's Data Security Posts

Why DSPM Should Take A Slice of Your 2024 Cyber Security Budget
Why DSPM Should Take A Slice of Your 2024 Cyber Security Budget
We find ourselves in interesting times. Enterprise cloud transformations have given rise to innovative cloud security technologies that are running at a pace even seasoned security leaders find head-spinning. As security professionals grapple with these evolving dynamics, they face a predicament of conflicting priorities that directly impact budget decisions.
So much innovation and possibilities, yet, the economic climate is demanding consolidation, simplification, and yes, budget cuts. So, how do you navigate this tricky balancing act? On one hand, you need to close those critical cybersecurity gaps, and on the other, you must embrace new technology to innovate and stay competitive. To add a touch more complexity, there’s the issue of CIOs suffering from "change fatigue." According to Gartner, this fatigue manifests as CIOs hesitate to invest in new projects and initiatives, pushing a portion of 2023's IT spending into 2024, a trend that is likely to continue into 2025. CIOs are prioritizing cost control, efficiencies, and automation, while scaling back those long IT projects that take ages to show returns.
Cloud Security - A Top Investment
PwC suggests that cloud security is one of the top investment areas for 2024. The cloud's complex landscape, often poorly managed, presents a significant challenge. Astoundingly, 97% of organizations have gaps in their cloud risk management plans. The cloud security arena is nothing short of a maze that is difficult to navigate, driving enterprises towards vendor consolidation in an effort to reduce complexity, drive greater predictability and achieve positive ROI quickly.
The cloud data security challenge is far from being solved, and this is precisely why the demand for Data Security Posture Management (DSPM) solutions is on the rise. DSPM shines a light on the entire multi-cloud estate by bringing in the data context. With easy integrations, DSPM enriches the entire cloud security stack, driving more operational efficiencies as a result of accurate data risk quantification and prioritization. By proactively reducing the data attack surface on an ongoing basis, DSPM plays a role in reducing the overall risk profile of the organization.
DSPM's Role in Supporting C-Suite Challenges
Sometimes amid economic uncertainty and regulatory complexities, taking a comprehensive and granular approach to prioritize data risks can greatly enhance your 2024 cybersecurity investments.
DSPM plays a vital role in addressing the intricate challenges faced by CISOs and their teams. By ensuring the correct security posture for sensitive data, DSPM brings a new level of clarity and control to data security, making it an indispensable tool for navigating the complex data risk landscape. DSPM enables CISOs to make informed decisions and stay one step ahead of evolving threats, even in the face of uncertainty.
Let's break it down and bottom line why DSPM should have a spot in your 2024 budget:
- DSPM isn't just a technology; it's a proactive and strategic approach that empowers you to harness the full potential of your cloud data while having a clear prioritized view of your most critical data risks that will impact remediation efficiency and accurate assessment of your organization’s overall risk profile.
- Reduce Cloud Storage Costs via the detection and elimination of unused data, and drive up operational efficiency from targeted and prioritized remediation efforts that focus on the critical data risks that matter.
- Cloud Data Visibility comes from DSPM providing security leaders with a crystal-clear view of their organization's most critical data risks. It offers unmatched visibility into sensitive data across multi-cloud environments, ensuring that no sensitive data remains undiscovered. The depth and breadth of data classification provides enterprises with a solid foundation to benefit from multiple use case scenarios spanning DLP, data access governance, data privacy and compliance, and cloud security enrichment.
- Manage & Monitor Risk Proactively: Thanks to its ability to understand data context, DSPM offers accurate and prioritized data risk scores. It's about embracing the intricate details within larger multi-cloud environments that enable security professionals to make well-informed decisions. Adding the layer of data sensitivity, with its nuanced scoring, enriches this context even further. DSPM tools excel at recognizing vulnerabilities, misconfigurations, and policy violations. This empowers organizations to address these issues before they escalate into incidents.
- Regulatory Compliance undertakings to abide by data protection regulations, becomes simplified with DSPM, helping organizations steer clear of hefty penalties. Security teams can align their data security practices with industry-specific data regulations and standards. Sentra assesses how your data security posture stacks up against standard compliance and security frameworks your organization needs to comply with.
- Sentra's agentless DSPM platform offers quick setup, rapid ROI, and seamless integration with your existing cloud security tools. It deploys effortlessly in your multi-cloud environment within minutes, providing valuable insights from day one. DSPM enhances your security stack, collaborating with CSPMs, CNAPPs, and CWPPs to prioritize data risks based on data sensitivity and security posture. It ensures data catalog accuracy and completeness, supports data backup, and aids SIEMs and Security Lakes in threat detection. DSPM also empowers Identity Providers for precise access control and bolsters detection and access workflows by tagging data-based cloud workloads, optimizing data management, compliance, and efficiency
The Path Forward
2024 is approaching fast, and DSPM is an investment in long-term resilience against the ever-evolving data risk landscape. In planning 2024's cybersecurity budget, it's essential to find a balance between simplification, innovation and cost reduction. DSPM plays an important part in this intricate budgeting dance and stands ready to play its part.
Why Data is the New Center of Gravity in a Connected Cloud Security Ecosystem
Why Data is the New Center of Gravity in a Connected Cloud Security Ecosystem
As many forward-thinking organizations embrace the transformational potential of innovative cloud architectures- new dimensions of risk are emerging, centered around data privacy, compliance, and the protection of sensitive data. This shift has catapulted cloud data security to the top of the Chief Information Security Officer's (CISO) agenda.
At the Gartner Security and Risk Management summit, Gartner cited some of the pressing priorities for CISOs as safeguarding data across its various forms, adopting a simplified approach, optimizing resource utilization, and achieving low-risk, high-value outcomes. While these may seem like a tall order, they provide a clear roadmap for the future of cloud security.
In light of these priorities, Gartner also highlighted the pivotal trend of integrated security systems. Imagine a holistic ecosystem where proactive and predictive controls harmonize with preventative measures and detection mechanisms. Such an environment empowers security professionals to continuously monitor, assess, detect, and respond to multifaceted risks. This integrated approach catalyzes the move from reaction to anticipation and resolution to prevention.
In this transformative ecosystem, we at Sentra believe that data is the gravitational center of connected cloud security systems and an essential element of the risk equation. Let's unpack this some more.
It's All About the Data.
Given the undeniable impact of major data breaches that have shaken organizations like Discord, Northern Ireland Police, and Docker Hub, we all know that often the most potent risks lead to sensitive data.
Security teams have many cloud security tools at their disposal, from Cloud Security Posture Management (CSPM) and Cloud Native Application Protection Platform (CNAPP) to Cloud Access Security Broker (CASB). These are all valuable tools for identifying and prioritizing risks and threats in the cloud infrastructure, network, and applications, but what really matters is the data.
Let's look at an example of a configuration issue detected in an S3 bucket. The next logical question will be what kind of data resides inside that datastore, how sensitive the data is, and how much of a risk it poses to the organization when aligned with specific security policies that have been set up. These are the critical factors that determine the real risk. Can you imagine assessing risk without understanding the data? Such an assessment would inevitably fall short, lacking the contextual depth necessary to gauge the true extent of risk.
Why is this important? Because sensitive data will raise the severity of the alert. By factoring data sensitivity into risk assessments, prioritizing data-related risks becomes more accurate. This is where Sentra's innovative technology comes into play. By automatically assigning risk scores to the most vital data risks within an organization, Sentra empowers security teams and executives with a comprehensive view of sensitive data at risk. This overview extends the option to delve deep into the root causes of vulnerabilities, even down to the code level.
Prioritized Data Risk Scoring: The Sentra Advantage
Sentra's automated risk scoring is built from a rich data security context. This context originates from a thorough understanding of various layers:
- Data Access: Who has access to the data, and how is it governed?
- User Activity: What are the users doing with the data?
- Data Movement: How does data move within a complex multi-cloud environment?
- Data Sensitivity: How sensitive is the data?
- Misconfigurations: Are there any errors that could expose data?
This creates a holistic picture of data risk, laying a firm and comprehensive foundation for Sentra's unique approach to data risk assessment and prioritized risk scoring.
Contextualizing Data Risk
Context is everything when it comes to accurate risk prioritization and scoring. Adding the layer of data sensitivity – with its nuanced scoring – further enriches this context, providing a more detailed perspective of the risk landscape. This is the essence of an integrated security system designed to empower security leaders with a clear view of their exposure while offering actionable steps for risk reduction.
The value of this approach becomes evident when security professionals are empowered to manage and monitor risk proactively. The CISO is armed with insights into the organization's vulnerabilities and the means to address them. Data security platforms, such as Sentra's, should seamlessly integrate with the workflows of risk owners. This facilitates timely action, eliminating the need for bottlenecks and unnecessary back-and-forth with security teams.
Moving Forward
The connection between cloud security and data is profound, shaping the future of cybersecurity practices. A data-centric approach to cloud security will empower organizations to harness the full potential of the cloud while safeguarding the most valuable asset: their data.
Sentra Integrates with Amazon Security Lake, Providing a Data First Security Approach
Sentra Integrates with Amazon Security Lake, Providing a Data First Security Approach
We are excited to announce Sentra’s integration with Amazon Security Lake, a fully managed security data lake service enabling organizations to automatically centralize security data from various sources, including cloud, on-premises, and third-party vendors.
Our joint capabilities enable organizations to fast track the prioritization of their most business critical data risks, based on data sensitivity scores. What’s more, enterprises can automatically classify and secure their sensitive cloud data while also analyzing the data to gain a comprehensive understanding of their security posture.
Building a Data Sensitivity Layer is Key for Prioritizing Business Critical Risks
Many security programs and products today generate a large number of alerts and notifications without understanding how sensitive the data at risk truly is. This leaves security teams overwhelmed and susceptible to alert fatigue, making it difficult to efficiently identify and prioritize the most critical risks to the business.
