is AI SPM?
AI-SPM (artificial intelligence security posture management) is a comprehensive approach to securing artificial intelligence and machine learning. It includes identifying and addressing vulnerabilities, misconfigurations, and potential risks associated with AI applications and training data sets, as well as ensuring compliance with relevant data privacy and security regulations.
How Can AI Help Data Security?
With data breaches and cyber threats becoming increasingly sophisticated, having a way of securing data with AI is paramount. AI-powered security systems can rapidly identify and respond to potential threats, learning and adapting to new attack patterns faster than traditional methods. According to a 2023 report by IBM, the average time to identify and contain a data breach was reduced by nearly 50% when AI and automation were involved.
By leveraging machine learning algorithms, these systems can detect anomalies in real-time, ensuring that sensitive information remains protected. Furthermore, AI can automate routine security tasks, freeing up human experts to focus on more complex challenges. Ultimately, AI-driven data security not only enhances protection but also provides a robust defense against evolving cyber threats, safeguarding both personal and organizational data.
What Do You Need to Secure
So now that we have defined Artificial Intelligence, Machine Learning and Large Language Models, it’s time to get familiar with the data flow and its components. Understanding the data flows can help us identify those vulnerable points where we can improve data security.
The process can be illustrated with the following flow:
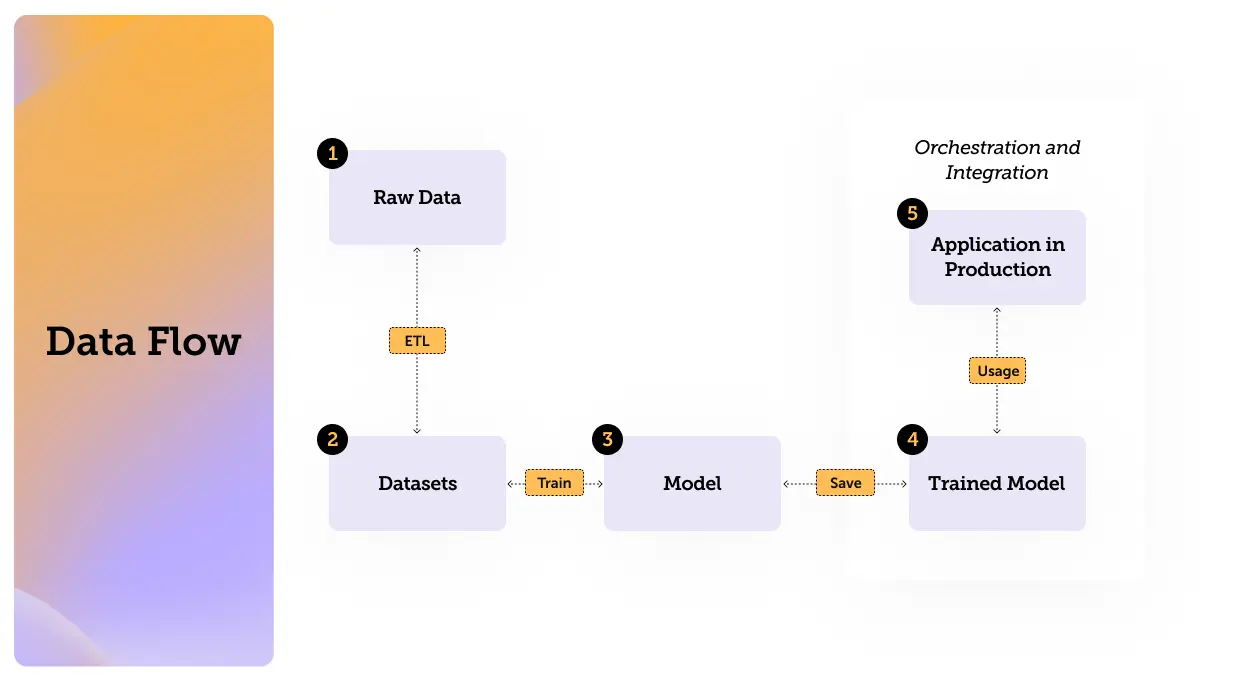
(If you are already familiar with datasets models and everything in between feel free to jump straight to the threats section)
Understanding Training Datasets
The main component of the first stage we will discuss is the training dataset.
Training datasets are collections of labeled or unlabeled data used to train, validate, and test machine learning models. They can be identified by their structured nature and the presence of input-output pairs for supervised learning.
Training datasets are essential for training models, as they provide the necessary information for the model to learn and make predictions. They can be manually created, parsed using tools like Glue and ETLs, or sourced from predefined open-source datasets such as those from HuggingFace, Kaggle, and GitHub.
Training datasets can be stored locally on personal computers, virtual servers, or in cloud storage services such as AWS S3, RDS, and Glue.
Examples of training datasets include image datasets for computer vision tasks, text datasets for natural language processing, and tabular datasets for predictive modeling.
What is a Machine Learning Model?
This brings us to the next component: models.
A model in machine learning is a mathematical representation that learns from data to make predictions or decisions. Models can be pre-trained, like GPT-4, GPT-4.5, and LLAMA, or developed in-house.
Models are trained using training datasets. The training process involves feeding the model data so it can learn patterns and relationships within the data. This process requires compute power and be done using containers, or services such as AWS SageMaker and Bedrock. The output is a bunch of parameters that are used to fine tune the model. If someone gets their hand on those parameters it's as if they trained the model themselves.
Once trained, models can be used to predict outcomes based on new inputs. They are deployed in production environments to perform tasks such as classification, regression, and more.
How Data Flows: Orchestration and Integration
This leads us to our last stage which is the Orchestration and Integration (Flow). These tools manage the deployment and execution of models, ensuring they perform as expected in production environments. They handle the workflow of machine learning processes, from data ingestion to model deployment.
Integration: Integrating models into applications involves using APIs and other interfaces to allow seamless communication between the model and the application. This ensures that the model's predictions are utilized effectively.
Possible Threats: Orchestration tools can be exploited to perform LLM attacks, where vulnerabilities in the deployment and management processes are targeted.
We will cover this in the next chapter of this article.
Conclusion
We reviewed what AI is composed of and examined the individual components, including data flows and how they function within the broader AI ecosystem. In the part 2 episode of this 3 part series, we’ll explore LLM attack techniques and threats.
With Sentra, your team will gain visibility and control into any training dataset, models and AI applications in your cloud environments, such as AWS. By using Sentra, you can minimize data security risks in our AI applications and ensure they remain secure without sacrificing efficiency or performance. Sentra can help you navigate the complexities of AI security, providing the tools and knowledge necessary to protect your data and maximize the potential of your AI initiatives.
<blogcta-big>