Bringing Sentra's unique data sensitivity scoring approach to Amazon Security Lake, organizations can now effectively protect their most valuable assets by prioritizing and remediating the security issues that pose the greatest risks to their critical data.
Moreover, many organizations leverage third-party vendors for threat detection based on security logs that are stored in Amazon Security Lake. Sentra enriches these security events with the corresponding sensitivity score, greatly improving the speed and accuracy of threat detection and reducing the response time of real-world attacks.
Sentra's technology allows security teams to easily discover, classify, and assess the sensitivity of every data store and data asset in their cloud environment. By correlating security events with the data sensitivity layer, a meaningful data context can be built, enabling organizations to more efficiently detect threats and prioritize risks, reducing the most significant risks to the business.
OCSF Opens Up Multiple Use Cases
The Open Cybersecurity Schema Framework (OCSF) is a set of standards and best practices for defining, sharing, and using cybersecurity-related data. By adopting OCSF, Sentra seamlessly exchanges cybersecurity-related data with various security tools, enhancing the efficiency and effectiveness of these solutions. Security Lake is one of the vendors that supports OCSF, enabling mutual customers to enjoy the benefit of the integration.
This powerful integration ultimately offers organizations a smart and more efficient way to prioritize and address security risks based on the sensitivity of their data. With Sentra's data-first security approach and Security Lake's analytics enabling capabilities, organizations can now effectively protect their most valuable assets and improve their overall security posture. By leveraging the power of both platforms, security teams can focus on what truly matters: securing their most sensitive data and reducing risk across their organization.
Use Redshift Data Scrambling for Additional Data Protection
Use Redshift Data Scrambling for Additional Data Protection
According to IBM, a data breach in the United States cost companies an average of 9.44 million dollars in 2022. It is now more important than ever for organizations to place high importance on protecting confidential information. Data scrambling, which can add an extra layer of security to data, is one approach to accomplish this.
In this post, we'll analyze the value of data protection, look at the potential financial consequences of data breaches, and talk about how Redshift Data Scrambling may help protect private information.
The Importance of Data Protection
Data protection is essential to safeguard sensitive data from unauthorized access. Identity theft, financial fraud,and other serious consequences are all possible as a result of a data breach. Data protection is also crucial for compliance reasons. Sensitive data must be protected by law in several sectors, including government, banking, and healthcare. Heavy fines, legal problems, and business loss may result from failure to abide by these regulations.
Hackers employ many techniques, including phishing, malware, insider threats, and hacking, to get access to confidential information. For example, a phishing assault may lead to the theft of login information, and malware may infect a system, opening the door for additional attacks and data theft.
So how to protect yourself against these attacks and minimize your data attack surface?
What is Redshift Data Masking?
Redshift data masking is a technique used to protect sensitive data in Amazon Redshift; a cloud-based data warehousing and analytics service. Redshift data masking involves replacing sensitive data with fictitious, realistic values to protect it from unauthorized access or exposure. It is possible to enhance data security by utilizing Redshift data masking in conjunction with other security measures, such as access control and encryption, in order to create a comprehensive data protection plan.
What is Redshift Data Scrambling?
Redshift data scrambling protects confidential information in a Redshift database by altering original data values using algorithms or formulas, creating unrecognizable data sets. This method is beneficial when sharing sensitive data with third parties or using it for testing, development, or analysis, ensuring privacy and security while enhancing usability.
The technique is highly customizable, allowing organizations to select the desired level of protection while maintaining data usability. Redshift data scrambling is cost-effective, requiring no additional hardware or software investments, providing an attractive, low-cost solution for organizations aiming to improve cloud data security.
Data Masking vs. Data Scrambling
Data masking involves replacing sensitive data with a fictitious but realistic value. However, data scrambling, on the other hand, involves changing the original data values using an algorithm or a formula to generate a new set of values.
In some cases, data scrambling can be used as part of data masking techniques. For instance, sensitive data such as credit card numbers can be scrambled before being masked to enhance data protection further.
Setting up Redshift Data Scrambling
Having gained an understanding of Redshift and data scrambling, we can now proceed to learn how to set it up for implementation. Enabling data scrambling in Redshift requires several steps.
To achieve data scrambling in Redshift, SQL queries are utilized to invoke built-in or user-defined functions. These functions utilize a blend of cryptographic techniques and randomization to scramble the data.
The following steps are explained using an example code just for a better understanding of how to set it up:
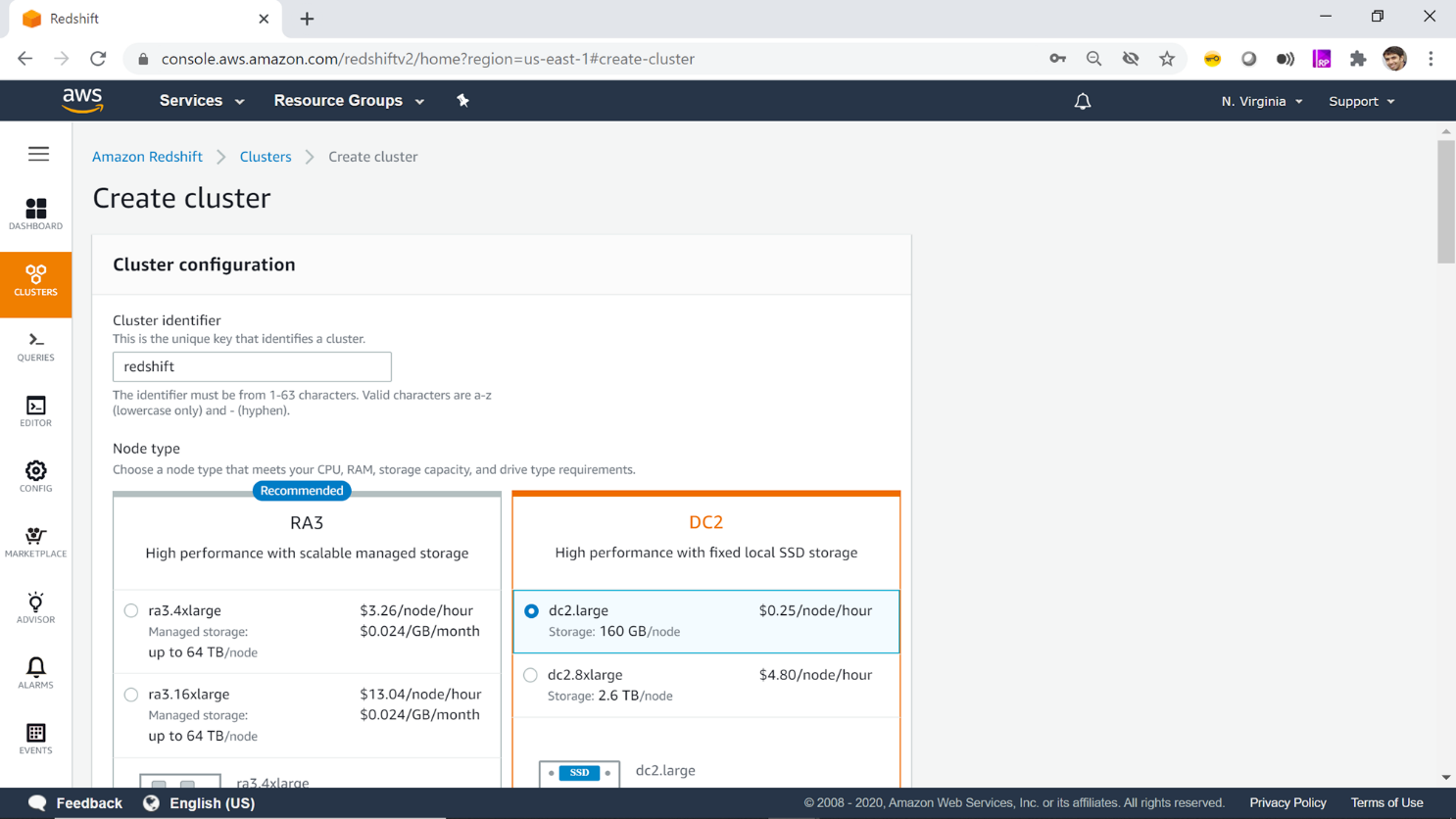
Step 1: Create a new Redshift cluster
Create a new Redshift cluster or use an existing cluster if available.
Step 2: Define a scrambling key
Define a scrambling key that will be used to scramble the sensitive data.
In this code snippet, we are defining a scrambling key by setting a session-level parameter named <inlineCode>my_scrambling_key<inlineCode> to the value <inlineCode>MyScramblingKey<inlineCode>. This key will be used by the user-defined function to scramble the sensitive data.
Step 3: Create a user-defined function (UDF)
Create a user-defined function in Redshift that will be used to scramble the sensitive data.
Here, we are creating a UDF named <inlineCode>scramble<inlineCode> that takes a string input and returns the scrambled output. The function is defined as <inlineCode>STABLE<inlineCode>, which means that it will always return the same result for the same input, which is important for data scrambling. You will need to input your own scrambling logic.
Step 4: Apply the UDF to sensitive columns
Apply the UDF to the sensitive columns in the database that need to be scrambled.
For example, applying the <inlineCode>scramble<inlineCode> UDF to a column saying, <inlineCode>ssn<inlineCode> in a table named <inlineCode>employee<inlineCode>. The <inlineCode>UPDATE<inlineCode> statement calls the <inlineCode>scramble<inlineCode> UDF and updates the values in the <inlineCode>ssn<inlineCode> column with the scrambled values.
Step 5: Test and validate the scrambled data
Test and validate the scrambled data to ensure that it is unreadable and unusable by unauthorized parties.
In this snippet, we are running a <inlineCode>SELECT<inlineCode> statement to retrieve the <inlineCode>ssn<inlineCode> column and the corresponding scrambled value using the <inlineCode>scramble<inlineCode> UDF. We can compare the original and scrambled values to ensure that the scrambling is working as expected.
Step 6: Monitor and maintain the scrambled data
To monitor and maintain the scrambled data, we can regularly check the sensitive columns to ensure that they are still rearranged and that there are no vulnerabilities or breaches. We should also maintain the scrambling key and UDF to ensure that they are up-to-date and effective.
Different Options for Scrambling Data in Redshift
Selecting a data scrambling technique involves balancing security levels, data sensitivity, and application requirements. Various general algorithms exist, each with unique pros and cons. To scramble data in Amazon Redshift, you can use the following Python code samples in conjunction with a library like psycopg2 to interact with your Redshift cluster. Before executing the code samples, you will need to install the psycopg2 library:
Random
Utilizing a random number generator, the Random option quickly secures data, although its susceptibility to reverse engineering limits its robustness for long-term protection.
Shuffle
The Shuffle option enhances security by rearranging data characters. However, it remains prone to brute-force attacks, despite being harder to reverse-engineer.
Reversible
By scrambling characters in a decryption key-reversible manner, the Reversible method poses a greater challenge to attackers but is still vulnerable to brute-force attacks. We’ll use the Caesar cipher as an example.
Custom
The Custom option enables users to create tailor-made algorithms to resist specific attack types, potentially offering superior security. However, the development and implementation of custom algorithms demand greater time and expertise.
Best Practices for Using Redshift Data Scrambling
There are several best practices that should be followed when using Redshift Data Scrambling to ensure maximum protection:
Use Unique Keys for Each Table
To ensure that the data is not compromised if one key is compromised, each table should have its own unique key pair. This can be achieved by creating a unique index on the table.
Encrypt Sensitive Data Fields
Sensitive data fields such as credit card numbers and social security numbers should be encrypted to provide an additional layer of security. You can encrypt data fields in Redshift using the ENCRYPT function. Here's an example of how to encrypt a credit card number field:
Use Strong Encryption Algorithms
Strong encryption algorithms such as AES-256 should be used to provide the strongest protection. Redshift supports AES-256 encryption for data at rest and in transit.
Control Access to Encryption Keys
Access to encryption keys should be restricted to authorized personnel to prevent unauthorized access to sensitive data. You can achieve this by setting up an AWS KMS (Key Management Service) to manage your encryption keys. Here's an example of how to restrict access to an encryption key using KMS in Python:
Regularly Rotate Encryption Keys
Regular rotation of encryption keys ensures that any compromised keys do not provide unauthorized access to sensitive data. You can schedule regular key rotation in AWS KMS by setting a key policy that specifies a rotation schedule. Here's an example of how to schedule annual key rotation in KMS using the AWS CLI:
Turn on logging
To track user access to sensitive data and identify any unwanted access, logging must be enabled. All SQL commands that are executed on your cluster are logged when you activate query logging in Amazon Redshift. This applies to queries that access sensitive data as well as data-scrambling operations. Afterwards, you may examine these logs to look for any strange access patterns or suspect activities.
You may use the following SQL statement to make query logging available in Amazon Redshift:
The stl query system table may be used to retrieve the logs once query logging has been enabled. For instance, the SQL query shown below will display all queries that reached a certain table:
Monitor Performance
Data scrambling is often a resource-intensive practice, so it’s good to monitor CPU usage, memory usage, and disk I/O to ensure your cluster isn’t being overloaded. In Redshift, you can use the <inlineCode>svl_query_summary<inlineCode> and <inlineCode>svl_query_report<inlineCode> system views to monitor query performance. You can also use Amazon CloudWatch to monitor metrics such as CPU usage and disk space.
Establishing Backup and Disaster Recovery
In order to prevent data loss in the case of a disaster, backup and disaster recovery mechanisms should be put in place. Automated backups and manual snapshots are only two of the backup and recovery methods offered by Amazon Redshift. Automatic backups are taken once every eight hours by default.
Moreover, you may always manually take a snapshot of your cluster. In the case of a breakdown or disaster, your cluster may be restored using these backups and snapshots. Use this SQL query to manually take a snapshot of your cluster in Amazon Redshift:
To restore a snapshot, you can use the <inlineCode>RESTORE<inlineCode> command. For example:
Frequent Review and Updates
To ensure that data scrambling procedures remain effective and up-to-date with the latest security requirements, it is crucial to consistently review and update them. This process should include examining backup and recovery procedures, encryption techniques, and access controls.
In Amazon Redshift, you can assess access controls by inspecting all roles and their associated permissions in the <inlineCode>pg_roles<inlineCode> system catalog database. It is essential to confirm that only authorized individuals have access to sensitive information.
To analyze encryption techniques, use the <inlineCode>pg_catalog.pg_attribute<inlineCode> system catalog table, which allows you to inspect data types and encryption settings for each column in your tables. Ensure that sensitive data fields are protected with robust encryption methods, such as AES-256.
The AWS CLI commands <inlineCode>aws backup plan<inlineCode> and <inlineCode>aws backup vault<inlineCode> enable you to review your backup plans and vaults, as well as evaluate backup and recovery procedures. Make sure your backup and recovery procedures are properly configured and up-to-date.
Decrypting Data in Redshift
There are different options for decrypting data, depending on the encryption method used and the tools available; the decryption process is similar to of encryption, usually a custom UDF is used to decrypt the data, let’s look at one example of decrypting data scrambling with a substitution cipher.
Step 1: Create a UDF with decryption logic for substitution
Step 2: Move the data back after truncating and applying the decryption function
In this example, encrypted_column2 is the encrypted version of column2 in the temp_table. The decrypt_substitution function is applied to encrypted_column2, and the result is inserted into the decrypted_column2 in the original_table. Make sure to replace column1, column2, and column3 with the appropriate column names, and adjust the INSERT INTO statement accordingly if you have more or fewer columns in your table.
Conclusion
Redshift data scrambling is an effective tool for additional data protection and should be considered as part of an organization's overall data security strategy. In this blog post, we looked into the importance of data protection and how this can be integrated effectively into the data warehouse. Then, we covered the difference between data scrambling and data masking before diving into how one can set up Redshift data scrambling.
Once you begin to accustom to Redshift data scrambling, you can upgrade your security techniques with different techniques for scrambling data and best practices including encryption practices, logging, and performance monitoring. Organizations may improve their data security posture management (DSPM) and reduce the risk of possible breaches by adhering to these recommendations and using an efficient strategy.
5 Key Findings for Cloud Data Security Professionals from ESG's Survey
5 Key Findings for Cloud Data Security Professionals from ESG's Survey
Securing sensitive cloud data is a key challenge and priority for 2023 and there's increasing evidence that traditional data security approaches are not sufficient. Recently, Enterprise Strategy Group surveyed hundreds of IT, Cloud Security, and DevOps professionals who are responsible for securing sensitive cloud data. The survey had 4 main objectives:
- Determine how public cloud adoption was changing data security priorities
- Explore data loss - particularly sensitive data - from public cloud environments.
- Learn the different approaches organizations are adopting to secure their sensitive cloud data.
- Examine data security spending trends
The 26 page report is full of insights regarding each of these topics. In this blog, we’ll dive into 5 of the most compelling findings and explore what each of them mean for cloud data security leaders.
More Data is Migrating to the Cloud - Even Though Security Teams Aren’t Confident they Can Keep it Secure.
ESG’s findings show that currently 26% of organizations have more than 40% of their company’s data in the cloud. But in 24 months more organizations ( 58%) will have that much of their data in the cloud.
On the one hand, this isn’t surprising. The report notes that digital transformation initiatives combined with the growth of remote/hybrid work environments are pushing this migration. The challenge is that the report also shows that sensitive data is being stored in more than one cloud platform and when it comes to IaaS and PaaS data, more than half admit that a large amount of that data is insufficiently secured. In other words - security isn’t keeping pace with this push to store more and more data in the public cloud.
Cloud Data Loss Affects Nearly 60% of Respondents. Yet They’re Confident They Know Where their Data is
59% of surveyed respondents know they’ve lost sensitive data or suspect they have (with the vast majority saying they lost it more than once). There are naturally many reasons for this, including misconfigurations, misclassifications, and malicious insiders. But at the same time, over 90% said they’re confident in their data discovery and classification abilities. Something doesn’t add up. This gives us a clear indication that existing/defensive security controls are insufficient to deal with cloud data security challenges.
The problem here is likely shadow data. Of course security leaders would secure the sensitive data that they know about. But you can’t secure what you’re unaware of. And with data being constantly moved and duplicated, sensitive assets can be abandoned and forgotten. Solving the data loss problem requires a richer data discovery to provide a meaningful security context. Otherwise, this false sense of security will continue to contribute to sensitive data loss.
Almost All Data Warehouses Have Sensitive Data
Where is this sensitive data being stored? 86% of survey respondents say that they have sensitive data in data lakes or data warehouses. A third of this data is business critical, with almost all the remaining data considered ‘important’ for the business.
Data lakes and warehouses allow data scientists and engineers to leverage their business and customer data to use analytics and machine learning to generate business insights, and have a clear impact on the enterprise. Keeping this growing amount of business critical sensitive data secure is leading to increasing adoption of cloud data security tools.
The Ability to Secure Structured and Unstructured Data is the Most Important Attribute for Data Security Platforms
With 45% of organizations facing a cybersecurity skills shortage, there’s a clear movement towards automation and security platforms to pick up some of the work securing cloud data. With data being stored across different cloud platforms and environments, two thirds of respondents mentioned preferring a single tool for cloud data security.
When choosing a data security platform, the 3 most important attributes were:
- Data type coverage (structured and unstructured data)
- Data location coverage
- Integration with security tools
It’s clear that as organizations plan for a future with increasing amounts of data in the public cloud, we will see a widespread adoption of cloud data security tools that can find and secure data across different environments.
Cloud Data Security has an Address in the Organization - The Cloud Security Architect
Cloud data security has always been a role that was assigned to any number of different team members. Devops, legal, security, and compliance teams all have a role to play. But increasingly, we’re seeing data security become the responsibility chiefly of the cloud security architect.
86% of organizations surveyed now have a cloud security architect role, and 11% more are hiring for this role in the next 12-24 months - and for good reason. Of course, the other teams, including infrastructure and development continue to play a major role. But there is finally some agreement that sensitive data requires its own focus and is best secured by the cloud security architect.
Top 5 GCP Security Tools for Cloud Security Teams in 2024
Top 5 GCP Security Tools for Cloud Security Teams in 2024
Like its primary competitors Amazon Web Services (AWS) and Microsoft Azure, Google Cloud Platform (GCP) is one of the largest public cloud vendors in the world – counting companies like Nintendo, eBay, UPS, The Home Depot, Etsy, PayPal, 20th Century Fox, and Twitter among its enterprise customers.
In addition to its core cloud infrastructure – which spans some 24 data center locations worldwide - GCP offers a suite of cloud computing services covering everything from data management to cost management, from video over the web to AI and machine learning tools. And, of course, GCP offers a full complement of security tools – since, like other cloud vendors, the company operates under a shared security responsibility model, wherein GCP secures the infrastructure, while users need to secure their own cloud resources, workloads and data.
To assist customers in doing so, GCP offers numerous security tools that natively integrate with GCP services. If you are a GCP customer, these are a great starting point for your cloud security journey.
In this post, we’ll explore five important GCP security tools security teams should be familiar with.
Security Command Center
GCP’s Security Command Center is a fully-featured risk and security management platform – offering GCP customers centralized visibility and control, along with the ability to detect threats targeting GCP assets, maintain compliance, and discover misconfigurations or vulnerabilities. It delivers a single pane view of the overall security status of workloads hosted in GCP and offers auto discovery to enable easy onboarding of cloud resources - keeping operational overhead to a minimum. To ensure cyber hygiene, Security Command Center also identifies common attacks like cross-site scripting, vulnerabilities like legacy attack-prone binaries, and more.
Chronicle Detect
GCP Chronicle Detect is a threat detection solution that helps enterprises identify threats at scale. Chronicle Detect’s next generation rules engine operates ‘at the speed of search’ using the YARA detection language, which was specially designed to describe threat behaviors. Chronicle Detect can identify threat patterns - injecting logs from multiple GCP resources, then applying a common data model to a petabyte-scale set of unified data drawn from users, machines and other sources. The utility also uses threat intelligence from VirusTotal to automate risk investigation. The end result is a complete platform to help GCP users better identify risk, prioritize threats faster, and fill in the gaps in their cloud security.
Event Threat Detection
GCP Event Threat Detection is a premium service that monitors organizational cloud-based assets continuously, identifying threats in near-real time. Event Threat Detection works by monitoring the cloud logging stream - API call logs and actions like creating, updating, reading cloud assets, updating metadata, and more. Drawing log data from a wide array of sources that include syslog, SSH logs, cloud administrative activity, VPC flow, data access, firewall rules, cloud NAT, and cloud DNS – the Event Threat Detection utility protects cloud assets from data exfiltration, malware, cryptomining, brute-force SSH, outgoing DDoS and other existing and emerging threats.
Cloud Armor
The Cloud Armor utility protects GCP-hosted websites and apps against denial of service and other cloud-based attacks at Layers 3, 4, and 7. This means it guards cloud assets against the type of organized volumetric DDoS attacks that can bring down workloads. Cloud Armor also offers a web application firewall (WAF) to protect applications deployed behind cloud load balancers – and protects these against pervasive attacks like SQL injection, remote code execution, remote file inclusion, and others. Cloud Armor is an adaptive solution, using machine learning to detect and block Layer 7 DDoS attacks, and allows extension of Layer 7 protection to include hybrid and multi-cloud architectures.
Web Security Scanner
GCP’s Web Security Scanner was designed to identify vulnerabilities in App Engines, Google Kubernetes Engines (GKEs), and Compute Engine web applications. It does this by crawling applications at their public URLs and IPs that aren't behind a firewall, following all links and exercising as many event handlers and user inputs as it can. Web Security Scanner protects against known vulnerabilities like plain-text password transmission, Flash injection, mixed content, and also identifies weak links in the management of the application lifecycle like exposed Git/SVN repositories. To monitor web applications for compliance control violations, Web Security Scanner also identifies a subset of the critical web application vulnerabilities listed in the OWASP Top Ten Project.
Securing the cloud ecosystem is an ongoing challenge, partly because traditional security solutions are ineffective in the cloud – if they can even be deployed at all. That’s why the built-in security controls in GCP and other cloud platforms are so important.
The solutions above, and many others baked-in to GCP, help GCP customers properly configure and secure their cloud environments - addressing the ever-expanding cloud threat landscape.
Top 6 Azure Security Tools, Features, and Best Practices
Top 6 Azure Security Tools, Features, and Best Practices
Nowadays, it is evident that the rapid growth of cloud computing has changed how organizations operate. Many organizations increasingly rely on the cloud to drive their daily business operations. The cloud is a single place for storing, processing and accessing data; it’s no wonder that people are becoming addicted to its convenience.
However, as the dependence on cloud service providers continues, the need for security also increases. One needs to measure and safeguard sensitive data to protect against possible threats. Remember that security is a shared responsibility - even if your cloud provider secures your data, the security will not be absolute. Thus, understanding the security features of a particular cloud service provider becomes significant.
Introduction to Microsoft Azure Security Services
Microsoft Azure offers services and tools for businesses to manage their applications and infrastructure. Utilizing Azure ensures robust security measures are in place to protect sensitive data, maintain privacy, and mitigate potential threats.
This article will tackle Azure’s security features and tools to help organizations and individuals safeguard and protect their data while they continue their innovation and growth.
There’s a collective set of security features, services, tools, and best practices offered by Microsoft to protect cloud resources. In this section, let's explore some layers to gain some insights.
The Layers of Security in Microsoft Azure:
Let’s explore some features and tools, and discuss their key features and best practices.
Azure Active Directory Identity Protection
Identity protection is a cloud-based service for the Azure AD suite. It focuses on helping organizations protect their user identities and detect potential security risks. Moreover, it uses advanced machine learning algorithms and security signals from various sources to provide proactive and adaptive security measures. Furthermore, leveraging machine learning and data analytics can identify risky sign-ins, compromised credentials, and malicious or suspicious user behavior. How’s that? Sounds great, right?
Key Features
1. Risk-Based User Sign-In Policies
It allows organizations to define risk-based policies for user sign-ins which evaluate user behavior, sign-in patterns, and device information to assess the risk level associated with each sign-in attempt. Using the risk assessment, organizations can enforce additional security measures, such as requiring multi-factor authentication (MFA), blocking sign-ins, or prompting password resets.
2. Risky User Detection and Remediation
The service detects and alerts organizations about potentially compromised or risky user accounts. It analyzes various signals, such as leaked credentials or suspicious sign-in activities, to identify anomalies and indicators of compromise. Administrators can receive real-time alerts and take immediate action, such as resetting passwords or blocking access, to mitigate the risk and protect user accounts.
Best Practices
- Educate Users About Identity Protection - Educating users is crucial for maintaining a secure environment. Most large organizations now provide security training to increase the awareness of users. Training and awareness help users protect their identities, recognize phishing attempts, and follow security best practices.
- Regularly Review and Refine Policies - Regularly assessing policies helps ensure their effectiveness, which is why it is good to continuously improve the organization’s Azure AD Identity Protection policies based on the changing threat landscape and your organization's evolving security requirements.
Azure Firewall
Microsoft offers an Azure Firewall, which is a cloud-based network security service. It acts as a barrier between your Azure virtual networks and the internet. Moreover, it provides centralized network security and protection against unauthorized access and threats. Furthermore, it operates at the network and application layers, allowing you to define and enforce granular access control policies.
Thus, it enables organizations to control inbound and outbound traffic for virtual and on-premises networks connected through Azure VPN or ExpressRoute. Of course, we can’t ignore the filtering traffic of source and destination IP addresses, ports, protocols, and even fully qualified domain names (FQDNs).
Key Features
1. Network and Application-Level Filtering
This feature allows organizations to define rules based on IP addresses (source and destination), including ports, protocols, and FQDNs. Moreover, it helps organizations filter network and application-level traffic, controlling inbound and outbound connections.
2. Fully Stateful Firewall
Azure Firewall is a stateful firewall, which means it can intelligently allow return traffic for established connections without requiring additional rules. The beneficial aspect of this is it simplifies rule management and ensures that legitimate traffic flows smoothly.
3. High Availability and Scalability
Azure Firewall is highly available and scalable. It can automatically scale with your network traffic demand increases and provides built-in availability through multiple availability zones.
Best Practices
- Design an Appropriate Network Architecture - Plan your virtual network architecture carefully to ensure proper placement of Azure Firewall. Consider network segmentation, subnet placement, and routing requirements to enforce security policies and control traffic flow effectively.
- Implement Network Traffic Filtering Rules - Define granular network traffic filtering rules based on your specific security requirements. Start with a default-deny approach and allow only necessary traffic. Regularly review and update firewall rules to maintain an up-to-date and effective security posture.
- Use Application Rules for Fine-Grain Control - Leverage Azure Firewall's application rules to allow or deny traffic based on specific application protocols or ports. By doing this, organizations can enforce granular access control to applications within their network.
Azure Resource Locks
Azure Resource Locks is a Microsoft Azure feature that allows you to restrict Azure resources to prevent accidental deletion or modification. It provides an additional layer of control and governance over your Azure resources, helping mitigate the risk of critical changes or deletions.
Key Features
Two types of locks can be applied:
1. Read-Only (CanNotDelete)
This lock type allows you to mark a resource as read-only, meaning modifications or deletions are prohibited.
2. CanNotDelete (Delete)
This lock type provides the highest level of protection by preventing both modifications and deletions of a resource; it ensures that the resource remains completely unaltered.
Best Practices
- Establish a Clear Governance Policy - Develop a governance policy that outlines the use of Resource Locks within your organization. The policy should define who has the authority to apply or remove locks and when to use locks, and any exceptions or special considerations.
- Leverage Azure Policy for Lock Enforcement - Use Azure Policy alongside Resource Locks to enforce compliance with your governance policies. It is because Azure Policy can automatically apply locks to resources based on predefined rules, reducing the risk of misconfigurations.
Azure Secure SQL Database Always Encrypted
Azure Secure SQL Database Always Encrypted is a feature of Microsoft Azure SQL Database that provides another security-specific layer for sensitive data. Moreover, it protects data at rest and in transit, ensuring that even database administrators or other privileged users cannot access the plaintext values of the encrypted data.
Key Features
1. Client-Side Encryption
Always Encrypted enables client applications to encrypt sensitive data before sending it to the database. As a result, the data remains encrypted throughout its lifecycle and can be decrypted only by an authorized client application.
2. Column-Level Encryption
Always Encrypted allows you to selectively encrypt individual columns in a database table rather than encrypting the entire database. It gives organizations fine-grained control over which data needs encryption, allowing you to balance security and performance requirements.
3. Transparent Data Encryption
The database server stores the encrypted data using a unique encryption format, ensuring the data remains protected even if the database is compromised. The server is unaware of the data values and cannot decrypt them.
Best Practices
The organization needs to plan and manage encryption keys carefully. This is because encryption keys are at the heart of Always Encrypted. Consider the following best practices.
- Use a Secure and Centralized Key Management System - Store encryption keys in a safe and centralized location, separate from the database. Azure Key Vault is a recommended option for managing keys securely.
- Implement Key Rotation and Backup - Regularly rotate encryption keys to mitigate the risks of key compromise. Moreover, establish a key backup strategy to recover encrypted data due to a lost or inaccessible key.
- Control Access to Encryption Keys - Ensure that only authorized individuals or applications have access to the encryption keys. Applying the principle of least privilege and robust access control will prevent unauthorized access to keys.
Azure Key Vault
Azure Key Vault is a cloud service provided by Microsoft Azure that helps safeguard cryptographic keys, secrets, and sensitive information. It is a centralized storage and management system for keys, certificates, passwords, connection strings, and other confidential information required by applications and services. It allows developers and administrators to securely store and tightly control access to their application secrets without exposing them directly in their code or configuration files.
Key Features
1. Key Management
Key Vault provides a secure key management system that allows you to create, import, and manage cryptographic keys for encryption, decryption, signing, and verification.
2. Secret Management
It enables you to securely store (as plain text or encrypted value) and manage secrets such as passwords, API keys, connection strings, and other sensitive information.
3. Certificate Management
Key Vault supports the storage and management of X.509 certificates, allowing you to securely store, manage, and retrieve credentials for application use.
4. Access Control
Key Vault provides fine-grained access control to manage who can perform operations on stored keys and secrets. It integrates with Azure Active Directory (Azure AD) for authentication and authorization.
Best Practices
- Centralized Secrets Management - Consolidate all your application secrets and sensitive information in Key Vault rather than scattering them across different systems or configurations. The benefit of this is it simplifies management and reduces the risk of accidental exposure.
- Use RBAC and Access Policies - Implement role-based access control (RBAC) and define granular access policies to power who can perform operations on Key Vault resources. Follow the principle of least privilege, granting only the necessary permissions to users or applications.
- Secure Key Vault Access - Restrict access to Key Vault resources to trusted networks or virtual networks using virtual network service or private endpoints because it helps prevent unauthorized access to the internet.
Azure AD Multi-Factor Authentication
It is a security feature provided by Microsoft Azure that adds an extra layer of protection to user sign-ins and helps safeguard against unauthorized access to resources. Users must give additional authentication factors beyond just a username and password.
Key Features
1. Multiple Authentication Methods
Azure AD MFA supports a range of authentication methods, including phone calls, text messages (SMS), mobile app notifications, mobile app verification codes, email, and third-party authentication apps. This flexibility allows organizations to choose the methods that best suit their users' needs and security requirements.
2. Conditional Access Policies
Azure AD MFA can configure conditional access policies, allowing organizations to define specific conditions under which MFA (is required), once applied to an organization, on the user location, device trust, application sensitivity, and risk level. This granular control helps organizations strike a balance between security and user convenience.
Best Practices
- Enable MFA for All Users - Implement a company-wide policy to enforce MFA for all users, regardless of their roles or privileges, because it will ensure consistent and comprehensive security across the organization.
- Use Risk-Based Policies - Leverage Azure AD Identity Protection and its risk-based policies to dynamically adjust the level of authentication required based on the perceived risk of each sign-in attempt because it will help balance security and user experience by applying MFA only when necessary.
- Implement Multi-Factor Authentication for Privileged Accounts - Ensure that all privileged accounts, such as administrators and IT staff, are protected with MFA. These accounts have elevated access rights and are prime targets for attackers. Enforcing MFA adds an extra layer of protection to prevent unauthorized access.
Conclusion
In this post, we have introduced the importance of cybersecurity in the cloud space due to dependence on cloud providers. After that we discussed some layers of security in Azure to gain insights about its landscape and see some tools and features available. Of course we can’t ignore the features such as Azure Active Directory Identity Protection, Azure Firewall, Azure Resource Locks, Azure Secure SQL Database Always Encrypted, Azure Key Vault and Azure AD Multi-Factor Authentication by giving an overview on each, its key features and the best practices we can apply to our organization.
Top 8 AWS Cloud Security Tools and Features for 2024
Top 8 AWS Cloud Security Tools and Features for 2024
AWS – like other major cloud providers – has a ‘shared responsibility’ security model for its customers. This means that AWS takes full responsibility for the security of its platform – but customers are ultimately responsible for the security of the applications and datasets they host on the platform.
This doesn’t mean, however, that AWS washes its hands of customer security concerns. Far from it. To support customers in meeting their mission critical cloud security requirements, AWS has developed a portfolio of cloud security tools and features that help keep AWS applications and accounts secure. Some are offered free, some on a subscription basis. Below, we’ve compiled some key points about the top eight of these tools and features:
1. Amazon GuarDuty
Amazon’s GuardDuty threat detection service analyzes your network activity, API calls, workloads, and data access patterns across all your AWS accounts. It uses AI to check and analyze multiple sources – from Amazon CloudTrail event logs, DNS logs, Amazon VPC Flow Logs, and more. GuardDuty looks for anomalies that could indicate infiltration, credentials theft, API calls from malicious IPs, unauthorized data access, cryptocurrency mining, and other serious cyberthreats. The subscription-based tool also draws updated threat intel from feeds like Proofpoint and Crowdstrike, to ensure workloads are fully protected from emerging threats.
2. AWS CloudTrail
Identity is an increasingly serious attack surface in the cloud. And this makes visibility over AWS user account activity crucial to maintaining uptime and even business continuity. AWS CloudTrail enables you to monitor and record account activity - fully controlling storage, analysis and remediation - across all your AWS accounts. In addition to improving overall security posture through recording user activity and events, CloudTrail offers important audit functionality for proof of compliance with emerging and existing regulatory regimes like HIPAA, SOC and PCI. CloudTrail is an invaluable addition to any AWS security war chest, empowering admins to capture and monitor API usage and user activity across all AWS regions and accounts.
3. AWS Web Application Firewall
Web applications are attractive targets for threat actors, who can easily exploit known web layer vulnerabilities to gain entry to your network. AWS Web Application Firewall (WAF) guards web applications and APIs from bots and web exploits that can compromise security and availability, or unnecessarily consume valuable processing resources. AWS WAF addresses these threats by enabling control over which traffic reaches applications, and how it reaches them. The tool lets you create fully-customizable security rules to block known attack patterns like cross-site scripting and SQL injection. It also helps you control traffic from automated bots, which can cause downtime or throw off metrics owing to excessive resource consumption.
4. AWS Shield
Distributed Denial of Service (DDoS) attacks continue to plague companies, organizations, governments, and even individuals. AWS Shield is the platform’s built-in DDoS protection service. Shield ensures the safety of AWS-based web applications – minimizing both downtime and latency. Happily, the standard tier of this particular AWS service is free of charge and protects against most common transport and network layer DDoS attacks. The advanced version of AWS Shield, which does carry an additional cost, adds resource-specific detection and mitigation techniques to the mix - protecting against large-scale DDoS attacks that target Amazon ELB instances, AWS Global Accelerator, Amazon CloudFront, Amazon Route 53, and EC2 instances.
5. AWS Inspector
With the rise in adoption of cloud hosting for storage and computing, it’s crucial for organizations to protect themselves from attacks exploiting cloud vulnerabilities. A recent study found that the average cost of recovery from a breach caused by cloud security vulnerabilities was nearly $5 million. Amazon Inspector enables automated vulnerability management for AWS workloads. It automatically scans for software vulnerabilities, as well as network vulnerabilities like remote root login access, exposed EC2 instances, and unsecured ports – all of which could be exploited by threat actors. What’s more, Inspector’s integral rules package is kept up to date with both compliance standards and AWS best practices.
6. Amazon Macie
Supporting Amazon Simple Storage Service (S3), Amazon’s Macie data privacy and security service leverages pattern matching and machine learning to discover and protect sensitive data. Recognizing PII or PHI (Protected Health Information) in S3 buckets, Macie is also able to monitor the access and security of the buckets themselves. Macie makes compliance with regulations like HIPAA and GDPR simpler, since it clarifies what data there is in S3 buckets and exactly how that data is shared and stored publicly and privately.
7. AWS Identity and Access Management
AWS Identity and Access Management (IAM) enables secure management of identities and access to AWS services and resources. IAM works on the principle of least privilege – meaning that each user should only be able to access information and resources necessary for their role. But achieving least privilege is a constantly-evolving process – which is why IAM works continuously to ensure that fine-grained permissions change as your needs change. IAM also allows AWS customers to manage identities per-account or offer multi-account access and application assignments across AWS accounts. Essentially, IAM streamlines AWS streamlines permissions management – helping you set, verify, and refine policies toward achieving least privilege.
8. AWS Secrets Manager
AWS aptly calls their secrets management service Secrets Manager. It’s designed to help protect access to IT resources, services and applications – enabling simpler rotation, management and retrieval of API keys, database credentials and other secrets at any point in the secret lifecycle. And Secrets Manager allows access control based on AWS Identity and Access Management (IAM) and resource-based policies. This means you can leverage the least privilege policies you defined in IAM to help control access to secrets, too. Finally, Secrets Manager handles replication of secrets – facilitating both disaster recovery and work across multiple regions.
There are many more important utilities we couldn’t cover in this blog, including AWS Audit Manager, which are equally important in their own rights. Yet the key takeaway is this: even though AWS customers are responsible for their own data security, AWS makes a real effort to help meet and exceed security standards and expectations.
Sentra Arrives in the US, Announces New Technology Partnership with Wiz
Sentra Arrives in the US, Announces New Technology Partnership with Wiz
We're excited to announce that Sentra has opened its new North American headquarters in New York City!
Sentra now has teams operating out of both the East and West coasts in the US, along with their co-HQ in Tel Aviv.
We're also announcing a new technology partnership with Wiz, a Cloud Security Posture Management solution that just became the fast company trusted by over 20% of Fortune 500 companies.
“Sentra’s technology provides enterprises with a powerful understanding of their data,” says Assaf Rappaport, CEO of Wiz. “Together, our solutions effectively eliminate data risks and secure everything an enterprise builds and runs in the cloud. This is a true technology partnership between two organizations with industry-leading technology.”
These announcements come on the heels of our being recognized by Gartner as a Sample Vendor for Data Security Posture Management in the Hype Cycle™ report for Data Security 2022.
The reason for the growth of the Data Security Posture Management category and its popularity with Sentra's customers is clear.
Sentra CEO Yoav Regev explains that "while the data attack surface might be a relatively new concept, it’s based on principles security teams are well aware of — increasing visibility and limiting exposure. When it comes to the cloud, the most effective way to accomplish this is by controlling where sensitive data is stored and making sure that data is always traveling to secure locations. Simply put, as data travels, so should security.”
Sentra's agentless solution easily integrates into a customer’s infrastructure. Sentra's international growth comes as the solution gains traction with enterprises plagued by data overload due to its ease of use and ability to achieve rapid results.
“Sentra’s value was immediate. It enables us to map critical sensitive data faster and secure it,” said Gal Vitenberg, application security architect at Global-e, a NASDAQ-listed e-commerce company. “As an organization that prioritizes the security of data in the cloud, using Sentra enables our teams to operate quickly while maintaining our high levels of security requirements.”
A proud member of the Cloud Security Alliance, you can learn more about Sentra's Data Security Posture Management solution.
GARTNER and HYPE CYCLE are registered trademarks and service marks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved. Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s Research & Advisory organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
Access Controls that Move - The Power of Data Security Posture Management
Access Controls that Move - The Power of Data Security Posture Management
Controlling access to data has always been one of the basics of cybersecurity hygiene. Managing this access has evolved from basic access control lists, to an entire Identity and Access Management industry. IAM controls are great at managing access to applications, infrastructure and on-prem data. But cloud data is a trickier issue. Data in the cloud changes environments and is frequently copied, moved, and edited.
This is where data access tools share the same weakness- what happens when the data moves? (Spoiler - the policy doesn’t follow).
The Different Access Management Models
There are 3 basic types of access controls enterprises use to control who can read and edit their data.
Access Control Lists: Basic lists of which users have read/write access.
Role Based Access Control (RBAC): The administrator defines access by what roles the user has - for example, anyone with the role ‘administrator’ is granted access.
Attribute Based Access Control (ABAC): The administrator defines which attributes a user must have to access an object - for example, only users with the job title ‘engineer’ and only those accessing the data from a certain location will be granted access. These policies are usually defined in XACML which stands for "eXtensible Access Control Markup Language’.
How Access Controls are Managed in the Cloud
The major public cloud providers include a number of access control features.
AWS for example, has long included clear instructions on managing access to consoles and S3 buckets. In RDS, users can tag and categorize resources and then build access policies based on those tags.
Similar controls exist in Azure: Azure RBAC allows owners and administrators to create RBAC roles and currently Azure ABAC is in preview mode, and will allow for fine grained access control in Azure environment.
Another aspect of access management in the cloud is ‘assumed roles’ in which a user is given access to a resource they aren’t usually permitted to access via a temporary key. This permission is meant to be temporary and permit cross account access as needed. Learn more about Azure security in our comprehensive guide.
The Problem: Access Controls Don't Follow the Data
So what’s missing? When data access controls are put in place in the cloud, they’re tied to the data store or database that the controls were created for. Imagine the following scenario. An administrator knows that a specific S3 bucket has sensitive data in it. Being a responsible cloud admin, they set up RBAC or ABAC policies and ensure only the right users have permissions at the right times. So far so good.
But now someone comes along and needs some of the data in that bucket. Maybe just a few details from a CSV file. They copy/paste the data somewhere else in your AWS environment.
Now what happens to that RBAC or ABAC policy? It doesn’t apply to the copied data - not only does the data not have the proper access controls set, but even if you’re able to find the exposed sensitive data, it’s not clear where it came from, or how it’s meant to be protected.
How Sentra’s DSPM Ensures that Data Always Has the Proper Access Controls
What we need is a way for the access control policy to travel with the data throughout the public cloud. This is one of the most difficult problems that Data Security Posture Management (DSPM) was created to tackle.
DSPM is an approach to cloud security that focuses on finding and securing sensitive data, as opposed to the cloud infrastructure or applications. It accomplishes this by first discovering sensitive data (including shadow or abandoned data). DSPM classifies the data types using AI models and then determines whether the data has the proper security posture and how best to remediate if it doesn’t.
While data discovery and classification are important, they’re not actionable without understanding:
- Where the data came from
- Who originally had access to the data
- Who has access to the data now
The divide between what a user currently has access to vs what they should have access to, is referred to as the ‘authorization gap’.
Sentra’s DSPM solution is able to understand who has access to the data and close this gap through the following processes:
- Detecting unused privileges and adjusting for least privileged access based on user behavior: For example ,if a user has access to 10 data stores but only accesses 2 of them, Sentra will notice and suggest removing access from the other 8.
- Detecting user groups with excessive access to data. For example, if a user in the finance team has access to the developer environment, Sentra will raise a flag to remove the over privileged user.
- Detecting overprivileged similar data: For example, if sensitive data in production is only accessible by 2 users, but 85% of the data exists somewhere where more people have access, Sentra will alert the data owners to remediate.
Access control and authorization remains one of the most important ways of securing sensitive cloud data. A data centric security solution can help ensure that the right access controls always follow your cloud data.
How Sensitive Cloud Data Gets Exposed
How Sensitive Cloud Data Gets Exposed
When organizations began migrating to the cloud, they did so with the promise that they’ll be able to build and adapt their infrastructures at speeds that would give them a competitive advantage. It also meant that they’d be able to use large amounts of data to gather insights about their users and customers to better understand their needs.
While this is all true - it does mean that there’s more data than ever that security teams are responsible for protecting more data than ever before. As data gets replicated, shared, and moved throughout the public cloud, sensitive data exposure becomes more common. These are the most common ways that sensitive cloud data is exposed and leaked - and what’s needed to mitigate the risks.
Causes of Cloud Data Exposure
Negligence: Accidentally leaving a data asset exposed to the internet shouldn’t happen. Cloud providers know it happens anyway - AWS’ first sentence in their best practices for S3 storage article says “Ensure that your Amazon S3 buckets use the correct policies and are not publicly accessible.” 5 years ago AWS added warnings to dashboards when a bucket was publicly exposed. Of course, S3 is just one of many data stores that contain sensitive data and are prone to accidental exposure. Despite the warnings, exposed data assets continue to be a cause of data breaches. Fortunately, these vulnerabilities are easily corrected- assuming you have perfect visibility into your cloud environment.
Data Movement: Even when sensitive data is properly secured, there’s always a risk that it could be moved or copied into an unsecured environment. A common example of this is taking sensitive data from a secured production environment and moving it to a developer environment with a lower security posture. In this case, the data’s owner did everything right - it was the second user who moved the data who accidentally put it at risk. Another example would be an organization which has a PCI environment where they keep all the payment information of their customers, and they need to prevent this extremely sensitive data from going to other data stores in less secured parts of their cloud environment.
Improper Access Management: Access to sensitive data should not be granted to users who don’t need it (see the example above). Improper IAM configurations and access control management increases the risk of accidental or malicious data leakage. More access means more potential shadow data being created and abandoned. For example, a user might copy sensitive data and then leave the company, creating data that no one is aware of. Limiting access to sensitive data to users who actually need it can help prevent a needless expansion of your organization’s ‘data attack surface’.
3rd Parties: It’s extremely easy to accidentally share sensitive data with a third party over email. Accidentally forwarding sensitive data or credentials is one of the simplest ways to leak sensitive data from your organization. In the public cloud, the equivalent of the accidental email is granting a 3rd party access to a data asset in your public cloud infrastructure, such as a CI/CD tool or a SaaS application for data analytics. It’s similar to improper access management, only now the over privileged access is granted outside of your organization entirely where you’re less able to mitigate the risks.
Another common way data is leaked to 3rd parties is when someone inside an organization shares something that isn't supposed to have sensitive data, but does. A good example of this is sharing log files with a 3rd party. Log files shouldn’t have sensitive data, but often it can include data like user emails, IP addresses, API credentials, etc.
ETL Errors: When extracting data that contains PII from one from a production database to a data lake or an analytics data warehouse, such as Redshift or Snowflake, sometimes the wrong warehouse might be specified. This is an easy mistake to miss, as data agnostic tools might not understand the sensitive nature of the data.
Why Can’t Cloud Data Security Solutions Stop Sensitive Data Exposure?
Simply put - they’re not looking at the data. They’re looking at the network, infrastructure, and perimeter. That’s how data leaks used to be prevented in the on-prem days - you’d just make sure the perimeter was secure, and because all your sensitive data was on-prem, you could secure it by securing everything.
For cloud-first companies, data isn’t staying behind the corporate perimeter. And while cloud platforms can identify infrastructure vulnerabilities, they’re missing the context around which data is sensitive. Remediating data vulnerabilities - finding sensitive data with an improper security posture remains a challenge.
Discovering and Classifying Cloud Data - The Data Security Posture Management (DSPM) Approach
Instead of trying to adapt on-prem strategies to cloud environments, DSPM (a new ‘on the rise’ category in Gartner’s™ latest hype cycle) takes a data first approach. By understanding the data’s proper context, DSPM secure sensitive cloud data by:
- Discovering all cloud data, including shadow data and abandoned data stores
- Classifying the different data types using standard and custom parameters
- Automatically detects when sensitive data’s security posture is changed - whether via data movement or duplication
- Detects who can access and who has accessed sensitive data
- Understands how data travels throughout the cloud environment
- Orchestrates remediation workflows between engineering and security teams
Data Security Posture Management solves many of the most common reasons sensitive cloud data gets leaked. By focusing on securing and following the data across the cloud, DSPM helps cloud security teams finally secure what we’re all supposed to be protecting - sensitive data.
To learn more about Data Security Posture Management, check out our full introduction to DSPM, or see it for yourself.
Types of Sensitive Data: What Cloud Security Teams Should Know
Types of Sensitive Data: What Cloud Security Teams Should Know
Not all data is created equal. If there’s a breach of your public cloud, but all the hackers access is company photos from your last happy hour… well, no one really cares. It’s not making headlines. On the other hand if they leak a file which contains the payment and personal details of your customers, that’s (rightfully) a bigger deal.
This distinction means that it’s critical for data security teams to understand the types of data that they should be securing first. This blog will explain the most common types of sensitive data organizations maintain, and why they need to be secured and monitored as they move throughout your cloud environment.
Types of Sensitive Cloud Data
Personal Identifiable Information (PII): National Institute of Standards and Practices defines PII as:
(1) any information that can be used to distinguish or trace an individual‘s identity, such as name, social security number, date and place of birth, mother‘s maiden name, or biometric records; and (2) any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information.
User and customer data has become an increasingly valuable asset for businesses, and the amount of PII - especially in the cloud- has increased dramatically in only the past few years.
The value and amount of PII means that it is frequently the type of data that is exposed in the most famous data leaks. This includes the 2013 Yahoo! breach, which affected 3 billion records, and the 2017 Equifax breach.
Payment Card Industry (PCI): PCI data includes credit card information and payment details. The Payment Card Industry Security Standards Council created PCI-DSS (Data Security Standard) as a way to standardize how credit cards can be securely processed. To become PCI-DSS compliant, an organization must follow certain security practices with the aim of achieving 6 goals:
- Build and maintain a secure network
- Protect cardholder data
- Maintain a vulnerability management program
- Implement strong access control measures
- Regularly monitor networks
- Maintain an information security policy
Protected Health Information (PHI): In the United States, PHI regulations are defined by the Health Insurance Portability and Accountability Act (HIPAA). This data includes any past and future data about an identifiable individual’s health, treatment, and insurance information. The guidelines for protecting PHI are periodically updated by the US Department of Health and Human Services (HHS) but on a technological level, there is no one ‘magic bullet’ that can guarantee compliance. Compliant companies and healthcare providers will layer different defenses to ensure patient data remains secure. By law, HHS maintains a portal where breaches affecting 500 or more patient records are listed and updated.
Intellectual Property: While every company should consider user and employee data sensitive, what qualifies as a sensitive IP varies from organization to organization. For SaaS companies this could be source code of all customer-facing services or customer base trends. Identifying the most valuable data to your enterprise, securing it, and maintaining that security posture should be a priority for all security teams, regardless of the size of the company or where the data is stored.
Developer Secrets: For software companies, developer secrets such as passwords and API keys can be accidentally left in source code or in the wild. Often these developer secrets are unintentionally copied and stored in lower environments, data lakes, or unused block storage volumes.
The Challenge of Protecting Sensitive Cloud Data
When all sensitive data was stored on-prem, data security basically meant preventing unauthorized access to the company’s data center. Access could be requested, but the data wasn’t actually going anywhere. Of course, the adoption of cloud apps and infrastructures means this is no longer the case. Engineers and data teams need access to data to do their jobs, which often leads to moving, duplicating, or changing sensitive data assets. This growth of the ‘data attack surface’ leads to more sensitive data being exposed/leaked, which leads to more breaches. Breaking this cycle will require a new method of protecting these sensitive data classes.
Cloud Data Security with Data Security Posture Management
Data Security Posture Management (DSPM) was created for this new challenge. Recently recognized by Gartner® as an ‘On the Rise’ category, DSPMs find all cloud data, classify it by sensitivity, and then offer actionable remediation plans for data security teams. By taking a data centric approach to security, DSPMs are able to secure what matters to the business first - their data.
To learn more about Sentra’s DSPM solution, you can request a demo here.
Data Context is the Missing Ingredient for Security Teams
Data Context is the Missing Ingredient for Security Teams
Why are we still struggling with remediation and alert fatigue? In every cybersecurity domain, as we get better at identifying vulnerabilities, and add new automation tools, security teams still face the same challenge - what do we remediate first? What poses the greatest risk to the business?
Of course, the capabilities of cyber solutions have grown. We have more information about breaches and potential risk than ever. If in the past, an EDR could tell you which endpoint has been compromised, today an XDR can tell you which servers and applications have been compromised. It’s a deeper level of analysis. But prioritizing what to focus on first is still a challenge. You might have more information, but it’s not always clear what the biggest risk to the business is.
The same can be said for SIEMs and SOAR solutions. If in the past we received alerts and made decisions based on log and event data from the SIEM, now we can factor in threat intelligence and third party sources to better understand compromises and vulnerabilities. But again, when it comes to what to remediate to best protect your specific business these tools aren’t able to prioritize.
The deeper level of analysis we’ve been conducting for the last 5-10 years is still missing what’s needed to make effective remediation recommendations - context about the data at risk. We get all these alerts, and while we might know which endpoints and applications are affected, we’re blind when it comes to the data. That ‘severe’ endpoint vulnerability your team is frantically patching? It might not contain any sensitive data that could affect the business. Meanwhile, the reverse might be true - that less severe vulnerability at the bottom of your to-do list might affect data stores with customer info or source code.

AWS CISO Stephen Schmidt, showing data as the core layer of defense at this years AWS Reinforce
This is the answer to the question ‘why is prioritization still a problem?” - the data. We can’t really prioritize anything properly until we know what data we’re defending. After all, the whole point of exploiting a vulnerability is usually to get to the data.
Now let’s imagine a different scenario. Instead of getting your usual alerts and then trying to prioritize, you get messages that read like this:
‘Severe Data Vulnerability: Company source code has been found in the following unsecured data store:____. This vulnerability can be remediated by taking the following steps: ___’.
You get the context of what’s at-risk, why it’s important, and how to remediate it. That’s data centric security.
Why Data Centric Security is Crucial for Cloud First Companies
Data centric security wasn’t always critical. When everything was stored on the corporate data center, it was enough to just defend the perimeter, and you knew the data was protected. You also knew where all your data was - literally in the room next door. Sure, there were risks around information kept on local devices, but there wasn’t a concern that someone would accidentally save 100 GB of information to their device.
The cloud and data democratization changed all that. Now, besides not having a traditional perimeter, there’s the added issue of data sprawl. Data is moved, duplicated, and changed at previously unimaginable scales. And even when data is secured properly, with the proper security posture, that security posture doesn’t come with when the data is moved. Legacy security tools built for the on-prem era can’t provide the level of security context needed by organizations with petabytes of cloud data.
Data Security Posture Management
This data context is the promise of data security posture management solutions. Recently recognized in Gartner’s Hype Cycle for Data Security Report as an ‘On the Rise’ category, DSPM gets to the core of the context issue. DSPM solutions attack the problem by first identifying all data an organization has in the cloud. This step often leads to the discovery of data stores that security teams didn’t even know existed. Following this, the next stage is classification, where the types of data labeled - this could be PII, PCI, company secrets, source code, etc. Any sensitive data found to have an insufficient security posture is passed to the relevant teams for remediation. Finally, the cloud environment must be continuously assessed for future data vulnerabilities which are again forwarded to the relevant teams with remediation suggestions in real time.
In a clear example of the benefits offered by DSPM, Sentra has identified source code in open S3 buckets of a major ecommerce company. By leveraging machine learning and smart metadata scanning, Sentra quickly identified the valuable nature of the exposed asset and ensured it was quickly remediated.
If you’re interested in learning more about DSPM or Sentra specifically, request a demo here.
Cloud Data Security Means Shrinking the “Data Attack Surface”
Cloud Data Security Means Shrinking the “Data Attack Surface”
Traditionally, the attack surface was just the sum of the different attack vectors that your IT was exposed to. The idea being as you removed vectors through patching and internal audits.
With the adoption of cloud technologies, the way we managed the attack surface changed. As the attack vendors changed, new tools were developed to find security vulnerabilities and misconfigurations. However, the principle remained similar - prevent attackers from accessing your cloud infrastructure and platform by eliminating and remediating attack vectors. But attackers will find their way - it’s only a matter of "when".
Data attack surface is a new concept. When data was all in one location (the enterprise’s on- data center), this wasn’t something we needed to consider. Everything was in the data center, so defending the perimeter was the same thing as protecting the data. But what makes cloud data security vulnerable isn’t primarily technical vulnerabilities into the cloud environment. It’s the fact that there’s so much data to defend and it's not clear where all that data is, who is responsible for it, and what its security posture is supposed to be. The sum of the total vulnerable, sensitive, and shadow data assets is the data attack surface.
Reducing the Data Attack Surface
Traditional attack surface reduction is accomplished by visualizing your enterprise’s architecture and finding unmanaged devices. This first step in data attack surface reduction is similar - except it's about mapping your cloud data. Only following a successful cloud data discovery program can you understand the scope of the project.
The second step of traditional attack surface reduction is finding vulnerabilities and indicators of exposures. This is similarly adaptable to the data attack surface. By classifying the data both by sensitivity (company secrets, compliance) and by security posture (how should this data be secured) cloud security teams can identify their level of exposure.
The final step shrinking the attack surface involves remediating the data vulnerability. This can involve deleting an exposed, unused data store or ensuring that sensitive data has the right level of encryption. The idea should always be not to have more sensitive data than you need, and that data should always have the proper security posture.
3 Ways Reducing the Data Attack Surface Matters to the Business
- Reduce the likelihood of data breaches. Just like shrinking your traditional attack surfaces reduces the risk of a vulnerability being exploited, shrinking the data attack surface reduces the risk of a data breach. This is achieved by eliminating sensitive shadow data, which has the dual benefit of reducing both the overall amount of company data, and the amount of exposed sensitive data. With less data to defend, it’s easier to prioritize securing the most critical data to your business, reducing the risk of a breach.
- Stay compliant with data localization regulations. We’re seeing an increase in the number of data localization rules - data generated and stored in one country or region isn’t allowed to be transferred outside of that area. This can cause some obvious problems for cloud-first enterprises, as they may be using data centers all over the world. Orphaned or shadow data can be non-compliant with local laws, but because no one knows they exist, they pose a real compliance risk if discovered.
- Reducing overall security costs. The smaller your data attack surface is, the less time and money you need to spend defending it. There are cloud costs for scanning and monitoring your environment and there’s of course the time and human resources you need to dedicate to scanning, remediating, and managing the security posture of your cloud data. Shrinking the data attack surface means less to manage.
How Data Security Posture Management (DSPM) Tools Help Reduce the Data Attack Surface
Data Security Posture Management (DSPM) shrinks the attack surface by discovering all of your cloud data, classifying it by sensitivity to the business, and then offering plans to remediate all data vulnerabilities found. Often, shadow cloud data can be eliminated entirely, allowing security teams to focus on a smaller amount of data stores and databases. Additionally, by classifying data according to business impact, a DSPM tool ensures cloud security teams are focused on the most critical data - whether that’s company secrets, customer data, or sensitive employee data. Finally, remediation plans ensure that security teams aren’t just monitoring another dashboard, but are actually given actionable plans for remediating the data vulnerabilities, and shrinking the data attack surface.
The data attack surface might be a relatively new concept, but it’s based on principles security teams are well aware of: limiting exposure by eliminating attack vectors. When it comes to the cloud, the most important way to accomplish this is by focusing on the data first. With a smaller data attack surface, the less likely it is that valuable company data will be compromised.
Finding Sensitive Cloud Data in all the Wrong Places
Finding Sensitive Cloud Data in all the Wrong Places
Not all data can be kept under lock and key. Website resources, for example, always need to be public and S3 buckets are frequently used for this. On the other side, there are things that should never be public - customer information, payroll records, and company IP. But it happens - and can take months or years to notice - if you do at all.
This is the story of how Sentra identified a large enterprise’s source code in an open S3 bucket.
As part of work with this company, Sentra was given 7 Petabytes in AWS environments to scan for sensitive data. Specifically, we were looking for IP - source code, documentation, and other proprietary data.
As we often do, we discovered many issues, but really there were 7 that needed to be remediated immediately, 7 that we defined as ‘critical’.
The most severe data vulnerability was source code in an open S3 bucket with 7.5 TB worth of data. This file was hiding in a 600 MB .zip file in another .zip file. We also found recordings of client meetings and a tiny 8.9KB excel file with all of their existing current and potential customer data.

Examples of sensitive data alerts displayed on Sentra's dashboard
So how did such a serious data vulnerability go unnoticed? In this specific case, one of the principal architects at the company had backed up his primary device to their cloud. This isn’t as uncommon as you might think - particularly in the early days of cloud based companies, data is frequently ‘dumped’ into the cloud as the founders and developers are naturally more concerned about speed than security. There’s no CISO on board to build policies. Everyone is just trusted with the data that they have. The early Facebook motto of ‘move fast and break things’ is very much alive in early stage companies. Of course, if they’re successful at building a major company, the problem is now there’s all this data traveling around their cloud environment that no one is tracking, no one is responsible for, and in the case above, no one even knew existed.
Another explanation for unsecured sensitive data in the public cloud is that some people simply assume that the cloud is secure. As we’ve explained previously - the cloud can be more secure than on-prem architecture - but only if it’s configured properly. A major misconception is that everything in the cloud is secured by the cloud provider. Of course, the mere fact that you can host public resources on the cloud demonstrates how incorrect that assumption is - if you’ve left your S3 buckets open, that data is at risk, regardless of how much security the cloud provider offers. It’s important to remember that the ‘shared model of responsibility’ means that the cloud provider handles things like networking and physical security. But data security is on you.
This is where accurate data classification needs to play a role. Enterprises need a way of identifying which data is sensitive and critical to keep secure, and what the proper security posture should be. Data classification tools have been around for a long time, but mainly focus on easily identifiable data - credit card and social security numbers for example. Identifying company secrets that weren’t supposed to be publicly accessible wasn’t possible.
The rise of Data Security Posture Management platforms is changing that. By understanding what the security posture of data is supposed to be. By having the security posture ‘follow’ the sensitive data as it travels through the cloud, security teams can ensure their data is always properly secured - no matter where the data ends up.
Want to find out what sensitive data is publicly accessible in your cloud?
Get in touch with Sentra here to see our DSPM in action.
Why It’s Time to Adopt a Data Centric Approach to Security
Why It’s Time to Adopt a Data Centric Approach to Security
Here’s the typical response to a major data leak: There’s a breach at a large company. And the response from the security community is usually to invest more resources in preventing all possible data breaches. This might entail new DLP tools or infrastructure vulnerability management solutions.
But there’s something missing in this response.
The reason the breach was so catastrophic was because the data that leaked was valuable. It’s not the “network” that’s being leaked.
So that’s not where data centric security should start.
Here’s what the future of data breaches could look like: There’s a breach. But the breach doesn’t affect critical company or customer data because that data all has the proper security posture. There’s no press. And everyone goes home calmly at the end of the day.
This is going to be the future of most data breaches.
It’s just more attainable to secure specific data stores and files than it is to throw up defenses “around” the infrastructure. The truth this that most data stores do not contain sensitive information. So if we can just keep sensitive data in a small number of secured data stores, enterprises will be much more secure. Focusing on the data is a better way to prepare for a compromised environment.
Practical Steps for Achieving Data Centric Security
What does it take to make this a reality? Organizations need a way to find, classify, and remediate all data vulnerabilities. Here are the 5 steps to adopting a data centric security approach:
- Discover shadow data and build a data asset inventory.
You can’t protect what you don’t know you have. This is true of all organizations, but especially cloud first organizations. Cloud architectures make it easy to replicate or move data from one environment or another. It could be something as simple as a developer moving a data table to a staging environment, or a data analyst copying a file to use elsewhere. Regardless of how the shadow data is created, finding it needs to be priority number one.
- Classifying the most sensitive and critical data
Many organizations already use data tagging to classify their data. While this often works well for structured data like credit card numbers, it’s important to remember that ‘sensitive data’ includes unstructured data as well. This includes company secrets like source code and intellectual property which cause as much damage as customer data in the event of a breach.
- Prioritize data security according to business impact
The reason we’re investing time in finding and classifying all of this data is for the simple reason that some types of data matter more than others. We can’t afford to be data agnostic - we should be remediating vulnerabilities based on the severity of the data at risk, not the technical severity of the alert. Differentiating between the signal and the noise is critical for data security. Ignore the severity rating of the infrastructure vulnerabilities if there’s no sensitive data at risk.
- Continuously monitor data access and user activity, and make all employees accountable for their data – this is not only the security team’s problem.
Data is extremely valuable company property. When you give employees physical company property - like a laptop or even a car- they know they’re responsible for it. But when it comes to data, too many employees see themselves as mere users of the data. This attitude needs to change. Data isn’t the security team’s sole responsibility.
- Shrink the data attack surface - take action to reduce the organization’s data sprawl.
Beyond remediating according to business impact, organizations should reduce the number of sensitive data stores by removing sensitive data that don't need to have it. This can be via redaction, anonymization, encryption, etc. By limiting the number of sensitive data stores, security teams effectively shrink the attack surface by reducing the number of assets worth attacking in the first place.
The most important aspect is understanding that data travels and its security posture must travel with it. If a sensitive data asset has a strict security posture in one location in the public cloud, it must always maintain that posture. A Social Security number is always valuable to a threat actor. It doesn’t matter whether it leaks from a secured production environment or a forgotten data store that no one has accessed for two years. Only by appreciating this context will organizations be able to ensure that their sensitive data is always secured properly.
How Data Security Posture Management Helps
The biggest technological obstacles that had to be overcome to make data centric security possible were proper classification of unstructured data and prioritization based on business impact. Advances in Machine Learning have made highly accurate classification and prioritization possible, and created a new type of security solution: Data Security Posture Management (DSPM).
DSPM allows organizations to accurately find and classify their cloud data while offering remediation plans for severe vulnerabilities. By finally giving enterprises a full view of their cloud data, data centric security is finally able to offer a deeper, more effective layer of cloud security than ever before.
Want to see what data centric security looks like with Sentra’s DSPM? Request a demo here